Relational Database Augmented Large Language Model

0
Sign in to get full access
Overview
- Presents a framework that combines a large language model (LLM) with a relational database to enhance the capabilities of the LLM.
- Aims to improve the LLM's performance on tasks that involve structured data, such as querying and manipulating databases.
- Explores the potential benefits and challenges of this approach.
Plain English Explanation
A Relational Database Augmented Large Language Model is a system that combines a powerful large language model (LLM) with a relational database. The goal is to take advantage of the LLM's natural language understanding capabilities and the database's structured data to create a more powerful and versatile system for tasks like querying and manipulating data.
The key idea is that the LLM can use its natural language skills to interact with the database, allowing users to ask questions and give commands in plain English rather than having to learn a specialized database query language like SQL. The database, in turn, can provide the LLM with structured data that it can use to improve its understanding and reasoning abilities.
This approach could be particularly useful in situations where people need to work with complex, structured data but don't have the technical expertise to use traditional database tools. By combining the strengths of LLMs and databases, the system aims to make it easier for users to access and make sense of large, diverse datasets.
Technical Explanation
The framework described in the paper consists of several key components:
- Large Language Model: This is a powerful machine learning model that has been trained on a vast amount of text data, giving it the ability to understand and generate natural language.
- Relational Database: This is a structured data storage system that organizes data into tables with rows and columns, allowing for efficient querying and manipulation.
- Database Interface: This component acts as a bridge between the LLM and the database, translating natural language requests into database queries and formatting the results for the LLM.
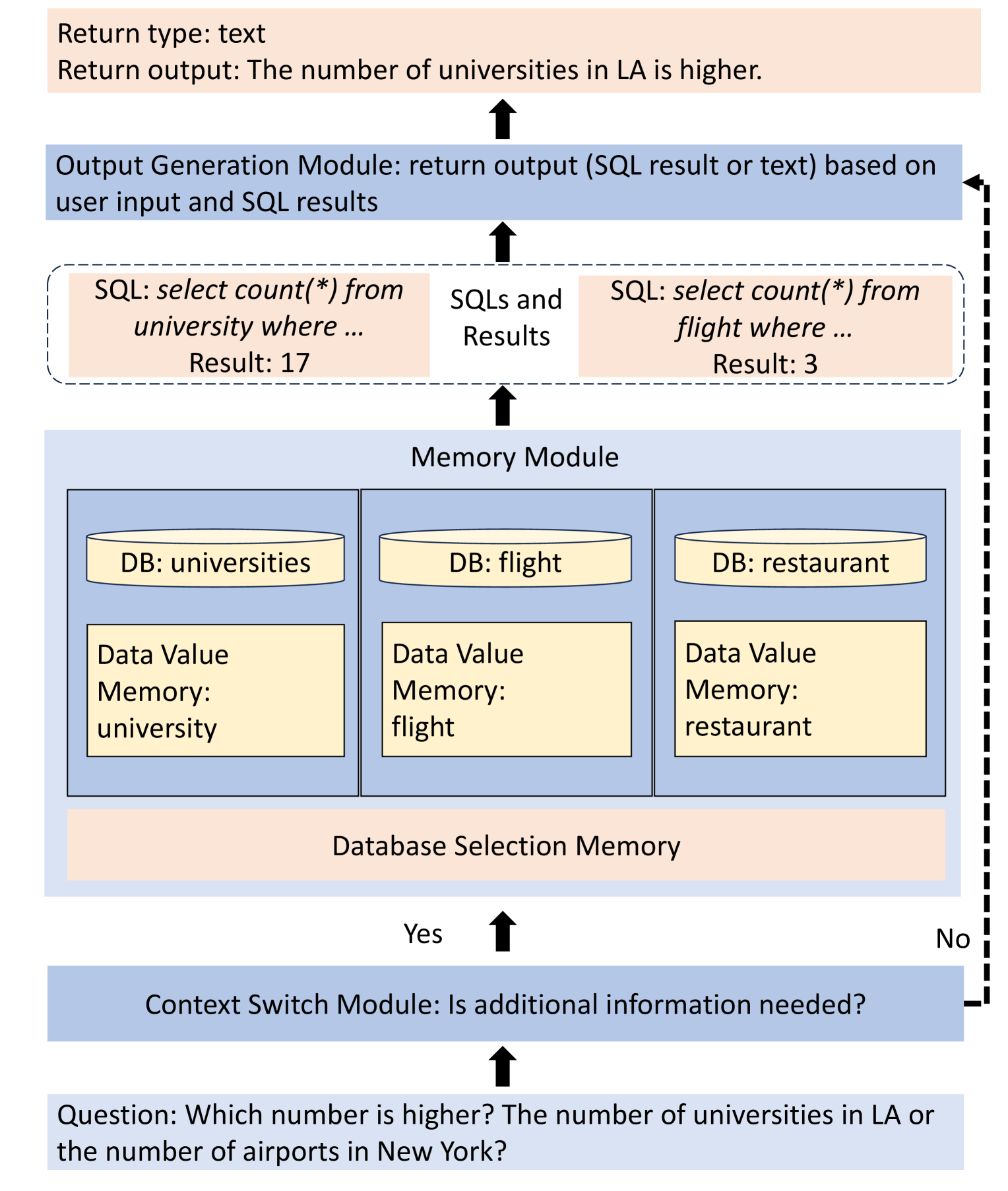
- Knowledge Base: This is a collection of information about the database schema, data types, and relationships, which the LLM can use to better understand and interact with the database.
The framework works by having the user interact with the LLM using natural language, such as asking questions or giving commands. The LLM then uses the database interface and knowledge base to translate these requests into database queries, execute them, and return the results to the user in a natural language format.
The researchers conducted experiments to evaluate the performance of this framework on tasks such as data retrieval, data manipulation, and natural language reasoning. They found that the combination of the LLM and database could outperform either component alone on certain tasks, demonstrating the potential benefits of this approach.
Critical Analysis
The paper presents a promising approach to combining LLMs and relational databases, but it also acknowledges several potential limitations and areas for further research:
- Scalability: The researchers note that as the size and complexity of the database grow, the performance of the system may degrade, and they suggest exploring ways to improve scalability.
- Generalization: The paper focuses on a specific set of tasks and database schemas, and it's unclear how well the framework would generalize to other types of databases or applications.
- Interpretability: The inner workings of the LLM-database interaction can be opaque, making it difficult to understand and debug the system's decision-making process.
- Security and Privacy: Integrating LLMs with sensitive data stored in databases raises concerns about data privacy and security, which the paper does not address in depth.
Additionally, while the paper demonstrates the potential benefits of this approach, it's important to consider the broader implications and potential challenges of using LLMs in this context, such as bias, fairness, and the ethical use of AI systems.
Conclusion
The Relational Database Augmented Large Language Model framework presented in this paper offers a promising approach to combining the strengths of LLMs and relational databases to create more powerful and user-friendly data management and analysis tools. By leveraging natural language understanding and structured data, this system has the potential to make complex data tasks more accessible to a wider range of users.
However, the research also highlights the need for further investigation into issues like scalability, generalization, interpretability, and the responsible development of such AI-powered data systems. As the use of LLMs continues to expand, it will be important to carefully consider the implications and address these challenges to ensure that these technologies are deployed in a safe and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Relational Database Augmented Large Language Model
Zongyue Qin, Chen Luo, Zhengyang Wang, Haoming Jiang, Yizhou Sun
Large language models (LLMs) excel in many natural language processing (NLP) tasks. However, since LLMs can only incorporate new knowledge through training or supervised fine-tuning processes, they are unsuitable for applications that demand precise, up-to-date, and private information not available in the training corpora. This precise, up-to-date, and private information is typically stored in relational databases. Thus, a promising solution is to augment LLMs with the inclusion of relational databases as external memory. This can ensure the timeliness, correctness, and consistency of data, and assist LLMs in performing complex arithmetic operations beyond their inherent capabilities. However, bridging the gap between LLMs and relational databases is challenging. It requires the awareness of databases and data values stored in databases to select correct databases and issue correct SQL queries. Besides, it is necessary for the external memory to be independent of the LLM to meet the needs of real-world applications. We introduce a novel LLM-agnostic memory architecture comprising a database selection memory, a data value memory, and relational databases. And we design an elegant pipeline to retrieve information from it. Besides, we carefully design the prompts to instruct the LLM to maximize the framework's potential. To evaluate our method, we compose a new dataset with various types of questions. Experimental results show that our framework enables LLMs to effectively answer database-related questions, which is beyond their direct ability.
Read more7/23/2024
📊
0
Making LLMs Work for Enterprise Data Tasks
c{C}au{g}atay Demiralp, Fabian Wenz, Peter Baile Chen, Moe Kayali, Nesime Tatbul, Michael Stonebraker
Large language models (LLMs) know little about enterprise database tables in the private data ecosystem, which substantially differ from web text in structure and content. As LLMs' performance is tied to their training data, a crucial question is how useful they can be in improving enterprise database management and analysis tasks. To address this, we contribute experimental results on LLMs' performance for text-to-SQL and semantic column-type detection tasks on enterprise datasets. The performance of LLMs on enterprise data is significantly lower than on benchmark datasets commonly used. Informed by our findings and feedback from industry practitioners, we identify three fundamental challenges -- latency, cost, and quality -- and propose potential solutions to use LLMs in enterprise data workflows effectively.
Read more7/31/2024

0
Can LLMs substitute SQL? Comparing Resource Utilization of Querying LLMs versus Traditional Relational Databases
Xiang Zhang, Khatoon Khedri, Reza Rawassizadeh
Large Language Models (LLMs) can automate or substitute different types of tasks in the software engineering process. This study evaluates the resource utilization and accuracy of LLM in interpreting and executing natural language queries against traditional SQL within relational database management systems. We empirically examine the resource utilization and accuracy of nine LLMs varying from 7 to 34 Billion parameters, including Llama2 7B, Llama2 13B, Mistral, Mixtral, Optimus-7B, SUS-chat-34B, platypus-yi-34b, NeuralHermes-2.5-Mistral-7B and Starling-LM-7B-alpha, using a small transaction dataset. Our findings indicate that using LLMs for database queries incurs significant energy overhead (even small and quantized models), making it an environmentally unfriendly approach. Therefore, we advise against replacing relational databases with LLMs due to their substantial resource utilization.
Read more4/16/2024
🤖
0
Lucy: Think and Reason to Solve Text-to-SQL
Nina Narodytska, Shay Vargaftik
Large Language Models (LLMs) have made significant progress in assisting users to query databases in natural language. While LLM-based techniques provide state-of-the-art results on many standard benchmarks, their performance significantly drops when applied to large enterprise databases. The reason is that these databases have a large number of tables with complex relationships that are challenging for LLMs to reason about. We analyze challenges that LLMs face in these settings and propose a new solution that combines the power of LLMs in understanding questions with automated reasoning techniques to handle complex database constraints. Based on these ideas, we have developed a new framework that outperforms state-of-the-art techniques in zero-shot text-to-SQL on complex benchmarks
Read more7/9/2024