Can LLMs substitute SQL? Comparing Resource Utilization of Querying LLMs versus Traditional Relational Databases

0

Sign in to get full access
Overview
- This paper compares the resource utilization of querying large language models (LLMs) versus traditional relational databases.
- The authors investigate whether LLMs can substitute structured query language (SQL) for certain data retrieval tasks.
- The study examines the computational costs and performance tradeoffs between using LLMs and SQL-based databases.
Plain English Explanation
The paper explores whether large language models (LLMs) can be used instead of traditional database query languages like SQL for certain data retrieval tasks. LLMs are powerful AI models that can understand and generate human-like text. The researchers compare the computational resources required and performance tradeoffs between using LLMs versus SQL-based relational databases to access and retrieve data.
The key question the paper aims to address is whether LLMs can effectively substitute for SQL in some scenarios. This is an important consideration as LLMs become more advanced and widespread, as they may offer advantages in terms of flexibility and natural language interaction compared to rigid database query languages. Understanding the trade-offs in using LLMs versus databases can help guide when each approach may be most appropriate.
Technical Explanation
The paper first reviews prior work on using text-to-SQL techniques to leverage LLMs for database querying. It then presents an experimental setup to directly compare the computational resource utilization and performance of LLM-based data retrieval versus traditional SQL queries.
The authors deploy several popular LLMs, including GPT-3 and Chinchilla, and test them on a range of database retrieval tasks. They measure metrics like inference time, energy consumption, and memory usage, and compare the LLM results to equivalent SQL queries run on a relational database.
The results indicate that for simple, narrow queries, SQL outperforms LLMs in terms of resource efficiency. However, for more open-ended, natural language-style queries, the LLMs can be more computationally efficient. The paper discusses the trade-offs and highlights scenarios where LLMs may be a suitable substitute for SQL.
Critical Analysis
The paper provides a valuable empirical comparison of using LLMs versus traditional databases for data retrieval tasks. However, it acknowledges several limitations. The experiments are conducted on a relatively small database, and the analysis does not explore how performance might scale with larger or more complex datasets.
Additionally, the paper only evaluates a limited set of LLMs and database configurations. There may be opportunities to further optimize the LLM-based approach or leverage advancements in language model performance that could shift the efficiency trade-offs.
The paper also does not deeply explore the qualitative aspects of user experience and query expressivity when using LLMs versus SQL. These factors may be important considerations when assessing the suitability of each approach for real-world applications.
Conclusion
This paper presents a timely investigation into whether large language models can substitute for traditional SQL-based data retrieval in certain scenarios. The results suggest that LLMs may offer advantages in terms of computational efficiency for more open-ended, natural language-style queries, while SQL remains superior for simple, narrow database lookups.
As LLMs continue to advance and become more widely adopted, understanding these performance trade-offs will be crucial for developers and data scientists to determine the most appropriate tool for their specific data access needs. This research provides a helpful foundation for further exploration of the synergies and distinctions between LLM-based and SQL-based data querying approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can LLMs substitute SQL? Comparing Resource Utilization of Querying LLMs versus Traditional Relational Databases
Xiang Zhang, Khatoon Khedri, Reza Rawassizadeh
Large Language Models (LLMs) can automate or substitute different types of tasks in the software engineering process. This study evaluates the resource utilization and accuracy of LLM in interpreting and executing natural language queries against traditional SQL within relational database management systems. We empirically examine the resource utilization and accuracy of nine LLMs varying from 7 to 34 Billion parameters, including Llama2 7B, Llama2 13B, Mistral, Mixtral, Optimus-7B, SUS-chat-34B, platypus-yi-34b, NeuralHermes-2.5-Mistral-7B and Starling-LM-7B-alpha, using a small transaction dataset. Our findings indicate that using LLMs for database queries incurs significant energy overhead (even small and quantized models), making it an environmentally unfriendly approach. Therefore, we advise against replacing relational databases with LLMs due to their substantial resource utilization.
Read more4/16/2024
📊
0
Making LLMs Work for Enterprise Data Tasks
c{C}au{g}atay Demiralp, Fabian Wenz, Peter Baile Chen, Moe Kayali, Nesime Tatbul, Michael Stonebraker
Large language models (LLMs) know little about enterprise database tables in the private data ecosystem, which substantially differ from web text in structure and content. As LLMs' performance is tied to their training data, a crucial question is how useful they can be in improving enterprise database management and analysis tasks. To address this, we contribute experimental results on LLMs' performance for text-to-SQL and semantic column-type detection tasks on enterprise datasets. The performance of LLMs on enterprise data is significantly lower than on benchmark datasets commonly used. Informed by our findings and feedback from industry practitioners, we identify three fundamental challenges -- latency, cost, and quality -- and propose potential solutions to use LLMs in enterprise data workflows effectively.
Read more7/31/2024

0
LLM-SQL-Solver: Can LLMs Determine SQL Equivalence?
Fuheng Zhao, Lawrence Lim, Ishtiyaque Ahmad, Divyakant Agrawal, Amr El Abbadi
Judging the equivalence between two SQL queries is a fundamental problem with many practical applications in data management and SQL generation (i.e., evaluating the quality of generated SQL queries in text-to-SQL task). While the research community has reasoned about SQL equivalence for decades, it poses considerable difficulties and no complete solutions exist. Recently, Large Language Models (LLMs) have shown strong reasoning capability in conversation, question answering and solving mathematics challenges. In this paper, we study if LLMs can be used to determine the equivalence between SQL queries under two notions of SQL equivalence (semantic equivalence and relaxed equivalence). To assist LLMs in generating high quality responses, we present two prompting techniques: Miniature & Mull and Explain & Compare. The former technique is used to evaluate the semantic equivalence in which it asks LLMs to execute a query on a simple database instance and then explore if a counterexample exists by modifying the database. The latter technique is used to evaluate the relaxed equivalence in which it asks LLMs to explain the queries and then compare if they contain significant logical differences. Our experiments demonstrate using our techniques, LLMs is a promising tool to help data engineers in writing semantically equivalent SQL queries, however challenges still persist, and is a better metric for evaluating SQL generation than the popular execution accuracy.
Read more6/21/2024
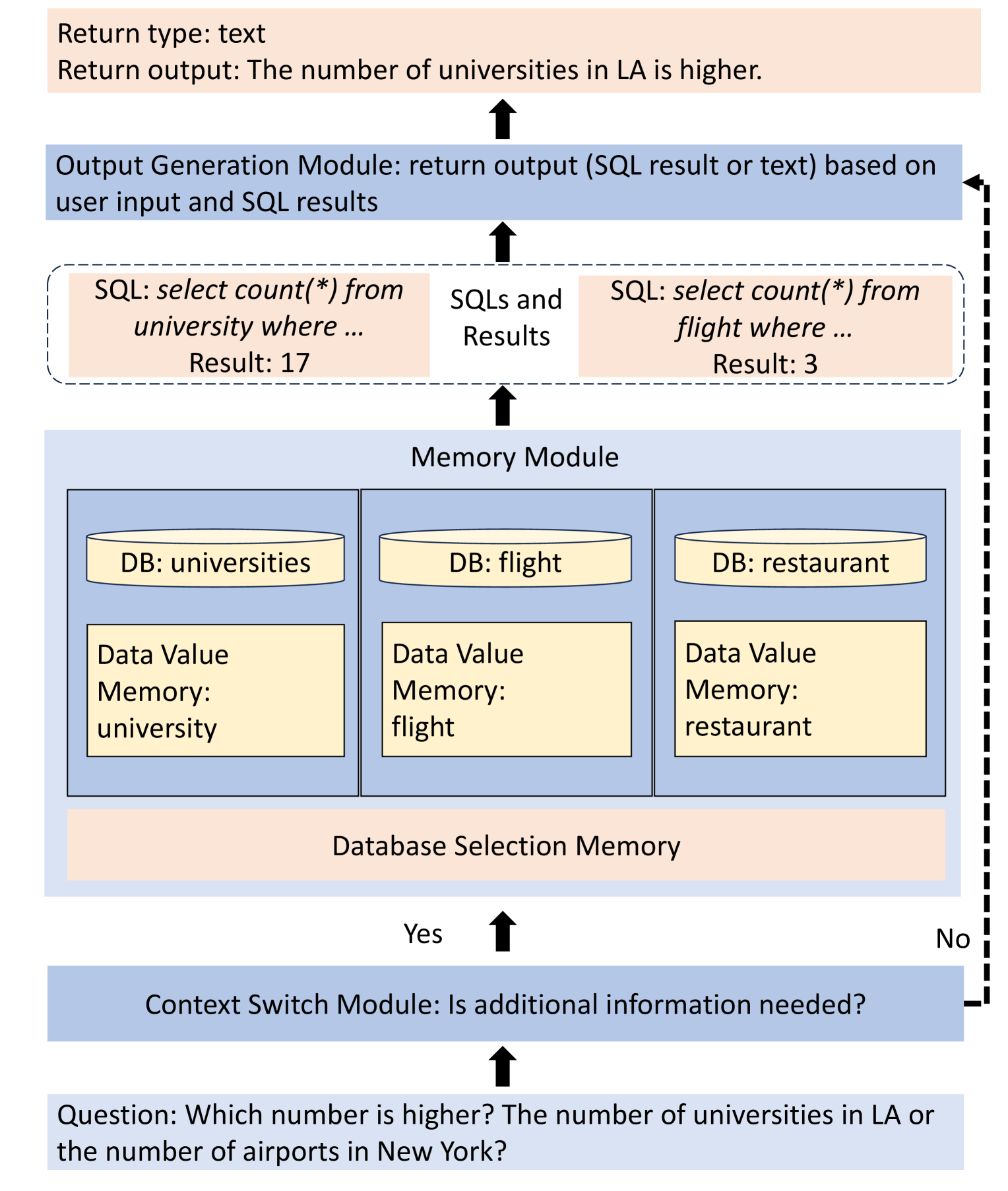
0
Relational Database Augmented Large Language Model
Zongyue Qin, Chen Luo, Zhengyang Wang, Haoming Jiang, Yizhou Sun
Large language models (LLMs) excel in many natural language processing (NLP) tasks. However, since LLMs can only incorporate new knowledge through training or supervised fine-tuning processes, they are unsuitable for applications that demand precise, up-to-date, and private information not available in the training corpora. This precise, up-to-date, and private information is typically stored in relational databases. Thus, a promising solution is to augment LLMs with the inclusion of relational databases as external memory. This can ensure the timeliness, correctness, and consistency of data, and assist LLMs in performing complex arithmetic operations beyond their inherent capabilities. However, bridging the gap between LLMs and relational databases is challenging. It requires the awareness of databases and data values stored in databases to select correct databases and issue correct SQL queries. Besides, it is necessary for the external memory to be independent of the LLM to meet the needs of real-world applications. We introduce a novel LLM-agnostic memory architecture comprising a database selection memory, a data value memory, and relational databases. And we design an elegant pipeline to retrieve information from it. Besides, we carefully design the prompts to instruct the LLM to maximize the framework's potential. To evaluate our method, we compose a new dataset with various types of questions. Experimental results show that our framework enables LLMs to effectively answer database-related questions, which is beyond their direct ability.
Read more7/23/2024