A Canonization Perspective on Invariant and Equivariant Learning
2405.18378
0
0
🎯
Abstract
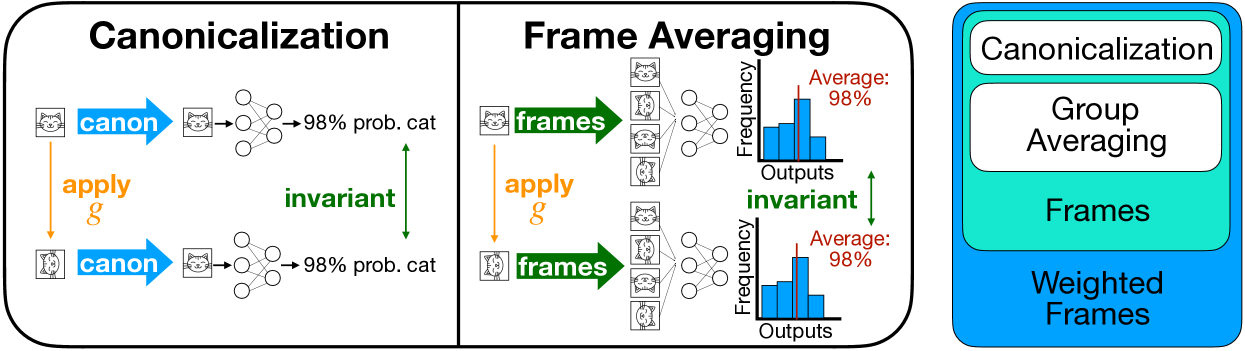
In many applications, we desire neural networks to exhibit invariance or equivariance to certain groups due to symmetries inherent in the data. Recently, frame-averaging methods emerged to be a unified framework for attaining symmetries efficiently by averaging over input-dependent subsets of the group, i.e., frames. What we currently lack is a principled understanding of the design of frames. In this work, we introduce a canonization perspective that provides an essential and complete view of the design of frames. Canonization is a classic approach for attaining invariance by mapping inputs to their canonical forms. We show that there exists an inherent connection between frames and canonical forms. Leveraging this connection, we can efficiently compare the complexity of frames as well as determine the optimality of certain frames. Guided by this principle, we design novel frames for eigenvectors that are strictly superior to existing methods -- some are even optimal -- both theoretically and empirically. The reduction to the canonization perspective further uncovers equivalences between previous methods. These observations suggest that canonization provides a fundamental understanding of existing frame-averaging methods and unifies existing equivariant and invariant learning methods.
Create account to get full access
Overview
- Neural networks can be designed to be invariant or equivariant to certain input transformations, which is important for many applications.
- Frame-averaging methods have emerged as a way to efficiently attain these symmetries by averaging over input-dependent subsets of the transformation group.
- However, the design of these frames has lacked a principled understanding, which this paper aims to address.
Plain English Explanation
The paper introduces a new perspective on designing neural networks that can exhibit invariance or equivariance to certain input transformations. This is an important capability for many real-world applications, where the neural network needs to be able to recognize patterns that are the same despite changes in the input, like rotations or translations.
The key idea is to use a technique called "frame-averaging," which involves averaging the network's output over a subset of the possible input transformations. This helps the network learn to be invariant or equivariant to those transformations. However, the design of these "frames" has been a bit of a mystery up until now.
The paper shows that there is a deep connection between these frames and a classic technique called "canonicalization," which maps inputs to a standard or "canonical" form. By understanding this connection, the researchers were able to develop a principled way to design frames that are optimal or most efficient for attaining the desired symmetries.
Using this new perspective, the researchers were able to design novel frames for a specific type of neural network that outperform existing methods, both in theory and in practice. They also show how this canonicalization view can help unify and explain many of the existing techniques for building equivariant and invariant neural networks.
Technical Explanation
The key technical contribution of the paper is introducing a "canonicalization" perspective on the design of frames for frame-averaging methods. Canonicalization is a classic approach for attaining invariance by mapping inputs to a canonical form, and the paper shows that there is an inherent connection between canonicalization and the design of frames.
Specifically, the authors demonstrate that the complexity of a frame can be quantified by the complexity of the corresponding canonicalization mapping. This allows them to efficiently compare different frame designs and determine the optimality of certain frames. Guided by this principle, the researchers design novel frames for eigenvectors that are theoretically and empirically superior to existing methods, with some even being optimal.
Furthermore, the reduction to the canonicalization perspective uncovers equivalences between previous frame-averaging and equivariant/invariant learning methods. This suggests that the canonicalization view provides a fundamental understanding of frame-averaging approaches and helps unify the field.
Critical Analysis
The paper provides a solid theoretical foundation for understanding the design of frames in frame-averaging methods, which is an important step forward for the field. The canonicalization perspective offers a principled way to analyze and optimize frame designs, which is a significant contribution.
That said, the paper does not address some potential limitations or areas for further research. For example, it would be interesting to explore how the canonicalization view applies to more complex transformation groups beyond just eigenvectors. Additionally, the paper focuses on the theoretical and empirical performance of the novel frame designs, but does not delve into the practical implications or ease of deployment in real-world applications.
Overall, this research represents an important advance in the understanding and design of equivariant and invariant neural networks. By linking frame-averaging to the well-established concept of canonicalization, the paper lays the groundwork for further improvements and innovations in this area.
Conclusion
This paper introduces a canonicalization perspective that provides a principled framework for understanding and designing frames in the context of frame-averaging methods for attaining symmetries in neural networks. By leveraging the connection between frames and canonical forms, the researchers were able to devise novel, theoretically and empirically superior frame designs for eigenvectors.
The canonicalization view also helps unify and explain existing equivariant and invariant learning techniques, suggesting that it offers a fundamental understanding of this important area of research. While the paper does not address all potential limitations, it represents a significant step forward in the design of symmetry-aware neural networks, which have widespread applications in fields like computer vision, robotics, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Equivariant Frames and the Impossibility of Continuous Canonicalization
Nadav Dym, Hannah Lawrence, Jonathan W. Siegel
0
0
Canonicalization provides an architecture-agnostic method for enforcing equivariance, with generalizations such as frame-averaging recently gaining prominence as a lightweight and flexible alternative to equivariant architectures. Recent works have found an empirical benefit to using probabilistic frames instead, which learn weighted distributions over group elements. In this work, we provide strong theoretical justification for this phenomenon: for commonly-used groups, there is no efficiently computable choice of frame that preserves continuity of the function being averaged. In other words, unweighted frame-averaging can turn a smooth, non-symmetric function into a discontinuous, symmetric function. To address this fundamental robustness problem, we formally define and construct emph{weighted} frames, which provably preserve continuity, and demonstrate their utility by constructing efficient and continuous weighted frames for the actions of $SO(2)$, $SO(3)$, and $S_n$ on point clouds.
6/19/2024
📈
Improved Canonicalization for Model Agnostic Equivariance
Siba Smarak Panigrahi, Arnab Kumar Mondal
0
0
This work introduces a novel approach to achieving architecture-agnostic equivariance in deep learning, particularly addressing the limitations of traditional equivariant architectures and the inefficiencies of the existing architecture-agnostic methods. Building equivariant models using traditional methods requires designing equivariant versions of existing models and training them from scratch, a process that is both impractical and resource-intensive. Canonicalization has emerged as a promising alternative for inducing equivariance without altering model architecture, but it suffers from the need for highly expressive and expensive equivariant networks to learn canonical orientations accurately. We propose a new method that employs any non-equivariant network for canonicalization. Our method uses contrastive learning to efficiently learn a unique canonical orientation and offers more flexibility for the choice of canonicalization network. We empirically demonstrate that this approach outperforms existing methods in achieving equivariance for large pretrained models and significantly speeds up the canonicalization process, making it up to 2 times faster.
5/24/2024
🤷
Unsupervised Learning of Group Invariant and Equivariant Representations
Robin Winter, Marco Bertolini, Tuan Le, Frank No'e, Djork-Arn'e Clevert
0
0
Equivariant neural networks, whose hidden features transform according to representations of a group G acting on the data, exhibit training efficiency and an improved generalisation performance. In this work, we extend group invariant and equivariant representation learning to the field of unsupervised deep learning. We propose a general learning strategy based on an encoder-decoder framework in which the latent representation is separated in an invariant term and an equivariant group action component. The key idea is that the network learns to encode and decode data to and from a group-invariant representation by additionally learning to predict the appropriate group action to align input and output pose to solve the reconstruction task. We derive the necessary conditions on the equivariant encoder, and we present a construction valid for any G, both discrete and continuous. We describe explicitly our construction for rotations, translations and permutations. We test the validity and the robustness of our approach in a variety of experiments with diverse data types employing different network architectures.
4/15/2024
✨
The Lie Derivative for Measuring Learned Equivariance
Nate Gruver, Marc Finzi, Micah Goldblum, Andrew Gordon Wilson
0
0
Equivariance guarantees that a model's predictions capture key symmetries in data. When an image is translated or rotated, an equivariant model's representation of that image will translate or rotate accordingly. The success of convolutional neural networks has historically been tied to translation equivariance directly encoded in their architecture. The rising success of vision transformers, which have no explicit architectural bias towards equivariance, challenges this narrative and suggests that augmentations and training data might also play a significant role in their performance. In order to better understand the role of equivariance in recent vision models, we introduce the Lie derivative, a method for measuring equivariance with strong mathematical foundations and minimal hyperparameters. Using the Lie derivative, we study the equivariance properties of hundreds of pretrained models, spanning CNNs, transformers, and Mixer architectures. The scale of our analysis allows us to separate the impact of architecture from other factors like model size or training method. Surprisingly, we find that many violations of equivariance can be linked to spatial aliasing in ubiquitous network layers, such as pointwise non-linearities, and that as models get larger and more accurate they tend to display more equivariance, regardless of architecture. For example, transformers can be more equivariant than convolutional neural networks after training.
6/19/2024