CaseLink: Inductive Graph Learning for Legal Case Retrieval

0
Sign in to get full access
Overview
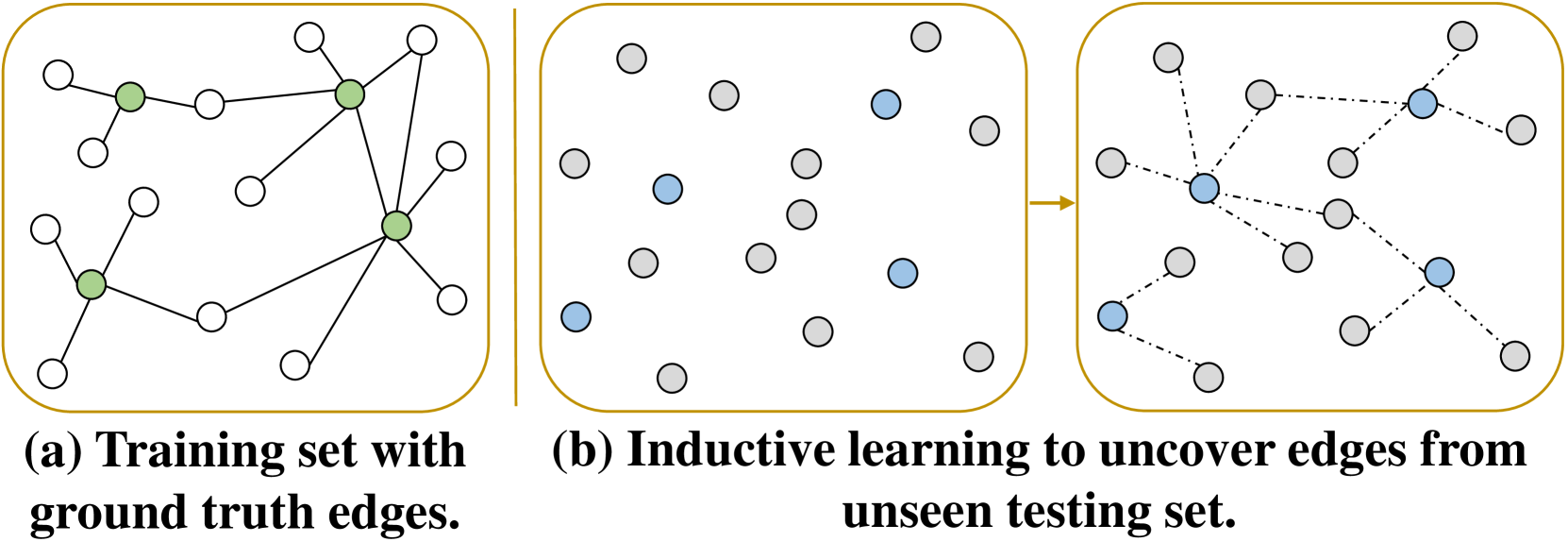
- This paper presents CaseLink, a novel approach to legal case retrieval using inductive graph learning.
- CaseLink aims to leverage the rich semantic relationships between legal cases to improve the accuracy and efficiency of case retrieval.
- The proposed model learns embeddings for legal cases by modeling the graph structure of case citations and other relevant metadata.
- The authors demonstrate the effectiveness of CaseLink on several legal case retrieval benchmarks, showing significant improvements over existing methods.
Plain English Explanation
The paper describes a new tool called CaseLink that can help lawyers and researchers more easily find relevant legal cases. In law, it's important to be able to quickly find past cases that are similar to the one you're working on, as these precedents can greatly influence the outcome of a legal dispute.
[CaseLink: Inductive Graph Learning for Legal Case Retrieval](https://aimodels.fyi/papers/arxiv/caselin k-inductive-graph-learning-legal-case-retrieval) uses a technique called "graph learning" to model the relationships between different legal cases. It looks at how cases cite and reference each other, as well as other metadata about the cases, to build a graph-like representation. This allows the model to learn patterns and extract insights that can then be used to surface the most relevant cases for a given query.
Compared to previous approaches, the CaseLink model is able to more accurately retrieve cases that are truly similar and applicable to the user's needs. This can save lawyers and researchers a significant amount of time and effort in their case research and preparation.
Technical Explanation
The key innovation in CaseLink is the use of inductive graph learning to model the semantic relationships between legal cases. Rather than relying solely on the textual content of case summaries, CaseLink also incorporates information about how cases cite and reference each other, as well as other metadata like the court, judge, and date.
This graph-structured representation allows CaseLink to leverage analogous instances and learn more holistic embeddings for each case. The model is trained in an end-to-end fashion to optimize directly for the case retrieval task.
Experiments on several legal case retrieval benchmarks demonstrate the effectiveness of CaseLink compared to state-of-the-art baselines. The graph-based approach is shown to outperform text-only models, highlighting the value of capturing the hierarchical and structured nature of legal knowledge.
Critical Analysis
One key limitation of CaseLink is that it relies on the availability of structured metadata, such as citation links between cases. In practice, this information may not always be complete or readily available, especially for less prominent or older legal cases.
The paper also does not extensively explore the interpretability or explainability of the learned case embeddings. While the graph-based approach is shown to be effective, it may be difficult for users to understand the reasoning behind the model's case recommendations.
Additionally, the experiments in the paper are conducted on a relatively small dataset of US Supreme Court cases. Further research is needed to assess the scalability and generalizability of CaseLink to larger and more diverse legal case collections, such as those found in different jurisdictions or legal domains.
Conclusion
Overall, the CaseLink model presents a promising approach to legal case retrieval that leverages the rich semantic relationships between cases. By modeling these connections through inductive graph learning, the system is able to more accurately surface relevant precedents and insights to support legal research and decision-making.
While the current implementation has some limitations, the ideas and techniques explored in this paper could have significant implications for the development of more intelligent and user-friendly legal information retrieval systems. As the volume of legal data continues to grow, tools like CaseLink will become increasingly important for navigating and extracting value from these vast knowledge repositories.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CaseLink: Inductive Graph Learning for Legal Case Retrieval
Yanran Tang, Ruihong Qiu, Hongzhi Yin, Xue Li, Zi Huang
In case law, the precedents are the relevant cases that are used to support the decisions made by the judges and the opinions of lawyers towards a given case. This relevance is referred to as the case-to-case reference relation. To efficiently find relevant cases from a large case pool, retrieval tools are widely used by legal practitioners. Existing legal case retrieval models mainly work by comparing the text representations of individual cases. Although they obtain a decent retrieval accuracy, the intrinsic case connectivity relationships among cases have not been well exploited for case encoding, therefore limiting the further improvement of retrieval performance. In a case pool, there are three types of case connectivity relationships: the case reference relationship, the case semantic relationship, and the case legal charge relationship. Due to the inductive manner in the task of legal case retrieval, using case reference as input is not applicable for testing. Thus, in this paper, a CaseLink model based on inductive graph learning is proposed to utilise the intrinsic case connectivity for legal case retrieval, a novel Global Case Graph is incorporated to represent both the case semantic relationship and the case legal charge relationship. A novel contrastive objective with a regularisation on the degree of case nodes is proposed to leverage the information carried by the case reference relationship to optimise the model. Extensive experiments have been conducted on two benchmark datasets, which demonstrate the state-of-the-art performance of CaseLink. The code has been released on https://github.com/yanran-tang/CaseLink.
Read more6/13/2024

0
CaseGNN++: Graph Contrastive Learning for Legal Case Retrieval with Graph Augmentation
Yanran Tang, Ruihong Qiu, Yilun Liu, Xue Li, Zi Huang
Legal case retrieval (LCR) is a specialised information retrieval task that aims to find relevant cases to a given query case. LCR holds pivotal significance in facilitating legal practitioners in finding precedents. Most of existing LCR methods are based on traditional lexical models and language models, which have gained promising performance in retrieval. However, the domain-specific structural information inherent in legal documents is yet to be exploited to further improve the performance. Our previous work CaseGNN successfully harnesses text-attributed graphs and graph neural networks to address the problem of legal structural information neglect. Nonetheless, there remain two aspects for further investigation: (1) The underutilization of rich edge information within text-attributed case graphs limits CaseGNN to generate informative case representation. (2) The inadequacy of labelled data in legal datasets hinders the training of CaseGNN model. In this paper, CaseGNN++, which is extended from CaseGNN, is proposed to simultaneously leverage the edge information and additional label data to discover the latent potential of LCR models. Specifically, an edge feature-based graph attention layer (EUGAT) is proposed to comprehensively update node and edge features during graph modelling, resulting in a full utilisation of structural information of legal cases. Moreover, a novel graph contrastive learning objective with graph augmentation is developed in CaseGNN++ to provide additional training signals, thereby enhancing the legal comprehension capabilities of CaseGNN++ model. Extensive experiments on two benchmark datasets from COLIEE 2022 and COLIEE 2023 demonstrate that CaseGNN++ not only significantly improves CaseGNN but also achieves supreme performance compared to state-of-the-art LCR methods. Code has been released on https://github.com/yanran-tang/CaseGNN.
Read more5/21/2024

0
Learning Interpretable Legal Case Retrieval via Knowledge-Guided Case Reformulation
Chenlong Deng, Kelong Mao, Zhicheng Dou
Legal case retrieval for sourcing similar cases is critical in upholding judicial fairness. Different from general web search, legal case retrieval involves processing lengthy, complex, and highly specialized legal documents. Existing methods in this domain often overlook the incorporation of legal expert knowledge, which is crucial for accurately understanding and modeling legal cases, leading to unsatisfactory retrieval performance. This paper introduces KELLER, a legal knowledge-guided case reformulation approach based on large language models (LLMs) for effective and interpretable legal case retrieval. By incorporating professional legal knowledge about crimes and law articles, we enable large language models to accurately reformulate the original legal case into concise sub-facts of crimes, which contain the essential information of the case. Extensive experiments on two legal case retrieval benchmarks demonstrate superior retrieval performance and robustness on complex legal case queries of KELLER over existing methods.
Read more7/1/2024
🏅
0
Automatic Knowledge Graph Construction for Judicial Cases
Jie Zhou, Xin Chen, Hang Zhang, Zhe Li
In this paper, we explore the application of cognitive intelligence in legal knowledge, focusing on the development of judicial artificial intelligence. Utilizing natural language processing (NLP) as the core technology, we propose a method for the automatic construction of case knowledge graphs for judicial cases. Our approach centers on two fundamental NLP tasks: entity recognition and relationship extraction. We compare two pre-trained models for entity recognition to establish their efficacy. Additionally, we introduce a multi-task semantic relationship extraction model that incorporates translational embedding, leading to a nuanced contextualized case knowledge representation. Specifically, in a case study involving a Motor Vehicle Traffic Accident Liability Dispute, our approach significantly outperforms the baseline model. The entity recognition F1 score improved by 0.36, while the relationship extraction F1 score increased by 2.37. Building on these results, we detail the automatic construction process of case knowledge graphs for judicial cases, enabling the assembly of knowledge graphs for hundreds of thousands of judgments. This framework provides robust semantic support for applications of judicial AI, including the precise categorization and recommendation of related cases.
Read more4/16/2024