VLM-PL: Advanced Pseudo Labeling Approach for Class Incremental Object Detection via Vision-Language Model
2403.05346
0
0
Abstract
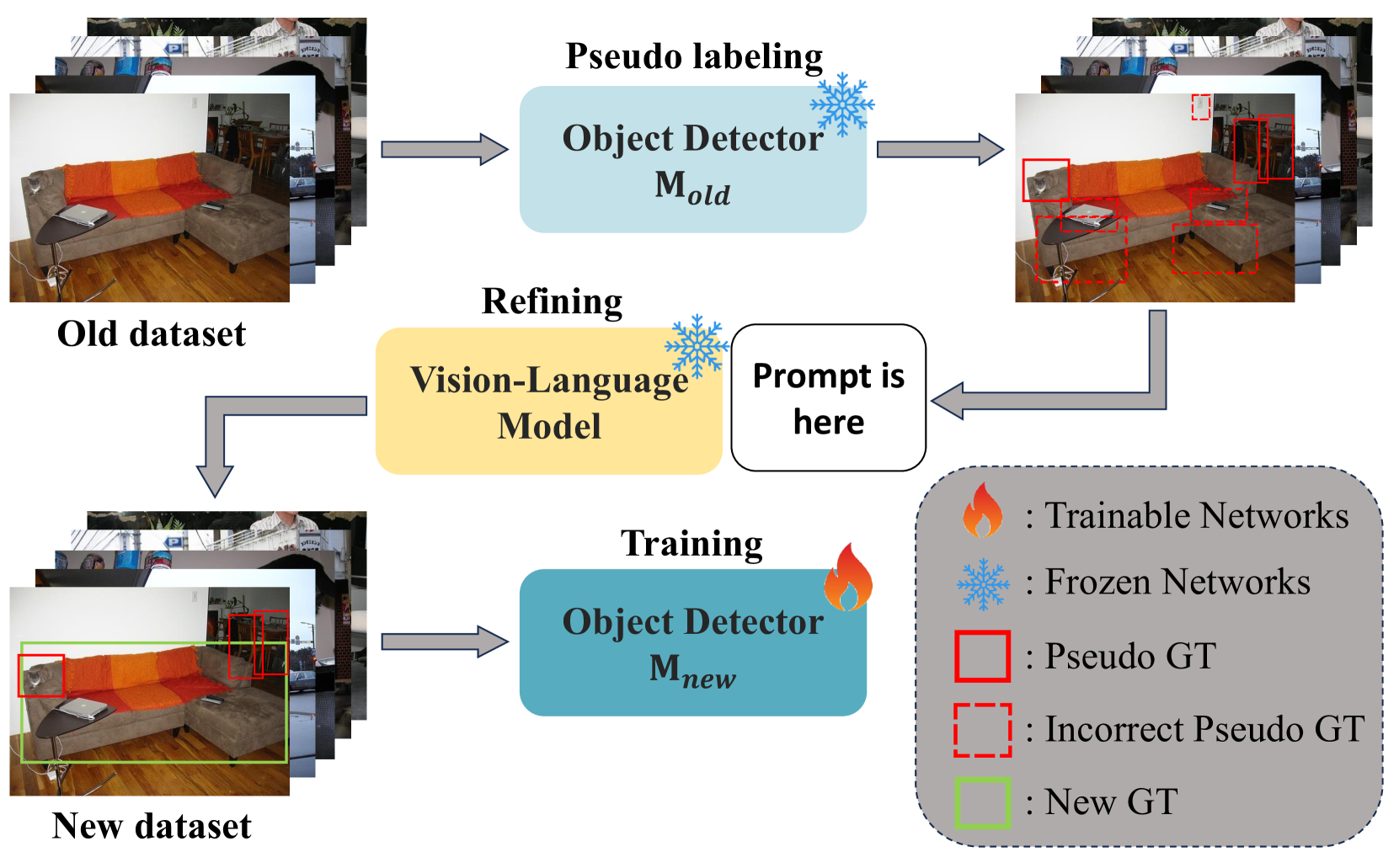
In the field of Class Incremental Object Detection (CIOD), creating models that can continuously learn like humans is a major challenge. Pseudo-labeling methods, although initially powerful, struggle with multi-scenario incremental learning due to their tendency to forget past knowledge. To overcome this, we introduce a new approach called Vision-Language Model assisted Pseudo-Labeling (VLM-PL). This technique uses Vision-Language Model (VLM) to verify the correctness of pseudo ground-truths (GTs) without requiring additional model training. VLM-PL starts by deriving pseudo GTs from a pre-trained detector. Then, we generate custom queries for each pseudo GT using carefully designed prompt templates that combine image and text features. This allows the VLM to classify the correctness through its responses. Furthermore, VLM-PL integrates refined pseudo and real GTs from upcoming training, effectively combining new and old knowledge. Extensive experiments conducted on the Pascal VOC and MS COCO datasets not only highlight VLM-PL's exceptional performance in multi-scenario but also illuminate its effectiveness in dual-scenario by achieving state-of-the-art results in both.
Create account to get full access
Overview
- This paper proposes a novel approach called VLM-PL (Vision-Language Model with Pseudo Labeling) for class-incremental object detection.
- The key idea is to leverage a pretrained vision-language model to generate pseudo-labels for novel classes, enabling the object detection model to learn and detect them without accessing the original training data.
- The method aims to address the challenge of continual learning in object detection, where the model needs to continuously expand its capabilities to detect new object classes without forgetting previous ones.
Plain English Explanation
The paper describes a new technique called VLM-PL that can help train object detection models to recognize more and more object classes over time, without forgetting the ones they've already learned. [This is similar to the task of enhancing interactive image retrieval with query rewriting using language models.]
The key insight is to use a pretrained vision-language model - a type of AI model that can understand both images and text - to generate pseudo-labels for new object classes. These pseudo-labels act as a substitute for the original training data, allowing the object detection model to learn the new classes without accessing the full dataset.
This is an important advancement, because traditional object detection models struggle to learn new classes without forgetting the old ones - a problem known as "catastrophic forgetting". By using pseudo-labels generated by the vision-language model, VLM-PL can expand the object detection model's capabilities over time, without causing it to forget what it has already learned. [This is similar to how language models can be used as black-box optimizers for vision tasks.]
Overall, the VLM-PL approach aims to make object detection models more robust and adaptable, allowing them to continuously expand their understanding of the visual world without losing previously acquired knowledge. This could have valuable applications in areas like robotics, self-driving cars, and smart assistants, where the ability to recognize a growing number of objects is crucial.
Technical Explanation
The VLM-PL approach consists of three key components:
-
Pretrained Vision-Language Model: The system leverages a pretrained vision-language model, such as CLIP or CrayoN, which has been trained to understand the relationship between visual and textual information. This model is used to generate pseudo-labels for novel object classes.
-
Pseudo-Labeling: When presented with a new object class, the vision-language model is used to generate pseudo-labels for the images in the incremental dataset. These pseudo-labels provide the object detection model with a synthetic training signal for the novel class, without requiring access to the original training data.
-
Class-Incremental Object Detection: The object detection model is then fine-tuned on the combination of the original dataset and the pseudo-labeled incremental data. This allows the model to expand its capabilities to detect the new object class, while also preserving its performance on the previously learned classes.
The paper presents extensive experiments evaluating the VLM-PL approach on several benchmark datasets, including PASCAL VOC and MS-COCO. The results demonstrate that VLM-PL significantly outperforms traditional class-incremental learning techniques, achieving high detection accuracy on both old and new object classes.
Critical Analysis
The paper makes a compelling case for the VLM-PL approach, and the experimental results are quite promising. However, there are a few potential limitations and areas for further research that could be explored:
-
Dependence on Pretrained Vision-Language Model: The performance of VLM-PL is heavily dependent on the quality and capabilities of the underlying vision-language model. If the pretrained model has limitations or biases, this could be reflected in the pseudo-labels and impact the object detection model's performance.
-
Scalability to Large-Scale Datasets: The experiments in the paper were conducted on relatively small-scale datasets. It's unclear how well the VLM-PL approach would scale to larger, more diverse datasets with a broader range of object classes.
-
Robustness to Noisy or Imperfect Pseudo-Labels: The pseudo-labels generated by the vision-language model may not be perfect, especially for more challenging or ambiguous object classes. It would be valuable to investigate the method's resilience to noise or errors in the pseudo-labels.
-
Computational Efficiency: The use of a pretrained vision-language model and the pseudo-labeling process may introduce additional computational overhead compared to more traditional class-incremental learning approaches. The trade-offs between performance and efficiency should be further explored.
Despite these potential limitations, the VLM-PL approach represents an exciting and promising direction for addressing the challenge of class-incremental object detection. As the field of continual learning continues to evolve, techniques like VLM-PL could play a crucial role in developing more adaptable and capable object detection systems.
Conclusion
The VLM-PL paper presents a novel approach to class-incremental object detection that leverages the power of pretrained vision-language models to generate pseudo-labels for novel object classes. This enables the object detection model to continuously expand its capabilities without forgetting previously learned classes, a critical challenge in the field of continual learning.
The experimental results demonstrate the effectiveness of the VLM-PL approach, which outperforms traditional class-incremental learning techniques. While the method has some potential limitations, it represents an important step towards developing more robust and adaptable object detection systems that can keep pace with the ever-evolving visual world.
As the field of computer vision continues to advance, techniques like VLM-PL could have far-reaching implications for a wide range of applications, from autonomous vehicles and robotics to smart assistants and beyond. By harnessing the power of vision-language models, researchers are unlocking new possibilities for object detection and paving the way for more intelligent and adaptable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Candidate Pseudolabel Learning: Enhancing Vision-Language Models by Prompt Tuning with Unlabeled Data
Jiahan Zhang, Qi Wei, Feng Liu, Lei Feng
0
0
Fine-tuning vision-language models (VLMs) with abundant unlabeled data recently has attracted increasing attention. Existing methods that resort to the pseudolabeling strategy would suffer from heavily incorrect hard pseudolabels when VLMs exhibit low zero-shot performance in downstream tasks. To alleviate this issue, we propose a Candidate Pseudolabel Learning method, termed CPL, to fine-tune VLMs with suitable candidate pseudolabels of unlabeled data in downstream tasks. The core of our method lies in the generation strategy of candidate pseudolabels, which progressively generates refined candidate pseudolabels by both intra- and inter-instance label selection, based on a confidence score matrix for all unlabeled data. This strategy can result in better performance in true label inclusion and class-balanced instance selection. In this way, we can directly apply existing loss functions to learn with generated candidate psueudolabels. Extensive experiments on nine benchmark datasets with three learning paradigms demonstrate the effectiveness of our method. Our code can be found at https://github.com/vanillaer/CPL-ICML2024.
6/18/2024
The Solution for CVPR2024 Foundational Few-Shot Object Detection Challenge
Hongpeng Pan, Shifeng Yi, Shouwei Yang, Lei Qi, Bing Hu, Yi Xu, Yang Yang
0
0
This report introduces an enhanced method for the Foundational Few-Shot Object Detection (FSOD) task, leveraging the vision-language model (VLM) for object detection. However, on specific datasets, VLM may encounter the problem where the detected targets are misaligned with the target concepts of interest. This misalignment hinders the zero-shot performance of VLM and the application of fine-tuning methods based on pseudo-labels. To address this issue, we propose the VLM+ framework, which integrates the multimodal large language model (MM-LLM). Specifically, we use MM-LLM to generate a series of referential expressions for each category. Based on the VLM predictions and the given annotations, we select the best referential expression for each category by matching the maximum IoU. Subsequently, we use these referential expressions to generate pseudo-labels for all images in the training set and then combine them with the original labeled data to fine-tune the VLM. Additionally, we employ iterative pseudo-label generation and optimization to further enhance the performance of the VLM. Our approach achieve 32.56 mAP in the final test.
6/19/2024
✨
Leveraging VLM-Based Pipelines to Annotate 3D Objects
Rishabh Kabra, Loic Matthey, Alexander Lerchner, Niloy J. Mitra
0
0
Pretrained vision language models (VLMs) present an opportunity to caption unlabeled 3D objects at scale. The leading approach to summarize VLM descriptions from different views of an object (Luo et al., 2023) relies on a language model (GPT4) to produce the final output. This text-based aggregation is susceptible to hallucinations as it merges potentially contradictory descriptions. We propose an alternative algorithm to marginalize over factors such as the viewpoint that affect the VLM's response. Instead of merging text-only responses, we utilize the VLM's joint image-text likelihoods. We show our probabilistic aggregation is not only more reliable and efficient, but sets the SoTA on inferring object types with respect to human-verified labels. The aggregated annotations are also useful for conditional inference; they improve downstream predictions (e.g., of object material) when the object's type is specified as an auxiliary text-based input. Such auxiliary inputs allow ablating the contribution of visual reasoning over visionless reasoning in an unsupervised setting. With these supervised and unsupervised evaluations, we show how a VLM-based pipeline can be leveraged to produce reliable annotations for 764K objects from the Objaverse dataset.
6/18/2024
Harnessing the Power of Large Vision Language Models for Synthetic Image Detection
Mamadou Keita, Wassim Hamidouche, Hassen Bougueffa, Abdenour Hadid, Abdelmalik Taleb-Ahmed
0
0
In recent years, the emergence of models capable of generating images from text has attracted considerable interest, offering the possibility of creating realistic images from text descriptions. Yet these advances have also raised concerns about the potential misuse of these images, including the creation of misleading content such as fake news and propaganda. This study investigates the effectiveness of using advanced vision-language models (VLMs) for synthetic image identification. Specifically, the focus is on tuning state-of-the-art image captioning models for synthetic image detection. By harnessing the robust understanding capabilities of large VLMs, the aim is to distinguish authentic images from synthetic images produced by diffusion-based models. This study contributes to the advancement of synthetic image detection by exploiting the capabilities of visual language models such as BLIP-2 and ViTGPT2. By tailoring image captioning models, we address the challenges associated with the potential misuse of synthetic images in real-world applications. Results described in this paper highlight the promising role of VLMs in the field of synthetic image detection, outperforming conventional image-based detection techniques. Code and models can be found at https://github.com/Mamadou-Keita/VLM-DETECT.
4/4/2024