Learning From Mistakes Makes LLM Better Reasoner
2310.20689
0
0
📈
Abstract
Large language models (LLMs) recently exhibited remarkable reasoning capabilities on solving math problems. To further improve their reasoning capabilities, this work explores whether LLMs can LEarn from MistAkes (LEMA), akin to the human learning process. Consider a human student who failed to solve a math problem, he will learn from what mistake he has made and how to correct it. Mimicking this error-driven learning process, LEMA incorporates mistake-correction data pairs during fine-tuning LLMs. Specifically, we first collect inaccurate reasoning paths from various LLMs, and then employ GPT-4 as a ''corrector'' to identify the mistake step, explain the reason for the mistake, correct the mistake and generate the final answer. In addition, we apply a correction-centric evolution strategy that effectively expands the question set for generating correction data. Experiments across various LLMs and reasoning tasks show that LEMA effectively improves CoT-alone fine-tuning. Our further ablations shed light on the non-homogeneous effectiveness between CoT data and correction data. These results suggest a significant potential for LLMs to improve through learning from their mistakes. Our code, models and prompts are publicly available at https://github.com/microsoft/LEMA.
Create account to get full access
Overview
- Large language models (LLMs) have shown impressive reasoning capabilities on math problems.
- This research explores whether LLMs can learn from their mistakes, similar to how humans learn.
- The proposed approach, called LEMA, incorporates mistake-correction data pairs during LLM fine-tuning.
- LEMA involves collecting inaccurate reasoning paths from LLMs, and then using GPT-4 to identify, explain, and correct the mistakes.
- An evolution strategy is applied to effectively expand the question set for generating correction data.
- Experiments demonstrate that LEMA can improve upon fine-tuning with Chains of Thought (CoT) data alone.
Plain English Explanation
Large language models like GPT-3 have amazed researchers with their ability to solve complex math problems. However, these models don't learn in the same way humans do - by identifying and learning from their mistakes.
Imagine a student who struggles with a math problem. After failing to solve it, the student analyzes where they went wrong, learns from that mistake, and tries again. This error-driven learning process is a key part of how humans improve their skills over time.
The researchers behind this paper wanted to see if they could teach large language models to learn in a similar way. They developed an approach called LEMA, which stands for "Learn from Mistakes." The idea is to provide the language model with examples of its own mistakes, along with corrections and explanations of where it went wrong.
To do this, the researchers first collected examples of inaccurate reasoning from various language models. They then used a more advanced model, GPT-4, to analyze these mistakes, explain what caused them, and provide the correct solutions. This correction data was then used to fine-tune the original language models, allowing them to learn from their errors.
The researchers found that this approach was effective at improving the models' reasoning capabilities, beyond what could be achieved through standard fine-tuning alone. By mimicking the human learning process of identifying and learning from mistakes, LEMA helped the language models become better problem solvers.
Technical Explanation
The core idea behind LEMA is to explicitly incorporate mistake-correction data pairs during the fine-tuning process of large language models. The researchers first collected inaccurate reasoning paths from various LLMs on a range of reasoning tasks. They then used GPT-4 as a "corrector" to identify the mistake step, explain the reason for the mistake, correct the mistake, and generate the final correct answer.
In addition, the researchers applied a correction-centric evolution strategy to effectively expand the question set for generating more correction data. This involved iteratively modifying the original questions to introduce new mistakes, and then using GPT-4 to provide the corrections.
The researchers evaluated LEMA across multiple LLMs and reasoning tasks, and found that it outperformed fine-tuning with Chains of Thought (CoT) data alone. Further analysis revealed that the correction data and CoT data had different, non-homogeneous impacts on the models' performance, suggesting that the two types of data provide complementary benefits.
Critical Analysis
The paper provides a compelling approach for improving the reasoning capabilities of large language models by teaching them to learn from their mistakes. The LEMA method is well-designed and the experimental results are promising.
That said, the paper does not delve into potential limitations or caveats of the approach. For example, it's unclear how scalable the process of generating correction data using GPT-4 would be, especially as the language models become larger and more complex. The computational and resource requirements of this process could limit the practicality of LEMA in certain scenarios.
Additionally, the paper does not address potential biases or inconsistencies that could arise in the correction data. If the GPT-4 "corrector" itself has biases or makes mistakes, those errors could be propagated during the fine-tuning process.
Further research could explore ways to automate the correction data generation process, or to validate the accuracy and consistency of the corrections. Exploring the generalization of LEMA to other reasoning domains beyond mathematics would also be an interesting direction.
Conclusion
This research represents an important step towards improving the reasoning capabilities of large language models by teaching them to learn from their mistakes, similar to how humans learn. The LEMA approach effectively incorporates mistake-correction data during fine-tuning, leading to tangible improvements in the models' problem-solving abilities.
While the paper does not address all the potential limitations of the method, it still highlights the significant potential for LLMs to improve through error-driven learning. As language models continue to become more powerful and ubiquitous, developing techniques like LEMA will be crucial for ensuring they can reliably and robustly tackle complex reasoning tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Can LLMs Learn from Previous Mistakes? Investigating LLMs' Errors to Boost for Reasoning
Yongqi Tong, Dawei Li, Sizhe Wang, Yujia Wang, Fei Teng, Jingbo Shang
0
0
Recent works have shown the benefits to LLMs from fine-tuning golden-standard Chain-of-Thought (CoT) rationales or using them as correct examples in few-shot prompting. While humans can indeed imitate correct examples, learning from our mistakes is another vital aspect of human cognition. Hence, a question naturally arises: textit{can LLMs learn and benefit from their mistakes, especially for their reasoning? } This study investigates this problem from both the prompting and model-tuning perspectives. We begin by introducing textsc{CoTErrorSet}, a new benchmark with 609,432 questions, each designed with both correct and error references, and demonstrating the types and reasons for making such mistakes. To explore the effectiveness of those mistakes, we design two methods: (1) textbf{Self-rethinking} prompting guides LLMs to rethink whether they have made similar previous mistakes; and (2) textbf{Mistake tuning} involves finetuning models in both correct and incorrect reasoning domains, rather than only tuning models to learn ground truth in traditional methodology. We conduct a series of experiments to prove LLMs can obtain benefits from mistakes in both directions. Our two methods offer potentially cost-effective strategies by leveraging errors to enhance reasoning capabilities, which costs significantly less than creating meticulously hand-crafted golden references. We ultimately make a thorough analysis of the reasons behind LLMs' errors, which provides directions that future research needs to overcome. textsc{CoTErrorSet} will be published soon on texttt{url{https://github.com/YookiTong/Learn-from-Mistakes-CotErrorSet}}.
6/10/2024
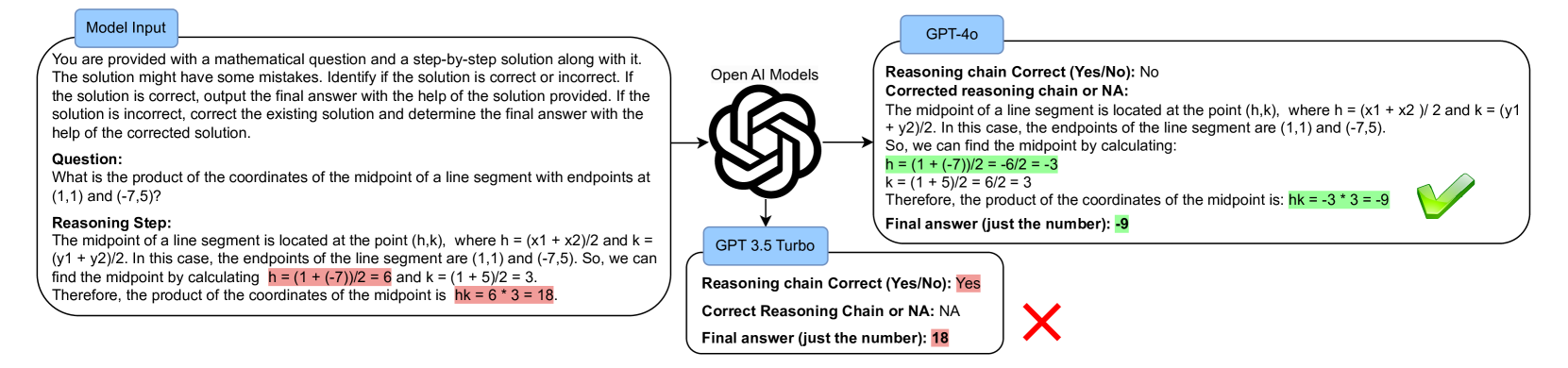
Exposing the Achilles' Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical Reasoning
Joykirat Singh, Akshay Nambi, Vibhav Vineet
0
0
Large Language Models (LLMs) have been applied to Math Word Problems (MWPs) with transformative impacts, revolutionizing how these complex problems are approached and solved in various domains including educational settings. However, the evaluation of these models often prioritizes final accuracy, overlooking the crucial aspect of reasoning capabilities. This work addresses this gap by focusing on the ability of LLMs to detect and correct reasoning mistakes. We introduce a novel dataset MWP-MISTAKE, incorporating MWPs with both correct and incorrect reasoning steps generated through rule-based methods and smaller language models. Our comprehensive benchmarking reveals significant insights into the strengths and weaknesses of state-of-the-art models, such as GPT-4o, GPT-4, GPT-3.5Turbo, and others. We highlight GPT-$o's superior performance in mistake detection and rectification and the persistent challenges faced by smaller models. Additionally, we identify issues related to data contamination and memorization, impacting the reliability of LLMs in real-world applications. Our findings emphasize the importance of rigorous evaluation of reasoning processes and propose future directions to enhance the generalization and robustness of LLMs in mathematical problem-solving.
6/18/2024
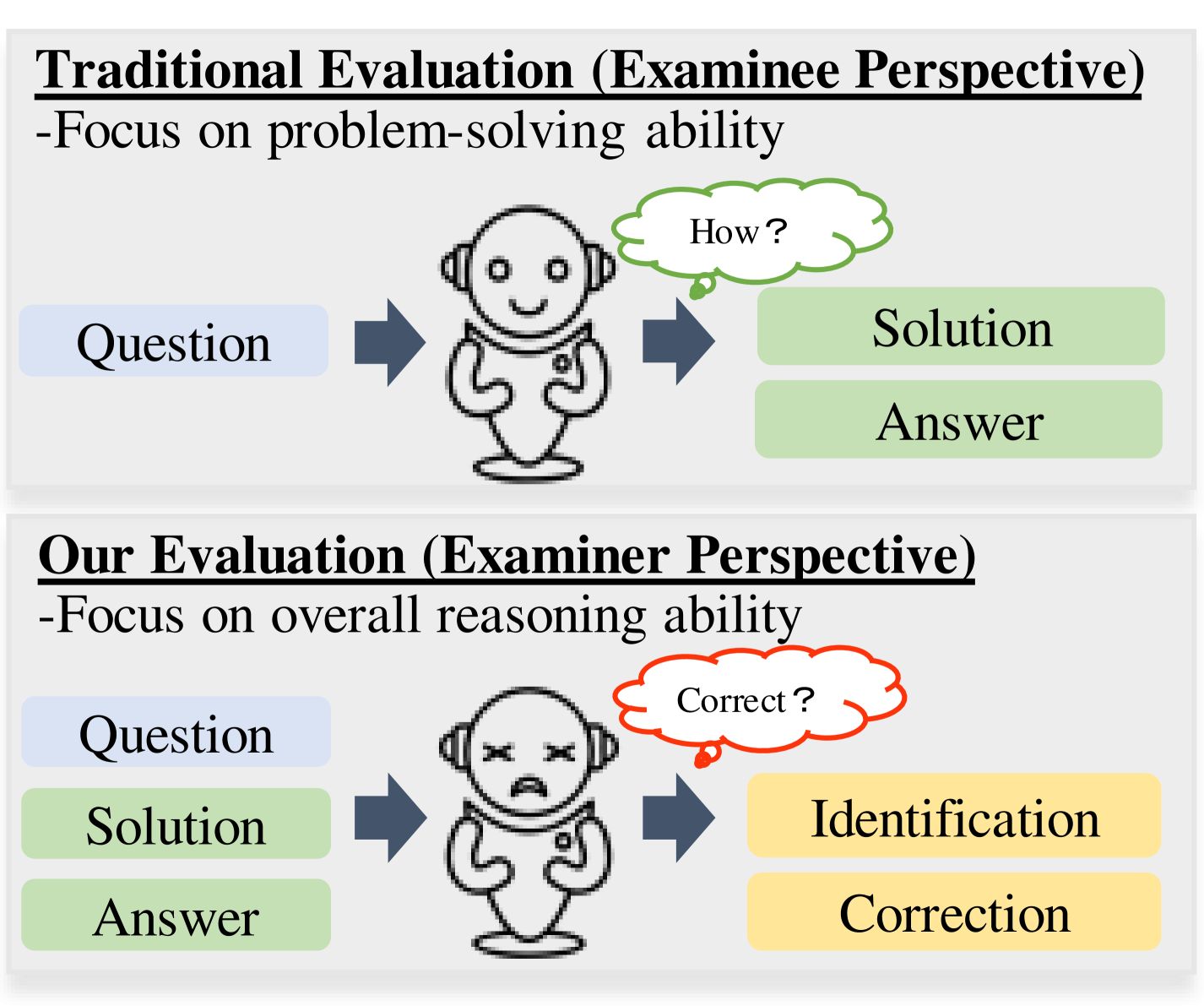
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
0
0
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
6/4/2024
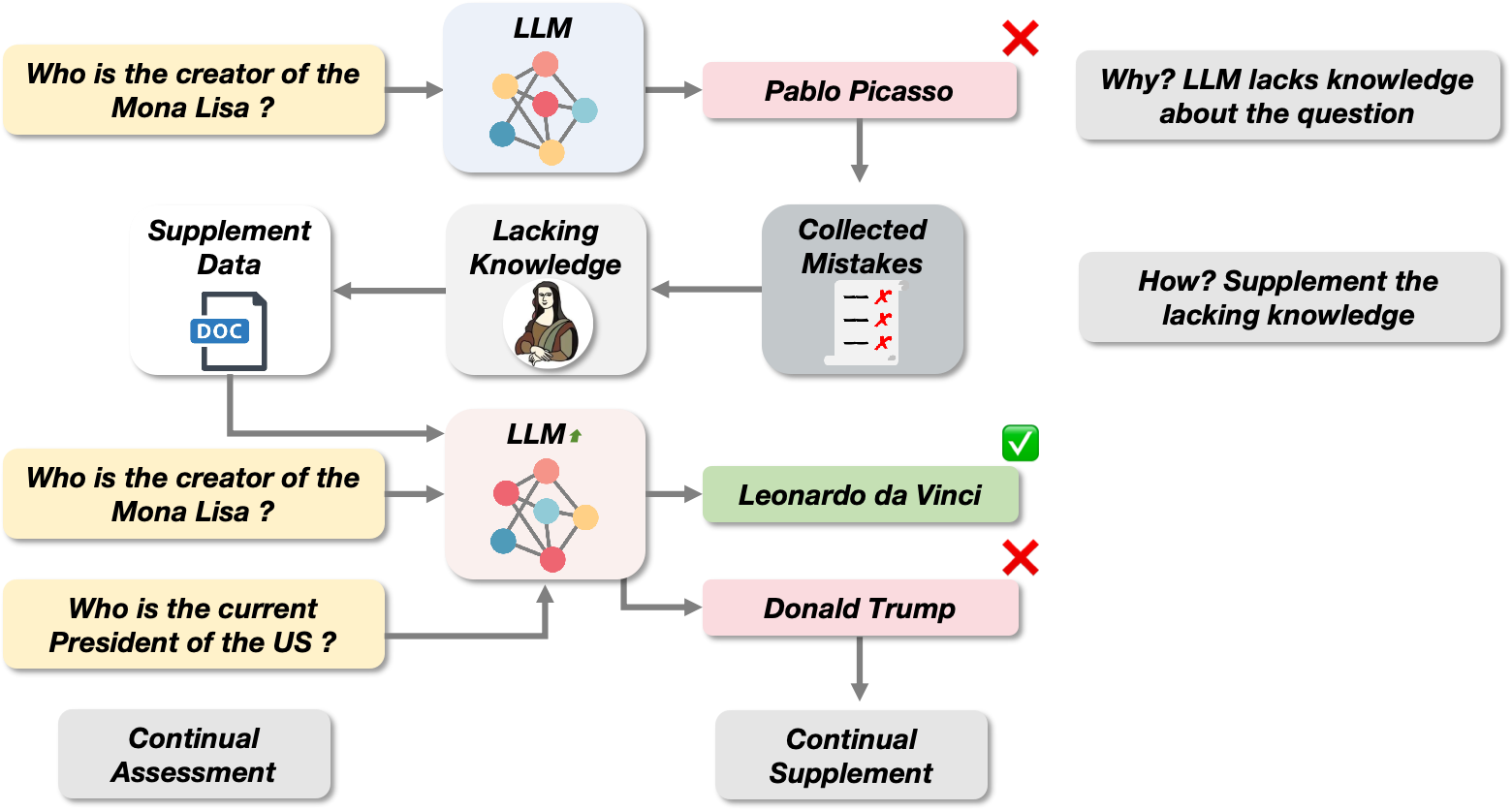
Large Language Model Can Continue Evolving From Mistakes
Haokun Zhao, Haixia Han, Jie Shi, Chengyu Du, Jiaqing Liang, Yanghua Xiao
0
0
As world knowledge evolves and new task paradigms emerge, Continual Learning (CL) is crucial for keeping Large Language Models (LLMs) up-to-date and addressing their shortcomings. In practical applications, LLMs often require both continual instruction tuning (CIT) and continual pre-training (CPT) to adapt to new task paradigms and acquire necessary knowledge for task-solving. However, it remains challenging to collect CPT data that addresses the knowledge deficiencies in models while maintaining adequate volume, and improving the efficiency of utilizing this data also presents significant difficulties. Inspired by the 'summarizing mistakes' learning skill, we propose the Continue Evolving from Mistakes (CEM) method, aiming to provide a data-efficient approach for collecting CPT data and continually improving LLMs' performance through iterative evaluation and supplementation with mistake-relevant knowledge. To efficiently utilize these CPT data and mitigate forgetting, we design a novel CL training set construction paradigm that integrates parallel CIT and CPT data. Extensive experiments demonstrate the efficacy of the CEM method, achieving up to a 17% improvement in accuracy in the best case. Furthermore, additional experiments confirm the potential of combining CEM with catastrophic forgetting mitigation methods, enabling iterative and continual model evolution.
6/18/2024