Co-driver: VLM-based Autonomous Driving Assistant with Human-like Behavior and Understanding for Complex Road Scenes
2405.05885
0
0
🤔
Abstract
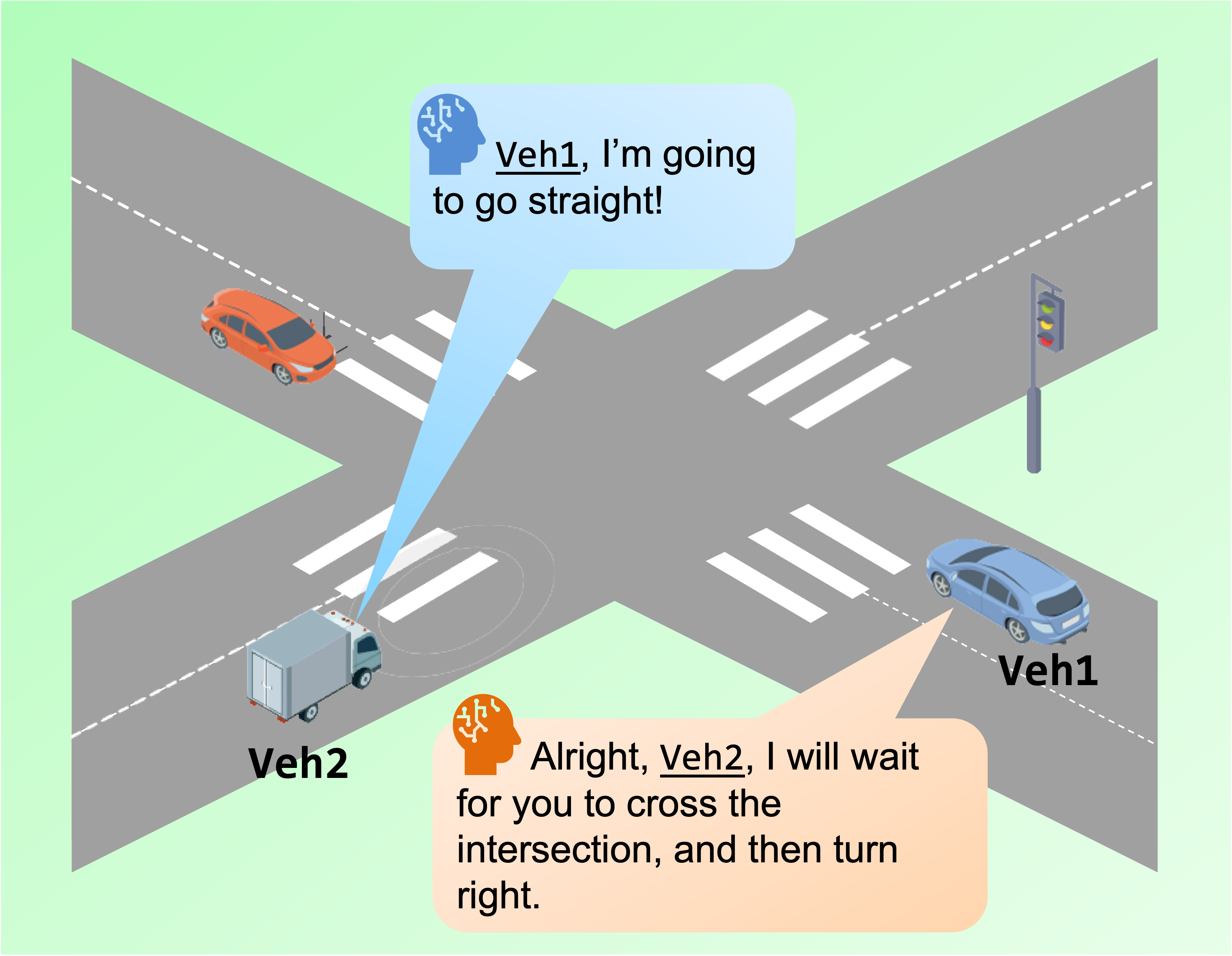
Recent research about Large Language Model based autonomous driving solutions shows a promising picture in planning and control fields. However, heavy computational resources and hallucinations of Large Language Models continue to hinder the tasks of predicting precise trajectories and instructing control signals. To address this problem, we propose Co-driver, a novel autonomous driving assistant system to empower autonomous vehicles with adjustable driving behaviors based on the understanding of road scenes. A pipeline involving the CARLA simulator and Robot Operating System 2 (ROS2) verifying the effectiveness of our system is presented, utilizing a single Nvidia 4090 24G GPU while exploiting the capacity of textual output of the Visual Language Model. Besides, we also contribute a dataset containing an image set and a corresponding prompt set for fine-tuning the Visual Language Model module of our system. In the real-world driving dataset, our system achieved 96.16% success rate in night scenes and 89.7% in gloomy scenes regarding reasonable predictions. Our Co-driver dataset will be released at https://github.com/ZionGo6/Co-driver.
Create account to get full access
Overview
- Addresses limitations of large language models in autonomous driving tasks
- Proposes "Co-driver", a system that uses a visual language model to empower autonomous vehicles with adjustable driving behaviors
- Validated the system using the CARLA simulator and ROS2, with promising results in night and gloomy driving scenarios
Plain English Explanation
This research paper explores the use of large language models (LLMs) for autonomous driving. While LLMs have shown promise in planning and control tasks, the researchers identify two key challenges: heavy computational resources and the potential for LLMs to "hallucinate" - or output incorrect information.
To address these issues, the researchers propose a new system called "Co-driver". This system utilizes a visual language model, which is trained to understand and interpret road scenes, to provide adjustable driving behaviors for autonomous vehicles. By combining the textual output of the visual language model with other sensors and systems, Co-driver aims to improve the accuracy and reliability of autonomous driving, particularly in challenging environments like nighttime or gloomy conditions.
The researchers validate their system using the CARLA simulator and the Robot Operating System 2 (ROS2) framework, leveraging a single powerful Nvidia GPU. They also contribute a new dataset containing images and corresponding prompts for fine-tuning the visual language model.
In real-world driving scenarios, the Co-driver system achieved impressive success rates of 96.16% in night scenes and 89.7% in gloomy scenes, demonstrating its potential to enhance the capabilities of autonomous vehicles.
Technical Explanation
The paper proposes the Co-driver system as a solution to the limitations of LLMs in autonomous driving tasks. The system utilizes a visual language model to understand and interpret road scenes, which is then used to provide adjustable driving behaviors for autonomous vehicles.
The researchers validated their system using the CARLA simulator and the ROS2 framework, leveraging a single Nvidia 4090 24G GPU. This setup allowed them to exploit the capacity of the visual language model's textual output while maintaining reasonable computational requirements.
Additionally, the researchers contributed a dataset containing an image set and a corresponding prompt set for fine-tuning the visual language model module of their system. This dataset, called the "Co-driver dataset", will be publicly released to support further research in this area.
The real-world driving tests conducted by the researchers demonstrated the effectiveness of their system, with success rates of 96.16% in night scenes and 89.7% in gloomy scenes. These results suggest that the Co-driver system has the potential to enhance the performance of autonomous vehicles, particularly in challenging environmental conditions.
Critical Analysis
The research paper presents a promising approach to addressing the limitations of LLMs in autonomous driving. By leveraging a visual language model to interpret road scenes and provide adjustable driving behaviors, the Co-driver system aims to improve the accuracy and reliability of autonomous driving.
However, the paper does not delve deeply into the potential limitations or caveats of the proposed system. For example, it does not discuss the impact of edge cases or rare scenarios that the visual language model may struggle to handle, or the potential for bias or inconsistencies in the system's decision-making.
Additionally, while the researchers report impressive success rates in their real-world driving tests, more comprehensive evaluation of the system's performance across a broader range of conditions and scenarios would be valuable to fully assess its capabilities and limitations.
Lastly, the researchers mention the potential for large language model-based policy adaptation in autonomous driving, but do not explore this concept in depth within the current paper. Further research into how LLMs can be leveraged as "world models" to guide the decision-making of autonomous vehicles could provide additional insights and opportunities for improvement.
Conclusion
The Co-driver system presented in this research paper offers a promising approach to addressing the limitations of LLMs in autonomous driving tasks. By utilizing a visual language model to interpret road scenes and inform adjustable driving behaviors, the system demonstrates the potential to enhance the performance and reliability of autonomous vehicles, particularly in challenging environmental conditions.
While the paper presents encouraging results, further research is needed to fully explore the system's capabilities, limitations, and potential areas for improvement. Comprehensive evaluation, addressing edge cases, and investigating the integration of LLMs as "world models" for autonomous driving could help to further advance this area of research and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
AgentsCoDriver: Large Language Model Empowered Collaborative Driving with Lifelong Learning
Senkang Hu, Zhengru Fang, Zihan Fang, Yiqin Deng, Xianhao Chen, Yuguang Fang
0
0
Connected and autonomous driving is developing rapidly in recent years. However, current autonomous driving systems, which are primarily based on data-driven approaches, exhibit deficiencies in interpretability, generalization, and continuing learning capabilities. In addition, the single-vehicle autonomous driving systems lack of the ability of collaboration and negotiation with other vehicles, which is crucial for the safety and efficiency of autonomous driving systems. In order to address these issues, we leverage large language models (LLMs) to develop a novel framework, AgentsCoDriver, to enable multiple vehicles to conduct collaborative driving. AgentsCoDriver consists of five modules: observation module, reasoning engine, cognitive memory module, reinforcement reflection module, and communication module. It can accumulate knowledge, lessons, and experiences over time by continuously interacting with the environment, thereby making itself capable of lifelong learning. In addition, by leveraging the communication module, different agents can exchange information and realize negotiation and collaboration in complex traffic environments. Extensive experiments are conducted and show the superiority of AgentsCoDriver.
4/23/2024
👁️
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, Hang Zhao
0
0
A primary hurdle of autonomous driving in urban environments is understanding complex and long-tail scenarios, such as challenging road conditions and delicate human behaviors. We introduce DriveVLM, an autonomous driving system leveraging Vision-Language Models (VLMs) for enhanced scene understanding and planning capabilities. DriveVLM integrates a unique combination of reasoning modules for scene description, scene analysis, and hierarchical planning. Furthermore, recognizing the limitations of VLMs in spatial reasoning and heavy computational requirements, we propose DriveVLM-Dual, a hybrid system that synergizes the strengths of DriveVLM with the traditional autonomous driving pipeline. Experiments on both the nuScenes dataset and our SUP-AD dataset demonstrate the efficacy of DriveVLM and DriveVLM-Dual in handling complex and unpredictable driving conditions. Finally, we deploy the DriveVLM-Dual on a production vehicle, verifying it is effective in real-world autonomous driving environments.
6/26/2024
Personalized Autonomous Driving with Large Language Models: Field Experiments
Can Cui, Zichong Yang, Yupeng Zhou, Yunsheng Ma, Juanwu Lu, Lingxi Li, Yaobin Chen, Jitesh Panchal, Ziran Wang
0
0
Integrating large language models (LLMs) in autonomous vehicles enables conversation with AI systems to drive the vehicle. However, it also emphasizes the requirement for such systems to comprehend commands accurately and achieve higher-level personalization to adapt to the preferences of drivers or passengers over a more extended period. In this paper, we introduce an LLM-based framework, Talk2Drive, capable of translating natural verbal commands into executable controls and learning to satisfy personal preferences for safety, efficiency, and comfort with a proposed memory module. This is the first-of-its-kind multi-scenario field experiment that deploys LLMs on a real-world autonomous vehicle. Experiments showcase that the proposed system can comprehend human intentions at different intuition levels, ranging from direct commands like can you drive faster to indirect commands like I am really in a hurry now. Additionally, we use the takeover rate to quantify the trust of human drivers in the LLM-based autonomous driving system, where Talk2Drive significantly reduces the takeover rate in highway, intersection, and parking scenarios. We also validate that the proposed memory module considers personalized preferences and further reduces the takeover rate by up to 65.2% compared with those without a memory module. The experiment video can be watched at https://www.youtube.com/watch?v=4BWsfPaq1Ro
5/9/2024

CarLLaVA: Vision language models for camera-only closed-loop driving
Katrin Renz, Long Chen, Ana-Maria Marcu, Jan Hunermann, Benoit Hanotte, Alice Karnsund, Jamie Shotton, Elahe Arani, Oleg Sinavski
0
0
In this technical report, we present CarLLaVA, a Vision Language Model (VLM) for autonomous driving, developed for the CARLA Autonomous Driving Challenge 2.0. CarLLaVA uses the vision encoder of the LLaVA VLM and the LLaMA architecture as backbone, achieving state-of-the-art closed-loop driving performance with only camera input and without the need for complex or expensive labels. Additionally, we show preliminary results on predicting language commentary alongside the driving output. CarLLaVA uses a semi-disentangled output representation of both path predictions and waypoints, getting the advantages of the path for better lateral control and the waypoints for better longitudinal control. We propose an efficient training recipe to train on large driving datasets without wasting compute on easy, trivial data. CarLLaVA ranks 1st place in the sensor track of the CARLA Autonomous Driving Challenge 2.0 outperforming the previous state of the art by 458% and the best concurrent submission by 32.6%.
6/17/2024