A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
2402.00559
0
0

Abstract
Prompting language models to provide step-by-step answers (e.g., Chain-of-Thought) is the prominent approach for complex reasoning tasks, where more accurate reasoning chains typically improve downstream task performance. Recent literature discusses automatic methods to verify reasoning to evaluate and improve their correctness. However, no fine-grained step-level datasets are available to enable thorough evaluation of such verification methods, hindering progress in this direction. We introduce REVEAL: Reasoning Verification Evaluation, a dataset to benchmark automatic verifiers of complex Chain-of-Thought reasoning in open-domain question-answering settings. REVEAL includes comprehensive labels for the relevance, attribution to evidence passages, and logical correctness of each reasoning step in a language model's answer, across a variety of datasets and state-of-the-art language models. Evaluation on REVEAL shows that verifiers struggle at verifying reasoning chains - in particular, verifying logical correctness and detecting contradictions. Available at https://reveal-dataset.github.io/ .
Create account to get full access
Overview
- This paper presents a benchmark for evaluating how well language models can verify the reasoning behind a chain of thought, with the core idea that a chain is only as strong as its weakest link.
- The authors propose a formal framework for modeling reasoning chains and introduce a suite of evaluation tasks to assess a model's ability to identify flaws or gaps in a given chain of thought.
- The benchmark aims to spur progress in developing more robust and reliable AI systems that can engage in meaningful, multi-step reasoning and provide transparent explanations for their outputs.
Plain English Explanation
The paper is focused on a critical challenge in artificial intelligence (AI) – the ability to verify and evaluate the reasoning behind a series of interconnected thoughts or steps, known as a "chain of thought." The key insight is that the quality of a chain of thought is limited by the weakest link, so it's important to be able to identify any weak or flawed reasoning within the chain.
The authors introduce a formal framework for modeling these reasoning chains, which can include things like assumptions, logical inferences, and evidence. They then propose a suite of evaluation tasks to assess how well AI systems can identify issues or gaps in a given chain of thought.
This benchmark is designed to encourage the development of more robust and transparent AI systems that can engage in multi-step reasoning and provide clear explanations for their outputs. By being able to verify the reasoning process, these systems could become more trustworthy and useful in high-stakes applications like medical diagnosis, financial planning, or policy decision-making.
The ideas around chains, trees, and graphs of thought are quite technical, but the core goal is to ensure that AI systems don't just generate plausible-sounding outputs, but can back up their reasoning in a way that can be scrutinized and verified. This is an important step towards developing AI systems that are more reliable, accountable, and aligned with human values.
Technical Explanation
The paper introduces a formal framework for modeling reasoning chains, which are sequences of interconnected steps that lead from an initial premise or question to a final conclusion. Each step in the chain can involve assumptions, logical inferences, and evidence. The key insight is that the quality of the entire chain is limited by the "weakest link" – any flaw or gap in the reasoning at any step can undermine the reliability of the final output.
To evaluate the ability of language models to verify reasoning chains, the authors propose a suite of tasks that assess different aspects of the chain verification process. These include:
- Chain Completeness: Identifying missing steps or information needed to fully justify the reasoning.
- Chain Soundness: Detecting logical flaws, invalid inferences, or unsupported assumptions within the chain.
- Chain Attribution: Determining which specific steps or components of the chain are responsible for errors or weaknesses.
The authors also introduce the concept of "chain-of-thought prompting," where language models are tasked with generating not just a final answer, but also the step-by-step reasoning process that led to that answer. By exposing the internal reasoning, these prompts allow for more thorough verification and debugging of the model's outputs.
The proposed benchmark is designed to be a general-purpose tool for evaluating reasoning capabilities, with the goal of driving progress towards more reliable, transparent, and accountable AI systems. The authors envision applications in fields like medical diagnosis, financial planning, and policy decision-making, where the ability to verify and trust the reasoning behind an AI's outputs is crucial.
Critical Analysis
The authors' focus on verifying the reasoning behind language model outputs is a valuable contribution to the field of AI safety and transparency. By shifting the emphasis from just generating plausible-sounding responses to rigorously scrutinizing the underlying reasoning process, the proposed benchmark could help drive the development of more robust and trustworthy AI systems.
That said, the technical complexity of the formalism and evaluation tasks presented in the paper may pose challenges for practical implementation and adoption. The authors acknowledge that the framework relies on a number of assumptions and simplifications, and there may be inherent limitations in the ability of current language models to fully capture the nuances of human reasoning.
Additionally, while the benchmark is designed to be general-purpose, its application to real-world, high-stakes domains may require further refinement and validation. The authors mention the need for careful task design and dataset curation to ensure the benchmark is suitable for specific use cases.
Nonetheless, the core ideas underlying this work – the importance of verifying reasoning chains, the concept of chain-of-thought prompting, and the need for more transparent and accountable AI systems – are valuable and deserve further exploration. As the field of AI continues to advance, the ability to rigorously evaluate and validate the reasoning capabilities of language models will become increasingly critical.
Conclusion
The paper presents a novel benchmark for verifying the reasoning behind language model outputs, with the goal of driving progress towards more reliable and transparent AI systems. By focusing on the quality and completeness of the reasoning chain, rather than just the final answer, the proposed framework aims to uncover flaws or gaps that could undermine the trustworthiness of an AI's outputs.
While the technical complexity of the formalism and evaluation tasks may pose challenges for practical implementation, the core ideas behind this work are important and timely. As AI systems become increasingly integrated into high-stakes decision-making processes, the ability to verify and trust the reasoning behind their outputs will be crucial. This benchmark represents an important step towards developing AI systems that are not only capable, but also transparent, accountable, and aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

General Purpose Verification for Chain of Thought Prompting
Robert Vacareanu, Anurag Pratik, Evangelia Spiliopoulou, Zheng Qi, Giovanni Paolini, Neha Anna John, Jie Ma, Yassine Benajiba, Miguel Ballesteros
0
0
Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
5/2/2024
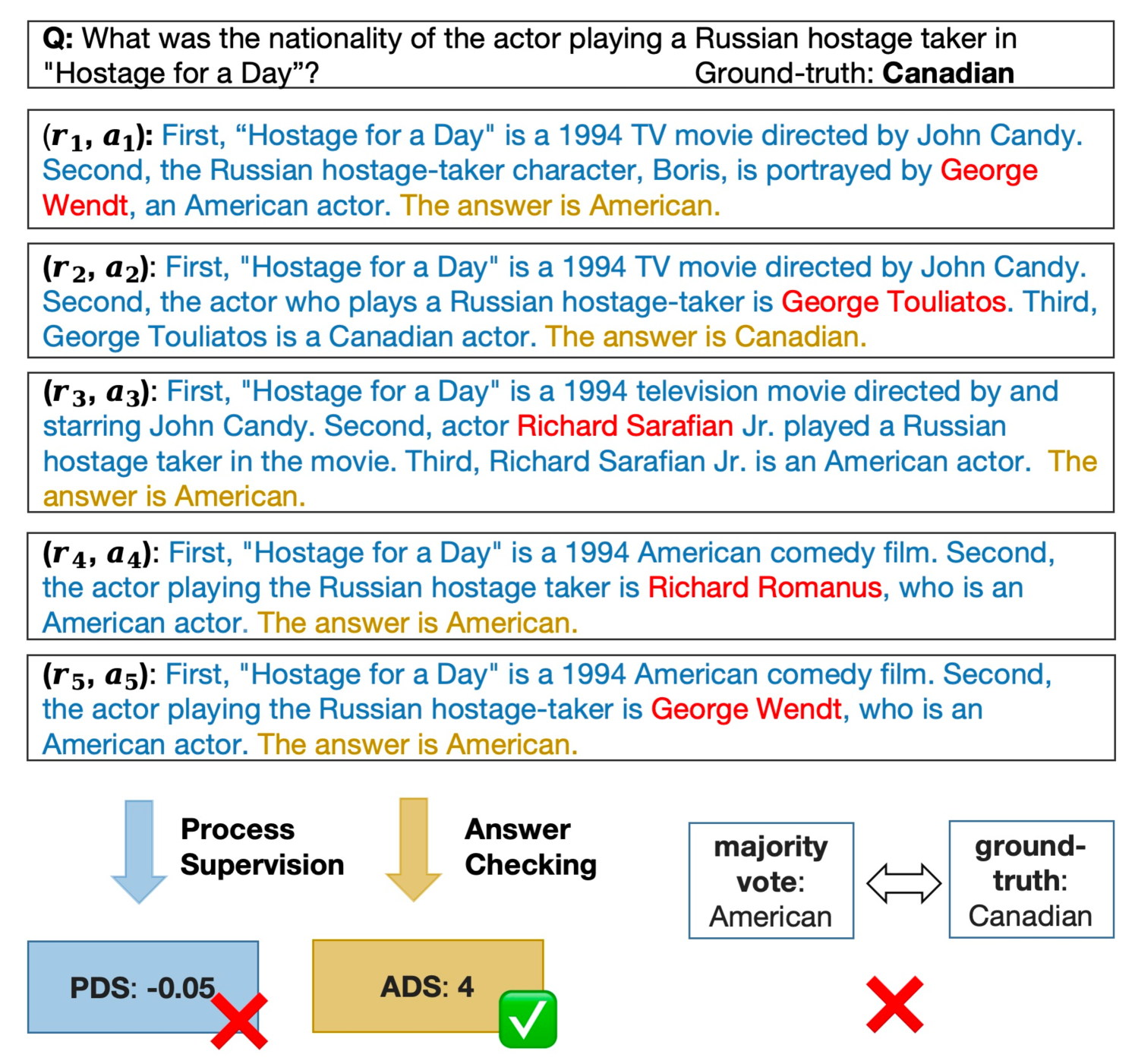
Can We Verify Step by Step for Incorrect Answer Detection?
Xin Xu, Shizhe Diao, Can Yang, Yang Wang
0
0
Chain-of-Thought (CoT) prompting has marked a significant advancement in enhancing the reasoning capabilities of large language models (LLMs). Previous studies have developed various extensions of CoT, which focus primarily on enhancing end-task performance. In addition, there has been research on assessing the quality of reasoning chains in CoT. This raises an intriguing question: Is it possible to predict the accuracy of LLM outputs by scrutinizing the reasoning chains they generate? To answer this research question, we introduce a benchmark, R2PE, designed specifically to explore the relationship between reasoning chains and performance in various reasoning tasks spanning five different domains. This benchmark aims to measure the falsehood of the final output of LLMs based on the reasoning steps. To make full use of information in multiple reasoning chains, we propose the process discernibility score (PDS) framework that beats the answer-checking baseline by a large margin. Concretely, this resulted in an average of $5.1%$ increase in the F1 score and $2.97%$ improvement in AUC-PR across all 45 subsets within R2PE. We further demonstrate our PDS's efficacy in advancing open-domain QA accuracy. Data and code are available at https://github.com/XinXU-USTC/R2PE.
6/18/2024

Break the Chain: Large Language Models Can be Shortcut Reasoners
Mengru Ding, Hanmeng Liu, Zhizhang Fu, Jian Song, Wenbo Xie, Yue Zhang
0
0
Recent advancements in Chain-of-Thought (CoT) reasoning utilize complex modules but are hampered by high token consumption, limited applicability, and challenges in reproducibility. This paper conducts a critical evaluation of CoT prompting, extending beyond arithmetic to include complex logical and commonsense reasoning tasks, areas where standard CoT methods fall short. We propose the integration of human-like heuristics and shortcuts into language models (LMs) through break the chain strategies. These strategies disrupt traditional CoT processes using controlled variables to assess their efficacy. Additionally, we develop innovative zero-shot prompting strategies that encourage the use of shortcuts, enabling LMs to quickly exploit reasoning clues and bypass detailed procedural steps. Our comprehensive experiments across various LMs, both commercial and open-source, reveal that LMs maintain effective performance with break the chain strategies. We also introduce ShortcutQA, a dataset specifically designed to evaluate reasoning through shortcuts, compiled from competitive tests optimized for heuristic reasoning tasks such as forward/backward reasoning and simplification. Our analysis confirms that ShortcutQA not only poses a robust challenge to LMs but also serves as an essential benchmark for enhancing reasoning efficiency in AI.
6/12/2024
💬
Boosting Language Models Reasoning with Chain-of-Knowledge Prompting
Jianing Wang, Qiushi Sun, Xiang Li, Ming Gao
0
0
Recently, Chain-of-Thought (CoT) prompting has delivered success on complex reasoning tasks, which aims at designing a simple prompt like ``Let's think step by step'' or multiple in-context exemplars with well-designed rationales to elicit Large Language Models (LLMs) to generate intermediate reasoning steps. However, the generated rationales often come with mistakes, making unfactual and unfaithful reasoning chains. To mitigate this brittleness, we propose a novel Chain-of-Knowledge (CoK) prompting, where we aim at eliciting LLMs to generate explicit pieces of knowledge evidence in the form of structure triple. This is inspired by our human behaviors, i.e., we can draw a mind map or knowledge map as the reasoning evidence in the brain before answering a complex question. Benefiting from CoK, we additionally introduce a F^2-Verification method to estimate the reliability of the reasoning chains in terms of factuality and faithfulness. For the unreliable response, the wrong evidence can be indicated to prompt the LLM to rethink. Extensive experiments demonstrate that our method can further improve the performance of commonsense, factual, symbolic, and arithmetic reasoning tasks.
6/4/2024