Can We Enhance the Quality of Mobile Crowdsensing Data Without Ground Truth?

0
Sign in to get full access
Overview
- This paper explores ways to enhance the quality of mobile crowdsensing data without having access to ground truth information.
- Mobile crowdsensing involves using mobile devices to collect data about the environment, which can be useful for a variety of applications. However, the data collected can be of varying quality, and it can be difficult to verify its accuracy without a known ground truth.
- The authors propose a novel approach that combines reputation modeling and data prediction to improve the overall quality of the crowdsensed data, even in the absence of ground truth.
Plain English Explanation
Mobile crowdsensing is a technique where people use their mobile devices, like smartphones, to collect data about their surroundings. This data can be really useful for things like tracking traffic patterns, monitoring air quality, or detecting network intrusions.
The challenge is that the data collected by all these different people may not always be accurate or reliable. Normally, you'd need to have some "ground truth" data - information that you know is definitely correct - to help judge the quality of the crowdsourced data. But what if you don't have that ground truth data available?
The researchers in this paper came up with a clever solution. They use a combination of two techniques:
- Reputation modeling: This means keeping track of how reliable each person's data has been in the past. That way, you can give more weight to data from people who have a history of providing accurate information.
- Data prediction: This involves using machine learning to try to predict what the correct data should be, based on patterns in the crowdsourced data. The predicted data can then be used to help identify and filter out low-quality or "spammy" submissions.
By using these two approaches together, the researchers were able to enhance the overall quality of the mobile crowdsensing data, even without having access to ground truth information. This could be really useful for a lot of real-world applications that rely on crowdsourced data, but don't have a perfect way to verify its accuracy.
Technical Explanation
The paper proposes a novel approach to enhancing the trustworthiness of mobile crowdsensing data in the absence of ground truth information. The authors combine reputation modeling and data prediction to improve the overall quality of the crowdsensed data.
The reputation modeling component keeps track of the historical reliability of each user's contributions, assigning higher weights to data from users with a proven track record of accuracy. This helps filter out low-quality or "spammy" submissions.
The data prediction component uses machine learning techniques to generate estimates of the "ground truth" values based on patterns in the crowdsourced data. These predictions are then used to identify and remove outliers that are likely to be erroneous.
By integrating these two approaches, the authors demonstrate that they can significantly enhance the quality of mobile crowdsensing data without requiring access to actual ground truth information. This is an important advance, as ground truth data is often difficult or expensive to obtain, particularly for large-scale, decentralized crowdsensing applications.
The authors evaluate their proposed method using both synthetic and real-world datasets, showing substantial improvements in data quality metrics compared to baseline approaches. They also discuss the potential limitations of their technique, such as the need for a sufficient number of user contributions to build reliable reputations and the challenges of accurately modeling complex, non-linear relationships in the data.
Critical Analysis
The authors present a compelling approach for improving the quality of crowdsourced data without access to ground truth information. By combining reputation modeling and data prediction, they are able to effectively filter out unreliable or "spammy" contributions and enhance the overall trustworthiness of the dataset.
One potential limitation of the proposed method is its reliance on having a sufficient number of user contributions to build reliable reputations. In scenarios where the crowdsourcing pool is small or there is high turnover, the reputation modeling component may struggle to accurately distinguish between reliable and unreliable sources. The authors acknowledge this challenge and suggest that further research is needed to address it.
Another area for potential improvement is the data prediction component. While the authors demonstrate the effectiveness of their machine learning-based approach, the accuracy of the predictions may be limited by the complexity of the underlying relationships in the data. Exploring more advanced modeling techniques, such as deep learning, could potentially lead to even more accurate ground truth estimates.
Overall, the authors have made a valuable contribution to the field of mobile crowdsensing by presenting a novel approach to enhancing data quality without ground truth. Their work highlights the importance of developing robust techniques for dealing with unreliable or incomplete information in decentralized data collection scenarios. Further research building on these ideas could lead to even more effective solutions for improving the trustworthiness of crowdsourced data.
Conclusion
This paper presents a novel approach for enhancing the quality of mobile crowdsensing data in the absence of ground truth information. By combining reputation modeling and data prediction, the authors demonstrate a way to effectively filter out unreliable or "spammy" contributions and improve the overall trustworthiness of the crowdsourced dataset.
The proposed method represents an important advancement in the field of mobile crowdsensing, addressing a key challenge that has hindered the widespread adoption of these technologies. By enabling high-quality data collection without the need for expensive ground truth validation, this work could unlock new opportunities for crowdsourcing-based applications across a variety of domains, from traffic monitoring to environmental sensing.
While the authors acknowledge some potential limitations of their approach, such as the need for a sufficient number of user contributions, their work serves as a valuable foundation for further research in this area. Exploring more advanced modeling techniques and addressing the scalability challenges of reputation-based systems could lead to even more robust solutions for ensuring the reliability of crowdsourced data.
Overall, this paper makes a significant contribution to the field of mobile crowdsensing and provides a promising path forward for enhancing the quality and trustworthiness of decentralized data collection systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can We Enhance the Quality of Mobile Crowdsensing Data Without Ground Truth?
Jiajie Li, Bo Gu, Shimin Gong, Zhou Su, Mohsen Guizani
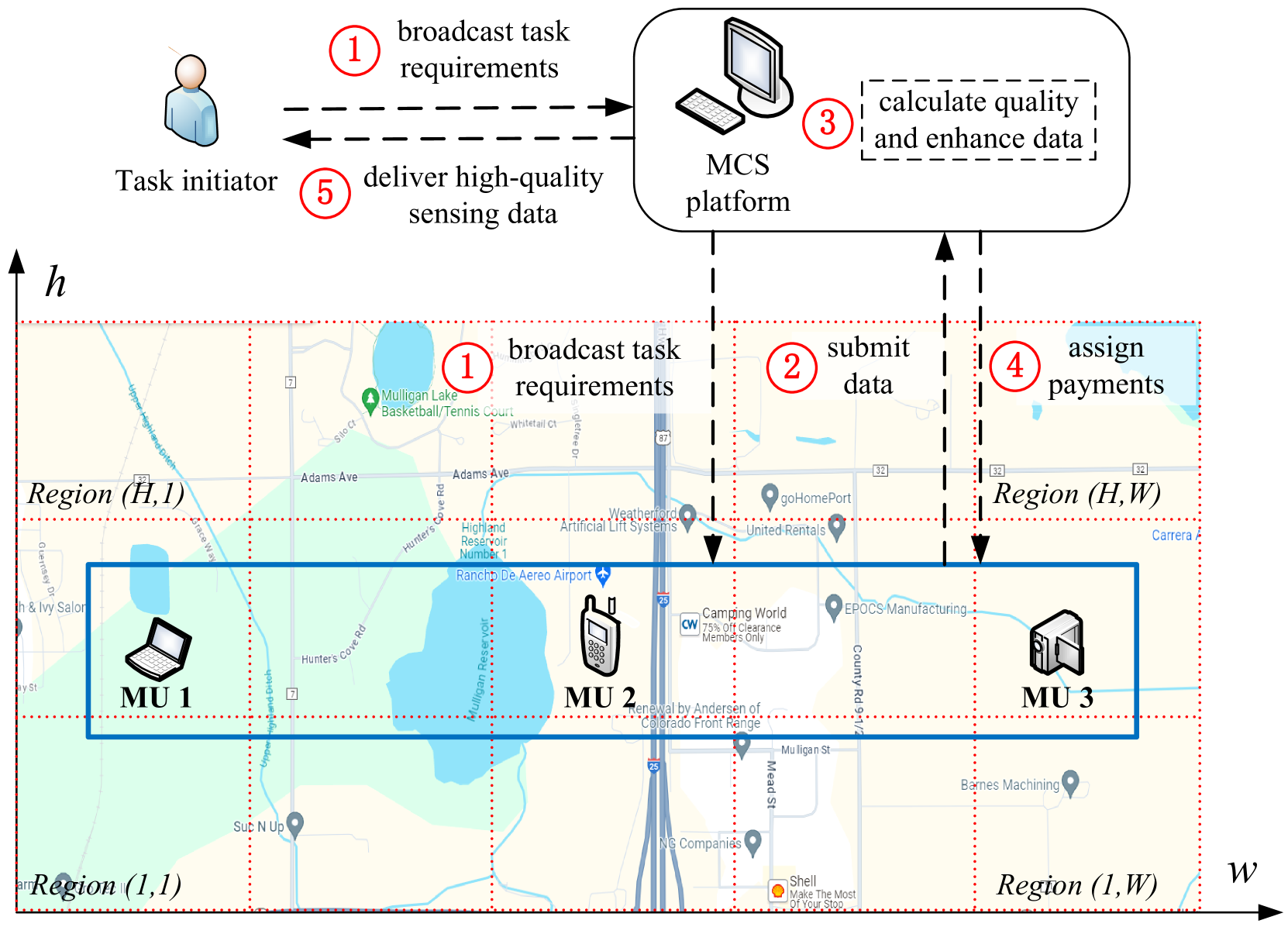
Mobile crowdsensing (MCS) has emerged as a prominent trend across various domains. However, ensuring the quality of the sensing data submitted by mobile users (MUs) remains a complex and challenging problem. To address this challenge, an advanced method is required to detect low-quality sensing data and identify malicious MUs that may disrupt the normal operations of an MCS system. Therefore, this article proposes a prediction- and reputation-based truth discovery (PRBTD) framework, which can separate low-quality data from high-quality data in sensing tasks. First, we apply a correlation-focused spatial-temporal transformer network to predict the ground truth of the input sensing data. Then, we extract the sensing errors of the data as features based on the prediction results to calculate the implications among the data. Finally, we design a reputation-based truth discovery (TD) module for identifying low-quality data with their implications. Given sensing data submitted by MUs, PRBTD can eliminate the data with heavy noise and identify malicious MUs with high accuracy. Extensive experimental results demonstrate that PRBTD outperforms the existing methods in terms of identification accuracy and data quality enhancement.
Read more5/30/2024

0
Enhancing Wireless Networks with Attention Mechanisms: Insights from Mobile Crowdsensing
Yaoqi Yang, Hongyang Du, Zehui Xiong, Dusit Niyato, Abbas Jamalipour, Zhu Han
The increasing demand for sensing, collecting, transmitting, and processing vast amounts of data poses significant challenges for resource-constrained mobile users, thereby impacting the performance of wireless networks. In this regard, from a case of mobile crowdsensing (MCS), we aim at leveraging attention mechanisms in machine learning approaches to provide solutions for building an effective, timely, and secure MCS. Specifically, we first evaluate potential combinations of attention mechanisms and MCS by introducing their preliminaries. Then, we present several emerging scenarios about how to integrate attention into MCS, including task allocation, incentive design, terminal recruitment, privacy preservation, data collection, and data transmission. Subsequently, we propose an attention-based framework to solve network optimization problems with multiple performance indicators in large-scale MCS. The designed case study have evaluated the effectiveness of the proposed framework. Finally, we outline important research directions for advancing attention-enabled MCS.
Read more7/23/2024

0
Data Quality in Crowdsourcing and Spamming Behavior Detection
Yang Ba, Michelle V. Mancenido, Erin K. Chiou, Rong Pan
As crowdsourcing emerges as an efficient and cost-effective method for obtaining labels for machine learning datasets, it is important to assess the quality of crowd-provided data, so as to improve analysis performance and reduce biases in subsequent machine learning tasks. Given the lack of ground truth in most cases of crowdsourcing, we refer to data quality as annotators' consistency and credibility. Unlike the simple scenarios where Kappa coefficient and intraclass correlation coefficient usually can apply, online crowdsourcing requires dealing with more complex situations. We introduce a systematic method for evaluating data quality and detecting spamming threats via variance decomposition, and we classify spammers into three categories based on their different behavioral patterns. A spammer index is proposed to assess entire data consistency and two metrics are developed to measure crowd worker's credibility by utilizing the Markov chain and generalized random effects models. Furthermore, we showcase the practicality of our techniques and their advantages by applying them on a face verification task with both simulation and real-world data collected from two crowdsourcing platforms.
Read more4/30/2024

0
Toward Time-Continuous Data Inference in Sparse Urban CrowdSensing
Ziyu Sun, Haoyang Su, Hanqi Sun, En Wang, Wenbin Liu
Mobile Crowd Sensing (MCS) is a promising paradigm that leverages mobile users and their smart portable devices to perform various real-world tasks. However, due to budget constraints and the inaccessibility of certain areas, Sparse MCS has emerged as a more practical alternative, collecting data from a limited number of target subareas and utilizing inference algorithms to complete the full sensing map. While existing approaches typically assume a time-discrete setting with data remaining constant within each sensing cycle, this simplification can introduce significant errors, especially when dealing with long cycles, as real-world sensing data often changes continuously. In this paper, we go from fine-grained completion, i.e., the subdivision of sensing cycles into minimal time units, towards a more accurate, time-continuous completion. We first introduce Deep Matrix Factorization (DMF) as a neural network-enabled framework and enhance it with a Recurrent Neural Network (RNN-DMF) to capture temporal correlations in these finer time slices. To further deal with the continuous data, we propose TIME-DMF, which captures temporal information across unequal intervals, enabling time-continuous completion. Additionally, we present the Query-Generate (Q-G) strategy within TIME-DMF to model the infinite states of continuous data. Extensive experiments across five types of sensing tasks demonstrate the effectiveness of our models and the advantages of time-continuous completion.
Read more8/30/2024