Can We Verify Step by Step for Incorrect Answer Detection?
2402.10528
0
0
Abstract
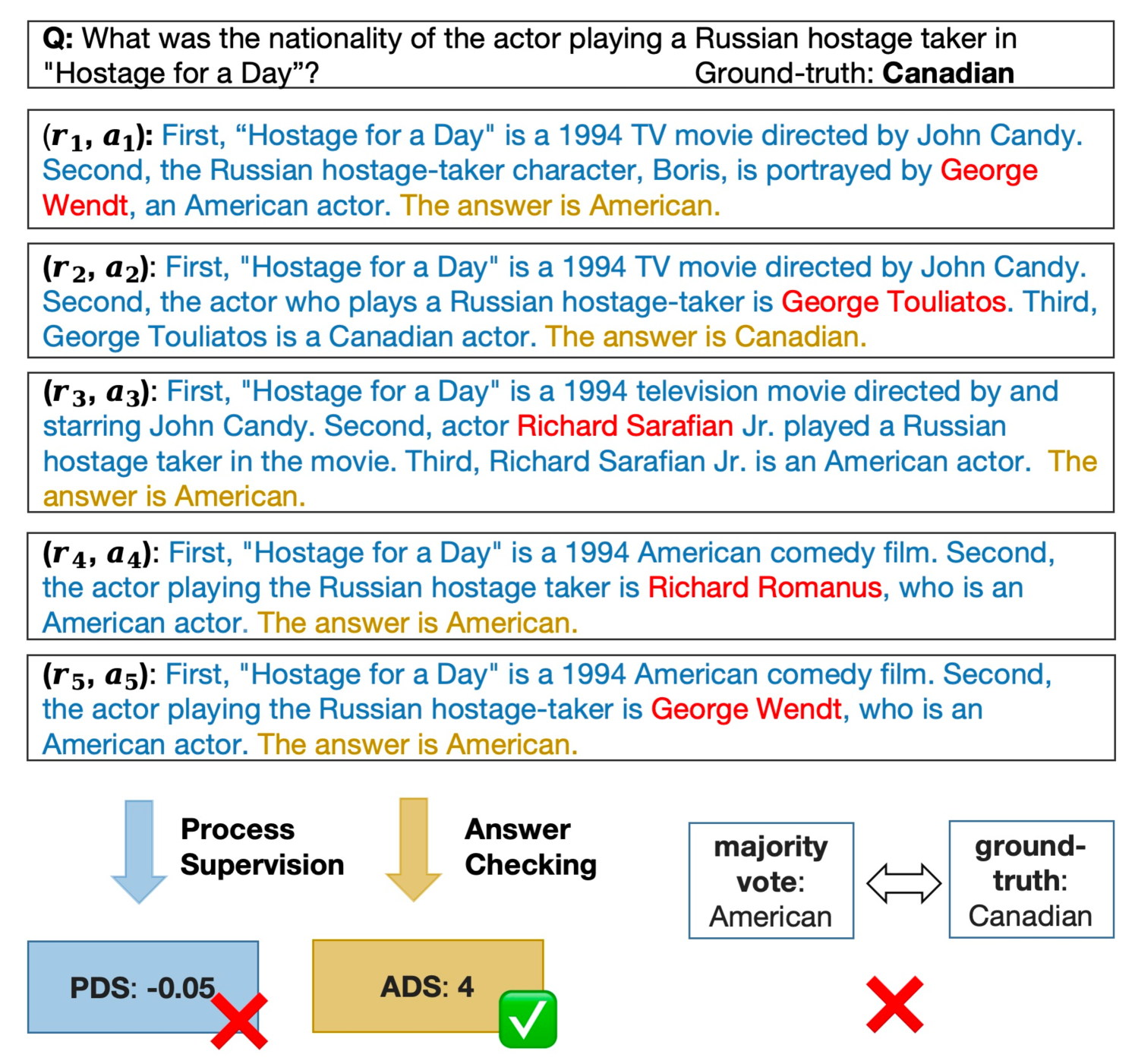
Chain-of-Thought (CoT) prompting has marked a significant advancement in enhancing the reasoning capabilities of large language models (LLMs). Previous studies have developed various extensions of CoT, which focus primarily on enhancing end-task performance. In addition, there has been research on assessing the quality of reasoning chains in CoT. This raises an intriguing question: Is it possible to predict the accuracy of LLM outputs by scrutinizing the reasoning chains they generate? To answer this research question, we introduce a benchmark, R2PE, designed specifically to explore the relationship between reasoning chains and performance in various reasoning tasks spanning five different domains. This benchmark aims to measure the falsehood of the final output of LLMs based on the reasoning steps. To make full use of information in multiple reasoning chains, we propose the process discernibility score (PDS) framework that beats the answer-checking baseline by a large margin. Concretely, this resulted in an average of $5.1%$ increase in the F1 score and $2.97%$ improvement in AUC-PR across all 45 subsets within R2PE. We further demonstrate our PDS's efficacy in advancing open-domain QA accuracy. Data and code are available at https://github.com/XinXU-USTC/R2PE.
Create account to get full access
Overview
- This paper proposes a novel benchmark called R2PE (Reasoning Required Procedural Evaluation) to evaluate language models' ability to detect incorrect answers in a step-by-step reasoning process.
- The benchmark tests language models' understanding of procedural knowledge and their capacity to identify mistakes at each step of a multi-step problem-solving process.
- The authors demonstrate that current large language models struggle to consistently detect errors in the step-by-step reasoning, highlighting the need for further advancements in language model reasoning capabilities.
Plain English Explanation
The paper introduces a new way to test the capabilities of AI language models, called the R2PE (Reasoning Required Procedural Evaluation) benchmark. The goal is to see how well these models can follow and understand a step-by-step process for solving a problem, and importantly, catch any mistakes that might happen along the way.
Imagine you're trying to teach a child how to solve a math problem. You'd want to make sure they understand each individual step, and can spot if they make an error somewhere in the process. The R2PE benchmark works in a similar way, but with AI language models instead of children.
The researchers create a dataset of multi-step problems, like math problems or logical reasoning tasks, and then introduce deliberate mistakes at various points in the process. They then see how well the language models can identify those mistakes. This is a challenging task, as it requires the models to deeply understand the problem-solving process, not just the final answer.
The paper shows that current state-of-the-art language models struggle with this benchmark, often failing to catch the mistakes even when they are quite obvious to a human. This suggests there is still more work to be done to improve the reasoning capabilities of these AI systems, so they can truly understand and validate step-by-step problem-solving the way humans can.
Technical Explanation
The paper introduces the R2PE Benchmark, a new evaluation framework designed to assess language models' ability to detect incorrect answers in a step-by-step reasoning process.
The key idea behind the R2PE benchmark is to test language models' understanding of procedural knowledge and their capacity to identify mistakes at each step of a multi-step problem-solving process. The authors construct a dataset of reasoning tasks that require a sequence of steps to arrive at the final answer. Crucially, they also introduce deliberate errors at various points in the process, challenging the models to spot these mistakes.
To evaluate the language models, the authors present them with the step-by-step reasoning and ask them to identify any incorrect steps. This tests the models' grasp of the underlying logic and their ability to verify the reasoning chain, rather than simply focusing on the final output.
The experiments reveal that current large language models struggle to consistently detect errors in the step-by-step reasoning, even when the mistakes are relatively simple. This suggests that while these models excel at language understanding and generation, they still lack the robust reasoning capabilities required to thoroughly validate complex, multi-step problem-solving.
Critical Analysis
The R2PE benchmark represents an important step forward in evaluating the reasoning capabilities of language models. By focusing on step-by-step procedures and the identification of specific errors, the benchmark goes beyond simply assessing the final output of a model and delves into its deeper understanding of the problem-solving process.
One potential limitation of the R2PE benchmark is the reliance on a predetermined set of tasks and errors. While this allows for controlled evaluation, it may not fully capture the breadth of real-world reasoning challenges that language models would need to handle. Expanding the benchmark to include a more diverse set of problems and error types could provide a more comprehensive assessment.
Additionally, the paper does not delve into the underlying reasons why current language models struggle with the R2PE benchmark. Further research is needed to understand the specific weaknesses in their reasoning capabilities and develop more effective approaches for improving their performance on this type of task.
Overall, the R2PE benchmark represents a valuable contribution to the field of language model evaluation, highlighting the need for continued advancements in the reasoning and validation abilities of these AI systems.
Conclusion
The R2PE benchmark introduced in this paper represents a significant step forward in evaluating the reasoning capabilities of language models. By focusing on the ability to detect errors in a step-by-step problem-solving process, the benchmark provides a more nuanced assessment of these models' understanding of procedural knowledge and their capacity for logical reasoning.
The paper's finding that current state-of-the-art language models struggle to consistently identify mistakes in the step-by-step reasoning process underscores the need for further advancements in this area. Improving language models' verification and self-correction capabilities could lead to more robust and trustworthy AI assistants, capable of providing reliable step-by-step guidance and validation for a wide range of tasks.
As the field of language model research continues to progress, benchmarks like R2PE will play a crucial role in driving the development of models with stronger reasoning skills, ultimately paving the way for more intelligent and capable AI systems that can better assist and collaborate with humans.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
Alon Jacovi, Yonatan Bitton, Bernd Bohnet, Jonathan Herzig, Or Honovich, Michael Tseng, Michael Collins, Roee Aharoni, Mor Geva
0
0
Prompting language models to provide step-by-step answers (e.g., Chain-of-Thought) is the prominent approach for complex reasoning tasks, where more accurate reasoning chains typically improve downstream task performance. Recent literature discusses automatic methods to verify reasoning to evaluate and improve their correctness. However, no fine-grained step-level datasets are available to enable thorough evaluation of such verification methods, hindering progress in this direction. We introduce REVEAL: Reasoning Verification Evaluation, a dataset to benchmark automatic verifiers of complex Chain-of-Thought reasoning in open-domain question-answering settings. REVEAL includes comprehensive labels for the relevance, attribution to evidence passages, and logical correctness of each reasoning step in a language model's answer, across a variety of datasets and state-of-the-art language models. Evaluation on REVEAL shows that verifiers struggle at verifying reasoning chains - in particular, verifying logical correctness and detecting contradictions. Available at https://reveal-dataset.github.io/ .
5/22/2024
Chain-of-Probe: Examing the Necessity and Accuracy of CoT Step-by-Step
Zezhong Wang, Xingshan Zeng, Weiwen Liu, Yufei Wang, Liangyou Li, Yasheng Wang, Lifeng Shang, Xin Jiang, Qun Liu, Kam-Fai Wong
0
0
Current research found the issue of Early Answering in large language models (LLMs), where the models already have an answer before generating the Chain-of-Thought (CoT). This phenomenon suggests a potential lack of necessary dependency between the predicted answer and the reasoning process. Consequently, two important questions arise: (1) Is CoT still necessary if the model already has an answer? (2) Can the correctness of the answer serve as valid evidence for the correctness of CoT? To address these questions, we propose a method, namely Chain-of-Probe (CoP), to probe changes in the mind during the model's reasoning. The probing results show that in a significant number of question-answer cases, CoT appears to be unnecessary, and this necessity correlates with the simplicity of the task, defined by reasoning steps required. Furthermore, by analyzing patterns in mind change, we examine the correctness of the model's reasoning. Our validation reveals that many responses, although correct in their final answer, contain errors in their reasoning process. To this end, we propose a strategic approach based on CoP to prioritize answers with correct reasoning among multiple candidates, thereby bolstering the reliability of the model's reasoning.
6/26/2024

General Purpose Verification for Chain of Thought Prompting
Robert Vacareanu, Anurag Pratik, Evangelia Spiliopoulou, Zheng Qi, Giovanni Paolini, Neha Anna John, Jie Ma, Yassine Benajiba, Miguel Ballesteros
0
0
Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
5/2/2024
💬
Boosting Language Models Reasoning with Chain-of-Knowledge Prompting
Jianing Wang, Qiushi Sun, Xiang Li, Ming Gao
0
0
Recently, Chain-of-Thought (CoT) prompting has delivered success on complex reasoning tasks, which aims at designing a simple prompt like ``Let's think step by step'' or multiple in-context exemplars with well-designed rationales to elicit Large Language Models (LLMs) to generate intermediate reasoning steps. However, the generated rationales often come with mistakes, making unfactual and unfaithful reasoning chains. To mitigate this brittleness, we propose a novel Chain-of-Knowledge (CoK) prompting, where we aim at eliciting LLMs to generate explicit pieces of knowledge evidence in the form of structure triple. This is inspired by our human behaviors, i.e., we can draw a mind map or knowledge map as the reasoning evidence in the brain before answering a complex question. Benefiting from CoK, we additionally introduce a F^2-Verification method to estimate the reliability of the reasoning chains in terms of factuality and faithfulness. For the unreliable response, the wrong evidence can be indicated to prompt the LLM to rethink. Extensive experiments demonstrate that our method can further improve the performance of commonsense, factual, symbolic, and arithmetic reasoning tasks.
6/4/2024