CAPE: Context-Adaptive Positional Encoding for Length Extrapolation
2405.14722
0
0
⛏️
Abstract
Positional encoding plays a crucial role in transformers, significantly impacting model performance and length generalization. Prior research has introduced absolute positional encoding (APE) and relative positional encoding (RPE) to distinguish token positions in given sequences. However, both APE and RPE remain fixed after model training regardless of input data, limiting their adaptability and flexibility. Hence, we expect that the desired positional encoding should be context-adaptive and can be dynamically adjusted with the given attention. In this paper, we propose a Context-Adaptive Positional Encoding (CAPE) method, which dynamically and semantically adjusts based on input context and learned fixed priors. Experimental validation on real-world datasets (Arxiv, Books3, and CHE) demonstrates that CAPE enhances model performances in terms of trained length and length generalization, where the improvements are statistically significant. The model visualization suggests that our model can keep both local and anti-local information. Finally, we successfully train the model on sequence length 128 and achieve better performance at evaluation sequence length 8192, compared with other static positional encoding methods, revealing the benefit of the adaptive positional encoding method.
Create account to get full access
Overview
- Positional encoding plays a crucial role in transformers, significantly impacting model performance and length generalization
- Prior research has introduced absolute positional encoding (APE) and relative positional encoding (RPE) to distinguish token positions
- However, APE and RPE remain fixed after model training, limiting their adaptability and flexibility
- The paper proposes a Context-Adaptive Positional Encoding (CAPE) method, which dynamically and semantically adjusts based on input context and learned fixed priors
Plain English Explanation
Positional encoding is an important part of transformer models, as it helps the model understand the position of each word or token in a sequence. Prior techniques like absolute positional encoding and relative positional encoding have been used, but they remain fixed after the model is trained.
The paper proposes a new method called Context-Adaptive Positional Encoding (CAPE), which can dynamically adjust the positional encoding based on the input context. This allows the model to be more flexible and adaptable, which can lead to better performance, especially when it comes to generalizing to longer sequences.
The key idea is that the positional encoding should be "context-adaptive" - it should change based on the specific input the model is processing, rather than being a fixed encoding. This allows the model to better capture the relationships between the positions of tokens in a given sequence.
Technical Explanation
The paper introduces the Context-Adaptive Positional Encoding (CAPE) method, which dynamically adjusts the positional encoding based on the input context. This is in contrast to previous approaches like absolute positional encoding and relative positional encoding, which use fixed encodings.
The CAPE method learns a set of fixed priors that capture general positional information, and then dynamically combines these priors with the current input context to generate the final positional encoding. This allows the model to benefit from both the general positional knowledge encoded in the priors, as well as the specific context of the current input.
Experimental results on various datasets, including Arxiv, Books3, and CHE, demonstrate that CAPE outperforms other positional encoding methods in terms of both trained length and length generalization. The authors also provide visualizations showing that CAPE is able to capture both local and anti-local positional information.
Additionally, the authors show that CAPE can be used to train models on sequence length 128 and achieve better performance at evaluation sequence length 8192, compared to other static positional encoding methods. This highlights the benefits of the adaptive positional encoding approach.
Critical Analysis
The paper presents a promising approach to address the limitations of existing positional encoding methods. By making the positional encoding adaptive to the input context, CAPE allows for more flexibility and potentially better performance, especially in tasks that require generalization to longer sequences.
However, the paper does not deeply explore the potential downsides or limitations of the CAPE method. For example, it would be interesting to understand how the method scales to very long sequences, or how it performs in different types of tasks beyond the specific datasets evaluated.
Additionally, the paper could have provided more analysis on the specific mechanisms by which CAPE is able to capture both local and anti-local positional information. A deeper dive into the inner workings of the method would help readers better understand its strengths and weaknesses.
Overall, the paper makes a compelling case for the CAPE approach and its potential benefits, but further research and analysis could help strengthen the conclusions and provide a more well-rounded understanding of the method.
Conclusion
The paper proposes a novel Context-Adaptive Positional Encoding (CAPE) method that dynamically adjusts the positional encoding based on the input context. This contrasts with previous fixed positional encoding approaches, which can limit the model's adaptability and flexibility.
The experimental results demonstrate that CAPE can significantly improve model performance and length generalization, suggesting that adaptive positional encoding is a promising direction for enhancing transformer-based models. The ability to train on shorter sequences and achieve better performance on longer sequences is a particularly noteworthy benefit of the CAPE method.
Overall, this research highlights the importance of positional encoding in transformer models and introduces a novel, context-adaptive approach that could have far-reaching implications for a wide range of natural language processing and other sequence-to-sequence tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Comparing Graph Transformers via Positional Encodings
Mitchell Black, Zhengchao Wan, Gal Mishne, Amir Nayyeri, Yusu Wang
0
0
The distinguishing power of graph transformers is closely tied to the choice of positional encoding: features used to augment the base transformer with information about the graph. There are two primary types of positional encoding: absolute positional encodings (APEs) and relative positional encodings (RPEs). APEs assign features to each node and are given as input to the transformer. RPEs instead assign a feature to each pair of nodes, e.g., graph distance, and are used to augment the attention block. A priori, it is unclear which method is better for maximizing the power of the resulting graph transformer. In this paper, we aim to understand the relationship between these different types of positional encodings. Interestingly, we show that graph transformers using APEs and RPEs are equivalent in terms of distinguishing power. In particular, we demonstrate how to interchange APEs and RPEs while maintaining their distinguishing power in terms of graph transformers. Based on our theoretical results, we provide a study on several APEs and RPEs (including the resistance distance and the recently introduced stable and expressive positional encoding (SPE)) and compare their distinguishing power in terms of transformers. We believe our work will help navigate the huge number of choices of positional encoding and will provide guidance on the future design of positional encodings for graph transformers.
6/6/2024
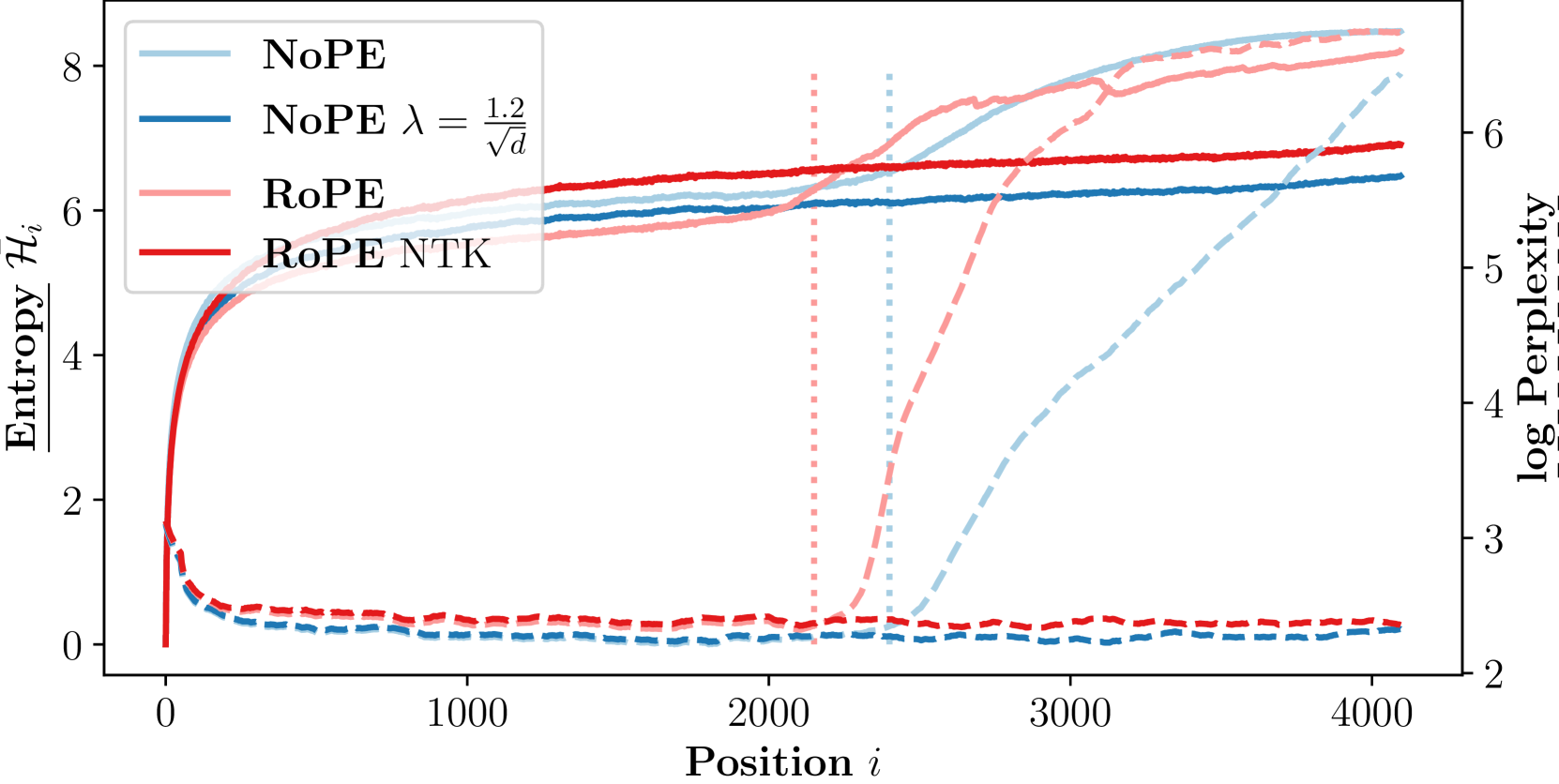
Length Generalization of Causal Transformers without Position Encoding
Jie Wang, Tao Ji, Yuanbin Wu, Hang Yan, Tao Gui, Qi Zhang, Xuanjing Huang, Xiaoling Wang
0
0
Generalizing to longer sentences is important for recent Transformer-based language models. Besides algorithms manipulating explicit position features, the success of Transformers without position encodings (NoPE) provides a new way to overcome the challenge. In this paper, we study the length generalization property of NoPE. We find that although NoPE can extend to longer sequences than the commonly used explicit position encodings, it still has a limited context length. We identify a connection between the failure of NoPE's generalization and the distraction of attention distributions. We propose a parameter-efficient tuning for searching attention heads' best temperature hyper-parameters, which substantially expands NoPE's context size. Experiments on long sequence language modeling, the synthetic passkey retrieval task and real-world long context tasks show that NoPE can achieve competitive performances with state-of-the-art length generalization algorithms. The source code is publicly accessible
5/29/2024
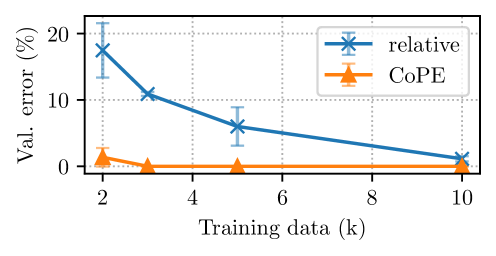
Contextual Position Encoding: Learning to Count What's Important
Olga Golovneva, Tianlu Wang, Jason Weston, Sainbayar Sukhbaatar
0
0
The attention mechanism is a critical component of Large Language Models (LLMs) that allows tokens in a sequence to interact with each other, but is order-invariant. Incorporating position encoding (PE) makes it possible to address by position, such as attending to the i-th token. However, current PE methods use token counts to derive position, and thus cannot generalize to higher levels of abstraction, such as attending to the i-th sentence. In this paper, we propose a new position encoding method, Contextual Position Encoding (CoPE), that allows positions to be conditioned on context by incrementing position only on certain tokens determined by the model. This allows more general position addressing such as attending to the $i$-th particular word, noun, or sentence. We show that CoPE can solve the selective copy, counting and Flip-Flop tasks where popular position embeddings fail, and improves perplexity on language modeling and coding tasks.
5/31/2024

Length Extrapolation of Transformers: A Survey from the Perspective of Positional Encoding
Liang Zhao, Xiaocheng Feng, Xiachong Feng, Dongliang Xu, Qing Yang, Hongtao Liu, Bing Qin, Ting Liu
0
0
Transformer has taken the field of natural language processing (NLP) by storm since its birth. Further, Large language models (LLMs) built upon it have captured worldwide attention due to its superior abilities. Nevertheless, all Transformer-based models including these powerful LLMs suffer from a preset length limit and can hardly generalize from short training sequences to longer inference ones, namely, they can not perform length extrapolation. Hence, a plethora of methods have been proposed to enhance length extrapolation of Transformer, in which the positional encoding (PE) is recognized as the major factor. In this survey, we present these advances towards length extrapolation in a unified notation from the perspective of PE. Specifically, we first introduce extrapolatable PEs, including absolute and relative PEs. Then, we dive into extrapolation methods based on them, covering position interpolation and randomized position methods. Finally, several challenges and future directions in this area are highlighted. Through this survey, We aim to enable the reader to gain a deep understanding of existing methods and provide stimuli for future research.
4/3/2024