Are Long-LLMs A Necessity For Long-Context Tasks?
2405.15318
0
0

Abstract
The learning and deployment of long-LLMs remains a challenging problem despite recent progresses. In this work, we argue that the long-LLMs are not a necessity to solve long-context tasks, as common long-context tasks are short-context solvable, i.e. they can be solved by purely working with oracle short-contexts within the long-context tasks' inputs. On top of this argument, we propose a framework called LC-Boost (Long-Context Bootstrapper), which enables a short-LLM to address the long-context tasks in a bootstrapping manner. In our framework, the short-LLM prompts itself to reason for two critical decisions: 1) how to access to the appropriate part of context within the input, 2) how to make effective use of the accessed context. By adaptively accessing and utilizing the context based on the presented tasks, LC-Boost can serve as a general framework to handle diversified long-context processing problems. We comprehensively evaluate different types of tasks from popular long-context benchmarks, where LC-Boost is able to achieve a substantially improved performance with a much smaller consumption of resource.
Create account to get full access
Overview
• The research paper examines the performance of long-context language models (long-LLMs) on tasks that require processing and understanding large amounts of information.
• It introduces a new model called LC-Boost, which aims to improve the ability of language models to learn from and utilize long-context information.
• The paper also discusses the limitations of current long-LLMs and explores alternative approaches to extending the context capabilities of language models.
Plain English Explanation
The research paper looks at whether long-LLMs - language models that can process long stretches of text - are truly necessary for tasks that require understanding large amounts of information. The researchers developed a new model called LC-Boost that tries to address the challenges long-LLMs face when it comes to learning from and using long-context information.
The paper also talks about the shortcomings of today's long-LLMs and explores different ways to extend the context capabilities of language models. For example, the researchers mention techniques like LLOCO that could help language models better utilize the context information they're given.
Overall, the research aims to understand whether long-LLMs are essential for tasks that involve processing large amounts of text, or if there are more efficient ways to tackle these "long-context" problems.
Technical Explanation
The paper introduces a new model called LC-Boost that combines a standard language model with an additional "boosting" mechanism to improve performance on long-context tasks. LC-Boost takes in a long input sequence and first encodes it using a standard transformer-based language model.
It then uses a specialized "boosting" module to selectively attend to and extract relevant information from different parts of the encoded context. This allows the model to focus on the most salient parts of the long input, rather than trying to remember and process the entire sequence.
The researchers evaluate LC-Boost on a variety of long-context benchmarks, including MILeBench, and compare its performance to state-of-the-art long-LLMs. The results suggest that LC-Boost can achieve competitive or even superior performance on these tasks, without requiring the massive model sizes and compute resources of traditional long-LLMs.
Critical Analysis
The paper provides a thoughtful exploration of the challenges and limitations of current long-LLMs for long-context tasks. The authors acknowledge that while long-LLMs can theoretically process large amounts of information, in practice they often struggle to effectively utilize all the available context.
The LC-Boost model represents a promising approach to address these issues, but the paper also highlights areas for further research. For example, the boosting mechanism used in LC-Boost may not be sufficient to fully capture all the relevant information in very long sequences. Techniques like make-your-llm-fully-utilize-context could potentially be integrated to further improve performance.
Additionally, the evaluation is limited to a specific set of benchmarks, and it would be valuable to see how LC-Boost and other approaches fare on a wider range of long-context tasks, including more open-ended and real-world applications.
Conclusion
The research paper makes a compelling case that long-LLMs may not be an absolute necessity for long-context tasks, and that alternative approaches like LC-Boost can offer competitive performance with greater efficiency. This suggests that there may be more effective ways to tackle the challenges of processing and understanding large amounts of information, beyond simply scaling up language models.
The insights and techniques discussed in this paper could have important implications for the development of more robust and practical language AI systems that can better leverage contextual information to solve complex, real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
New!Is It Really Long Context if All You Need Is Retrieval? Towards Genuinely Difficult Long Context NLP
Omer Goldman, Alon Jacovi, Aviv Slobodkin, Aviya Maimon, Ido Dagan, Reut Tsarfaty
0
0
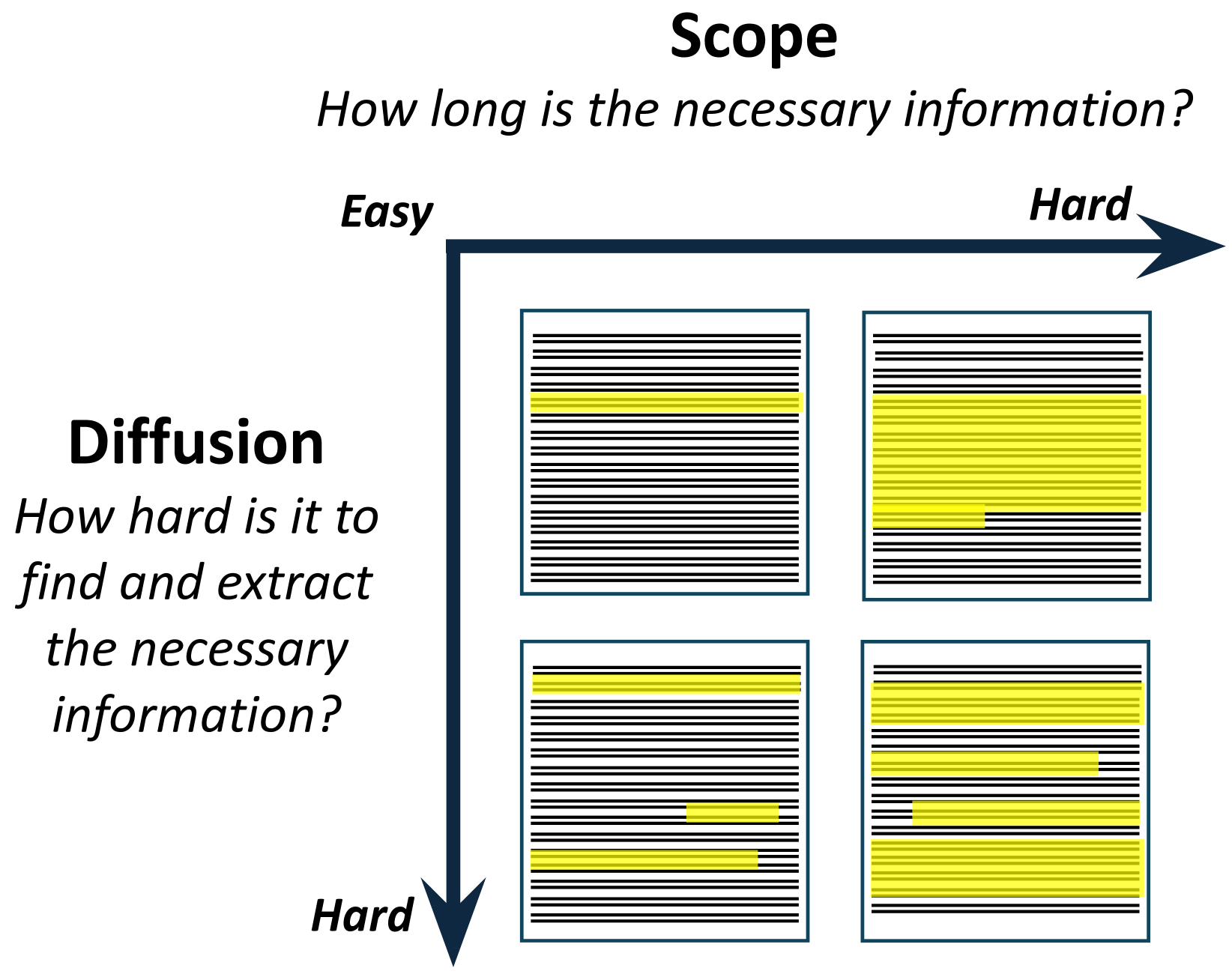
Improvements in language models' capabilities have pushed their applications towards longer contexts, making long-context evaluation and development an active research area. However, many disparate use-cases are grouped together under the umbrella term of long-context, defined simply by the total length of the model's input, including - for example - Needle-in-a-Haystack tasks, book summarization, and information aggregation. Given their varied difficulty, in this position paper we argue that conflating different tasks by their context length is unproductive. As a community, we require a more precise vocabulary to understand what makes long-context tasks similar or different. We propose to unpack the taxonomy of long-context based on the properties that make them more difficult with longer contexts. We propose two orthogonal axes of difficulty: (I) Diffusion: How hard is it to find the necessary information in the context? (II) Scope: How much necessary information is there to find? We survey the literature on long-context, provide justification for this taxonomy as an informative descriptor, and situate the literature with respect to it. We conclude that the most difficult and interesting settings, whose necessary information is very long and highly diffused within the input, is severely under-explored. By using a descriptive vocabulary and discussing the relevant properties of difficulty in long-context, we can implement more informed research in this area. We call for a careful design of tasks and benchmarks with distinctly long context, taking into account the characteristics that make it qualitatively different from shorter context.
7/2/2024

Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jinhyuk Lee, Anthony Chen, Zhuyun Dai, Dheeru Dua, Devendra Singh Sachan, Michael Boratko, Yi Luan, S'ebastien M. R. Arnold, Vincent Perot, Siddharth Dalmia, Hexiang Hu, Xudong Lin, Panupong Pasupat, Aida Amini, Jeremy R. Cole, Sebastian Riedel, Iftekhar Naim, Ming-Wei Chang, Kelvin Guu
0
0
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
6/21/2024

Long-context LLMs Struggle with Long In-context Learning
Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, Wenhu Chen
0
0
Large Language Models (LLMs) have made significant strides in handling long sequences. Some models like Gemini could even to be capable of dealing with millions of tokens. However, their performance evaluation has largely been confined to metrics like perplexity and synthetic tasks, which may not fully capture their true abilities in more challenging, real-world scenarios. We introduce a benchmark (LongICLBench) for long in-context learning in extreme-label classification using six datasets with 28 to 174 classes and input lengths from 2K to 50K tokens. Our benchmark requires LLMs to comprehend the entire input to recognize the massive label spaces to make correct predictions. We evaluate on 15 long-context LLMs and find that they perform well on less challenging classification tasks with smaller label space and shorter demonstrations. However, they struggle with more challenging task like Discovery with 174 labels, suggesting a gap in their ability to process long, context-rich sequences. Further analysis reveals a bias towards labels presented later in the sequence and a need for improved reasoning over multiple pieces of information. Our study reveals that long context understanding and reasoning is still a challenging task for the existing LLMs. We believe LongICLBench could serve as a more realistic evaluation for the future long-context LLMs.
6/13/2024

BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack
Yuri Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Sorokin, Artyom Sorokin, Mikhail Burtsev
0
0
In recent years, the input context sizes of large language models (LLMs) have increased dramatically. However, existing evaluation methods have not kept pace, failing to comprehensively assess the efficiency of models in handling long contexts. To bridge this gap, we introduce the BABILong benchmark, designed to test language models' ability to reason across facts distributed in extremely long documents. BABILong includes a diverse set of 20 reasoning tasks, including fact chaining, simple induction, deduction, counting, and handling lists/sets. These tasks are challenging on their own, and even more demanding when the required facts are scattered across long natural text. Our evaluations show that popular LLMs effectively utilize only 10-20% of the context and their performance declines sharply with increased reasoning complexity. Among alternatives to in-context reasoning, Retrieval-Augmented Generation methods achieve a modest 60% accuracy on single-fact question answering, independent of context length. Among context extension methods, the highest performance is demonstrated by recurrent memory transformers, enabling the processing of lengths up to 11 million tokens. The BABILong benchmark is extendable to any length to support the evaluation of new upcoming models with increased capabilities, and we provide splits up to 1 million token lengths.
6/17/2024