LLMs cannot find reasoning errors, but can correct them given the error location
2311.08516
239
0
🤯
Abstract
While self-correction has shown promise in improving LLM outputs in terms of style and quality (e.g. Chen et al., 2023b; Madaan et al., 2023), recent attempts to self-correct logical or reasoning errors often cause correct answers to become incorrect, resulting in worse performances overall (Huang et al., 2023). In this paper, we show that poor self-correction performance stems from LLMs' inability to find logical mistakes, rather than their ability to correct a known mistake. Firstly, we benchmark several state-of-the-art LLMs on their mistake-finding ability and demonstrate that they generally struggle with the task, even in highly objective, unambiguous cases. Secondly, we test the correction abilities of LLMs -- separately from mistake finding -- using a backtracking setup that feeds ground truth mistake location information to the model. We show that this boosts downstream task performance across our 5 reasoning tasks, indicating that LLMs' correction abilities are robust. Finally, we show that it is possible to obtain mistake location information without ground truth labels or in-domain training data. We train a small classifier with out-of-domain data, which exhibits stronger mistake-finding performance than prompting a large model. We release our dataset of LLM-generated logical mistakes, BIG-Bench Mistake, to enable further research into locating LLM reasoning mistakes.
Create account to get full access
Overview
- Recent attempts to have large language models (LLMs) self-correct logical or reasoning errors often result in worse overall performance, even when the models can correct known mistakes.
- The authors show that this poor self-correction performance stems from LLMs' inability to find logical mistakes, rather than their ability to correct known mistakes.
- The authors benchmark several state-of-the-art LLMs on their mistake-finding ability and find they generally struggle, even with highly objective and unambiguous cases.
- The authors show that when provided with ground truth mistake location information, LLMs' correction abilities are robust, boosting downstream task performance.
- The authors demonstrate that it's possible to obtain mistake location information without ground truth labels or in-domain training data by training a small classifier with out-of-domain data, which outperforms prompting a large model.
- The authors release a dataset of LLM-generated logical mistakes, BIG-Bench Mistake, to enable further research into locating LLM reasoning mistakes.
Plain English Explanation
Large language models (LLMs) have shown promise in improving the style and quality of their outputs through self-correction. However, recent attempts to have LLMs self-correct logical or reasoning errors often result in the models providing worse overall performance, even when they are able to correct known mistakes.
The researchers behind this study found that the main reason for this poor self-correction performance is that LLMs struggle to actually identify logical mistakes in the first place, rather than an issue with their ability to correct known mistakes.
To demonstrate this, the researchers benchmarked several state-of-the-art LLMs on their ability to find logical mistakes, and found that the models generally struggled with this task, even when the mistakes were highly objective and unambiguous.
However, the researchers also found that when they provided the LLMs with the ground truth location of the mistakes, the models' correction abilities were quite robust, boosting their downstream task performance across a range of reasoning tasks.
This suggests that the key challenge is not with the LLMs' correction abilities, but rather with their inability to reliably identify logical mistakes in the first place.
Interestingly, the researchers also showed that it is possible to obtain mistake location information without ground truth labels or in-domain training data. By training a small classifier with out-of-domain data, they were able to outperform prompting a large model at the task of finding logical mistakes.
Overall, this research highlights the importance of developing effective "verifier" models that can reliably identify logical mistakes in LLM outputs, in order to unlock the full potential of self-correction techniques. The researchers have also released a dataset of LLM-generated logical mistakes to support further research in this area.
Technical Explanation
The paper first establishes that while self-correction has shown promise in improving LLM outputs in terms of style and quality, recent attempts to self-correct logical or reasoning errors often cause correct answers to become incorrect, resulting in worse performances overall.
To understand the root cause of this issue, the authors benchmarked several state-of-the-art LLMs on their mistake-finding ability. They demonstrate that the models generally struggle with this task, even in highly objective, unambiguous cases.
Next, the authors tested the correction abilities of LLMs, separately from mistake finding, using a backtracking setup that feeds ground truth mistake location information to the model. They show that this boosts downstream task performance across their 5 reasoning tasks, indicating that LLMs' correction abilities are robust.
Finally, the authors show that it is possible to obtain mistake location information without ground truth labels or in-domain training data. They train a small classifier with out-of-domain data, which exhibits stronger mistake-finding performance than prompting a large model.
To enable further research in this area, the authors release their dataset of LLM-generated logical mistakes, called BIG-Bench Mistake.
Critical Analysis
The paper provides a thorough and well-designed investigation into the challenges around LLM self-correction, particularly when it comes to logical and reasoning errors. The authors' finding that the key issue lies in LLMs' inability to reliably identify mistakes, rather than their correction capabilities, is an important insight that could help shape future research directions.
One potential limitation of the study is the relatively narrow scope of the reasoning tasks used to evaluate the models. While the authors did test across 5 different tasks, these may not capture the full breadth of reasoning and logical capabilities required in real-world applications. It would be interesting to see how the models perform on a more diverse set of reasoning challenges.
Additionally, the authors' approach of training a small classifier to locate mistakes using out-of-domain data is intriguing, but more work may be needed to understand the generalizability and scalability of this technique. It's possible that the performance advantage over prompting a large model could diminish as the reasoning tasks become more complex or varied.
Overall, this paper makes a valuable contribution to the ongoing efforts to improve the reliability and robustness of LLM outputs. By highlighting the importance of effective "verifier" models and providing a dataset to support further research, the authors have laid the groundwork for important future work in this area.
Conclusion
This research demonstrates that the key challenge in enabling effective self-correction of logical and reasoning errors in large language models is not with the models' correction capabilities, but rather with their ability to reliably identify mistakes in the first place.
The authors' benchmarking of state-of-the-art LLMs reveals that these models generally struggle to find logical mistakes, even in highly objective and unambiguous cases. However, when provided with the ground truth location of mistakes, the authors show that the models' correction abilities are quite robust, leading to significant performance improvements.
Importantly, the researchers also show that it is possible to obtain mistake location information without ground truth labels or in-domain training data, by training a small classifier on out-of-domain data. This suggests that developing effective "verifier" models could be a promising path forward for unlocking the full potential of self-correction techniques in large language models.
The release of the BIG-Bench Mistake dataset will undoubtedly spur further research in this critical area, as the community works to build more reliable and trustworthy language AI systems. By addressing the fundamental challenge of mistake identification, this work represents an important step towards more robust and capable large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
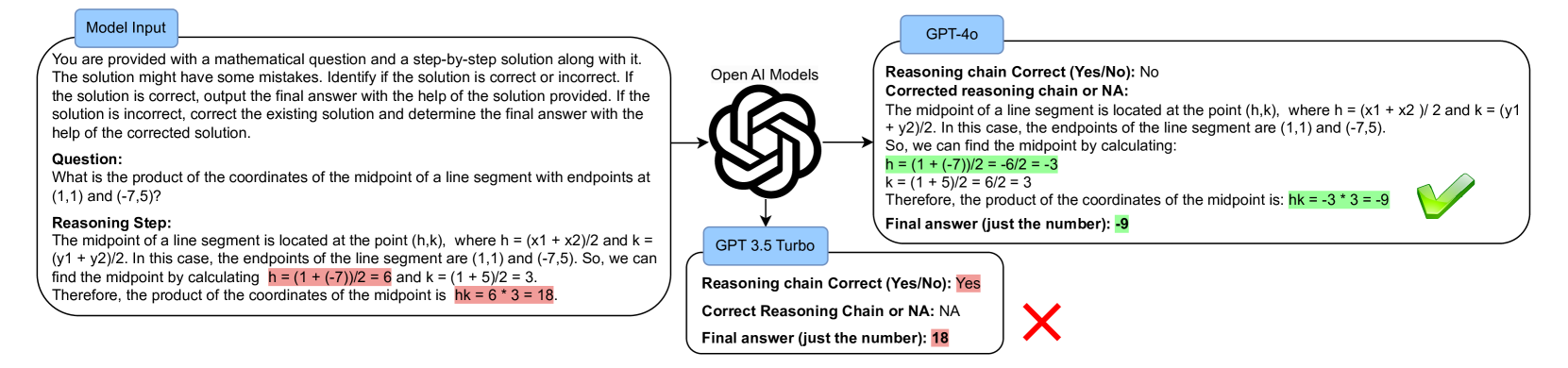
Exposing the Achilles' Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical Reasoning
Joykirat Singh, Akshay Nambi, Vibhav Vineet
0
0
Large Language Models (LLMs) have been applied to Math Word Problems (MWPs) with transformative impacts, revolutionizing how these complex problems are approached and solved in various domains including educational settings. However, the evaluation of these models often prioritizes final accuracy, overlooking the crucial aspect of reasoning capabilities. This work addresses this gap by focusing on the ability of LLMs to detect and correct reasoning mistakes. We introduce a novel dataset MWP-MISTAKE, incorporating MWPs with both correct and incorrect reasoning steps generated through rule-based methods and smaller language models. Our comprehensive benchmarking reveals significant insights into the strengths and weaknesses of state-of-the-art models, such as GPT-4o, GPT-4, GPT-3.5Turbo, and others. We highlight GPT-$o's superior performance in mistake detection and rectification and the persistent challenges faced by smaller models. Additionally, we identify issues related to data contamination and memorization, impacting the reliability of LLMs in real-world applications. Our findings emphasize the importance of rigorous evaluation of reasoning processes and propose future directions to enhance the generalization and robustness of LLMs in mathematical problem-solving.
6/18/2024
💬
Small Language Models Need Strong Verifiers to Self-Correct Reasoning
Yunxiang Zhang, Muhammad Khalifa, Lajanugen Logeswaran, Jaekyeom Kim, Moontae Lee, Honglak Lee, Lu Wang
0
0
Self-correction has emerged as a promising solution to boost the reasoning performance of large language models (LLMs), where LLMs refine their solutions using self-generated critiques that pinpoint the errors. This work explores whether small (<= 13B) language models (LMs) have the ability of self-correction on reasoning tasks with minimal inputs from stronger LMs. We propose a novel pipeline that prompts smaller LMs to collect self-correction data that supports the training of self-refinement abilities. First, we leverage correct solutions to guide the model in critiquing their incorrect responses. Second, the generated critiques, after filtering, are used for supervised fine-tuning of the self-correcting reasoner through solution refinement. Our experimental results show improved self-correction abilities of two models on five datasets spanning math and commonsense reasoning, with notable performance gains when paired with a strong GPT-4-based verifier, though limitations are identified when using a weak self-verifier for determining when to correct.
6/7/2024
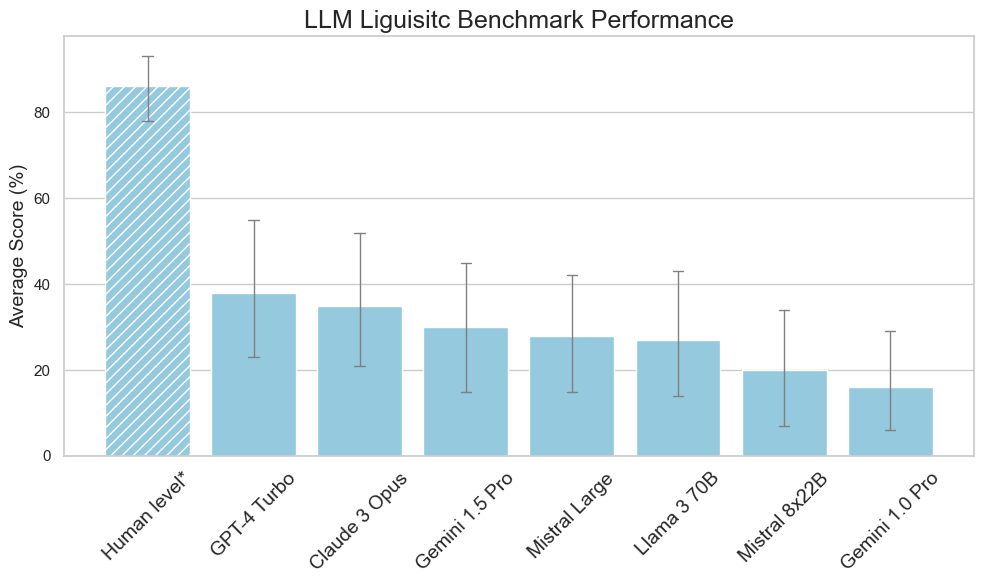
Easy Problems That LLMs Get Wrong
Sean Williams, James Huckle
0
0
We introduce a comprehensive Linguistic Benchmark designed to evaluate the limitations of Large Language Models (LLMs) in domains such as logical reasoning, spatial intelligence, and linguistic understanding, among others. Through a series of straightforward questions, it uncovers the significant limitations of well-regarded models to perform tasks that humans manage with ease. It also highlights the potential of prompt engineering to mitigate some errors and underscores the necessity for better training methodologies. Our findings stress the importance of grounding LLMs with human reasoning and common sense, emphasising the need for human-in-the-loop for enterprise applications. We hope this work paves the way for future research to enhance the usefulness and reliability of new models.
6/4/2024
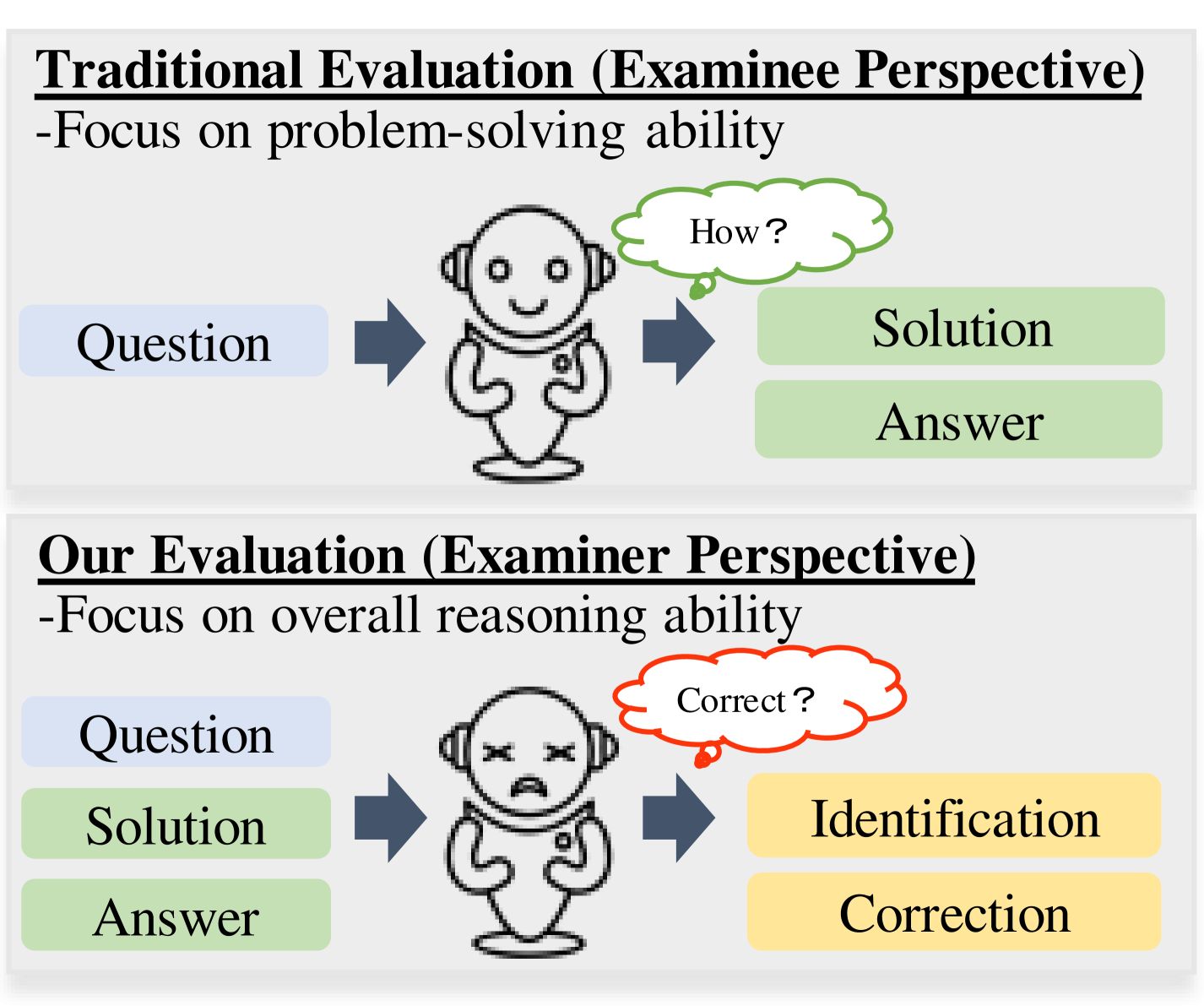
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
0
0
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
6/4/2024