Candidate Pseudolabel Learning: Enhancing Vision-Language Models by Prompt Tuning with Unlabeled Data

0

Sign in to get full access
Overview
- The paper introduces a novel approach called "Candidate Pseudolabel Learning" (CPL) to enhance vision-language models (VLMs) using unlabeled data.
- CPL leverages prompt tuning to learn effective pseudolabels from unlabeled data, which are then used to fine-tune the VLM.
- The proposed method achieves state-of-the-art performance on various VLM benchmarks while using less training data compared to previous approaches.
Plain English Explanation
Vision-language models (VLMs) are AI systems that can understand and generate both visual and textual content. These models have shown impressive capabilities, but their performance is often limited by the availability of labeled training data.
Candidate Pseudolabel Learning (CPL) is a new technique that can enhance VLMs using unlabeled data. The key idea is to "prompt tune" the VLM to generate candidate pseudolabels (or predicted labels) for the unlabeled data. These pseudolabels are then used to fine-tune the VLM, effectively leveraging the unlabeled data to improve the model's performance.
The researchers found that CPL can outperform state-of-the-art VLM models on various benchmarks, while using less training data. This is a significant advantage, as collecting and annotating large datasets can be a major bottleneck in developing advanced AI systems.
Technical Explanation
The paper proposes the Candidate Pseudolabel Learning (CPL) method to improve VLMs using unlabeled data. The key steps are:
-
Prompt Tuning: The researchers use prompt tuning to fine-tune the VLM on the unlabeled data. This allows the model to generate candidate pseudolabels (or predicted labels) for the unlabeled samples.
-
Pseudolabel Selection: The generated pseudolabels are then filtered and selected based on their confidence scores. This helps to identify high-quality pseudolabels that can be used to further fine-tune the VLM.
-
Model Fine-Tuning: The selected pseudolabels are used to fine-tune the VLM, effectively leveraging the unlabeled data to enhance the model's performance.
The authors demonstrate the effectiveness of CPL on various VLM benchmarks, showing that it can outperform previous state-of-the-art approaches while using less training data.
Critical Analysis
The paper presents a promising approach to enhancing VLMs using unlabeled data, but there are a few potential limitations and areas for further research:
-
The effectiveness of CPL may depend on the quality and diversity of the unlabeled data used. Further investigation is needed to understand the impact of the unlabeled dataset on the final model performance.
-
The pseudolabel selection process is a critical step in CPL, and the researchers' approach may not be optimal. Exploring alternative filtering and selection strategies could potentially improve the performance.
-
The paper focuses on improving VLM performance on standard benchmarks, but it would be interesting to see how CPL might translate to real-world applications and deployment scenarios.
Overall, the Candidate Pseudolabel Learning approach is a significant contribution to the field of vision-language modeling, and the ideas presented in the paper warrant further investigation and development.
Conclusion
The Candidate Pseudolabel Learning (CPL) method introduced in this paper offers a promising way to enhance vision-language models using unlabeled data. By leveraging prompt tuning to generate effective pseudolabels, CPL can boost VLM performance while requiring less labeled training data, a major advantage in real-world applications. While the paper highlights some potential limitations, the core ideas and insights presented here could have far-reaching impacts on the development of advanced AI systems that can understand and interact with the world in more natural and human-like ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Candidate Pseudolabel Learning: Enhancing Vision-Language Models by Prompt Tuning with Unlabeled Data
Jiahan Zhang, Qi Wei, Feng Liu, Lei Feng
Fine-tuning vision-language models (VLMs) with abundant unlabeled data recently has attracted increasing attention. Existing methods that resort to the pseudolabeling strategy would suffer from heavily incorrect hard pseudolabels when VLMs exhibit low zero-shot performance in downstream tasks. To alleviate this issue, we propose a Candidate Pseudolabel Learning method, termed CPL, to fine-tune VLMs with suitable candidate pseudolabels of unlabeled data in downstream tasks. The core of our method lies in the generation strategy of candidate pseudolabels, which progressively generates refined candidate pseudolabels by both intra- and inter-instance label selection, based on a confidence score matrix for all unlabeled data. This strategy can result in better performance in true label inclusion and class-balanced instance selection. In this way, we can directly apply existing loss functions to learn with generated candidate psueudolabels. Extensive experiments on nine benchmark datasets with three learning paradigms demonstrate the effectiveness of our method. Our code can be found at https://github.com/vanillaer/CPL-ICML2024.
Read more6/18/2024

0
Tuning Vision-Language Models with Candidate Labels by Prompt Alignment
Zhifang Zhang, Beibei Li
Vision-language models (VLMs) can learn high-quality representations from a large-scale training dataset of image-text pairs. Prompt learning is a popular approach to fine-tuning VLM to adapt them to downstream tasks. Despite the satisfying performance, a major limitation of prompt learning is the demand for labelled data. In real-world scenarios, we may only obtain candidate labels (where the true label is included) instead of the true labels due to data privacy or sensitivity issues. In this paper, we provide the first study on prompt learning with candidate labels for VLMs. We empirically demonstrate that prompt learning is more advantageous than other fine-tuning methods, for handling candidate labels. Nonetheless, its performance drops when the label ambiguity increases. In order to improve its robustness, we propose a simple yet effective framework that better leverages the prior knowledge of VLMs to guide the learning process with candidate labels. Specifically, our framework disambiguates candidate labels by aligning the model output with the mixed class posterior jointly predicted by both the learnable and the handcrafted prompt. Besides, our framework can be equipped with various off-the-shelf training objectives for learning with candidate labels to further improve their performance. Extensive experiments demonstrate the effectiveness of our proposed framework.
Read more7/12/2024
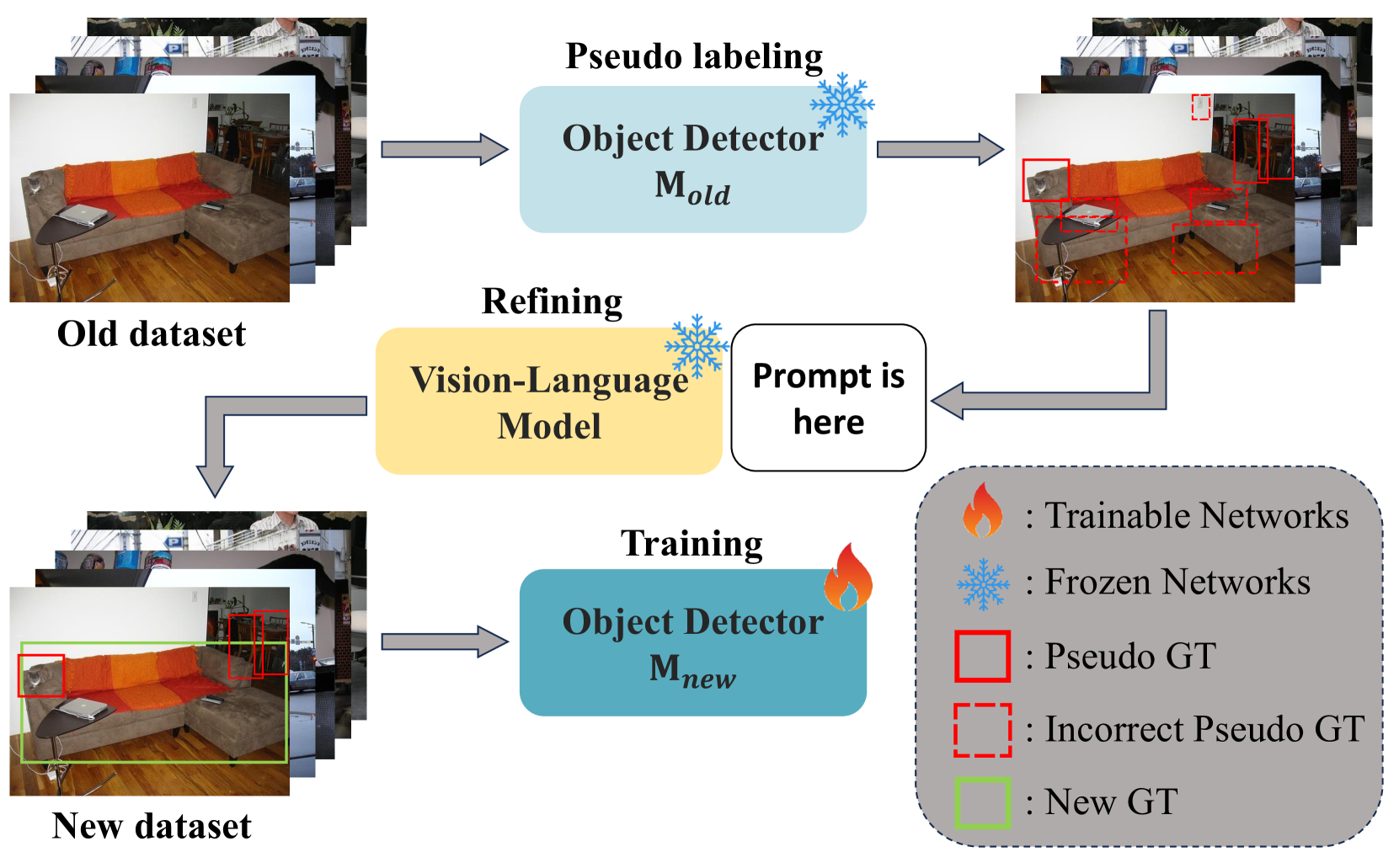
0
VLM-PL: Advanced Pseudo Labeling Approach for Class Incremental Object Detection via Vision-Language Model
Junsu Kim, Yunhoe Ku, Jihyeon Kim, Junuk Cha, Seungryul Baek
In the field of Class Incremental Object Detection (CIOD), creating models that can continuously learn like humans is a major challenge. Pseudo-labeling methods, although initially powerful, struggle with multi-scenario incremental learning due to their tendency to forget past knowledge. To overcome this, we introduce a new approach called Vision-Language Model assisted Pseudo-Labeling (VLM-PL). This technique uses Vision-Language Model (VLM) to verify the correctness of pseudo ground-truths (GTs) without requiring additional model training. VLM-PL starts by deriving pseudo GTs from a pre-trained detector. Then, we generate custom queries for each pseudo GT using carefully designed prompt templates that combine image and text features. This allows the VLM to classify the correctness through its responses. Furthermore, VLM-PL integrates refined pseudo and real GTs from upcoming training, effectively combining new and old knowledge. Extensive experiments conducted on the Pascal VOC and MS COCO datasets not only highlight VLM-PL's exceptional performance in multi-scenario but also illuminate its effectiveness in dual-scenario by achieving state-of-the-art results in both.
Read more5/10/2024

0
Training-Free Unsupervised Prompt for Vision-Language Models
Sifan Long, Linbin Wang, Zhen Zhao, Zichang Tan, Yiming Wu, Shengsheng Wang, Jingdong Wang
Prompt learning has become the most effective paradigm for adapting large pre-trained vision-language models (VLMs) to downstream tasks. Recently, unsupervised prompt tuning methods, such as UPL and POUF, directly leverage pseudo-labels as supervisory information to fine-tune additional adaptation modules on unlabeled data. However, inaccurate pseudo labels easily misguide the tuning process and result in poor representation capabilities. In light of this, we propose Training-Free Unsupervised Prompts (TFUP), which maximally preserves the inherent representation capabilities and enhances them with a residual connection to similarity-based prediction probabilities in a training-free and labeling-free manner. Specifically, we integrate both instance confidence and prototype scores to select representative samples, which are used to customize a reliable Feature Cache Model (FCM) for training-free inference. Then, we design a Multi-level Similarity Measure (MSM) that considers both feature-level and semantic-level similarities to calculate the distance between each test image and the cached sample as the weight of the corresponding cached label to generate similarity-based prediction probabilities. In this way, TFUP achieves surprising performance, even surpassing the training-base method on multiple classification datasets. Based on our TFUP, we propose a training-based approach (TFUP-T) to further boost the adaptation performance. In addition to the standard cross-entropy loss, TFUP-T adopts an additional marginal distribution entropy loss to constrain the model from a global perspective. Our TFUP-T achieves new state-of-the-art classification performance compared to unsupervised and few-shot adaptation approaches on multiple benchmarks. In particular, TFUP-T improves the classification accuracy of POUF by 3.3% on the most challenging Domain-Net dataset.
Read more4/26/2024