CatFree3D: Category-agnostic 3D Object Detection with Diffusion

0

Sign in to get full access
Overview
- The paper presents a category-agnostic 3D object detection method called CatFree3D that uses diffusion models.
- It can detect objects without relying on pre-defined object categories, making it more flexible and applicable to a wider range of scenarios.
- The approach leverages the powerful generative capabilities of diffusion models to predict 3D bounding boxes for objects in point cloud data.
Plain English Explanation
The researchers developed a new way to detect 3D objects in point cloud data without needing to know what category the objects belong to ahead of time. Traditional 3D object detection methods are often limited to a pre-defined set of object categories, which can be restrictive.
CatFree3D uses a type of AI model called a diffusion model to instead learn to predict the 3D bounding boxes for objects directly from the point cloud data, without relying on object categories. Diffusion models work by gradually adding noise to data and then learning to reverse that process, allowing them to generate new data that looks realistic.
By applying this diffusion approach to 3D point clouds, the researchers were able to create a system that can detect a wide variety of 3D objects without needing to know ahead of time what those objects might be. This makes the system more flexible and applicable to real-world scenarios where the objects of interest may not fit into predefined categories.
Technical Explanation
The key innovation in CatFree3D is the use of a diffusion model to perform 3D object detection in a category-agnostic manner. Diffusion models work by gradually adding Gaussian noise to data, then learning to reverse that noising process to generate new samples.
The CatFree3D architecture takes a 3D point cloud as input and uses a series of diffusion model steps to predict the 3D bounding boxes for any objects present, without needing to know the object categories ahead of time. This is accomplished by training the diffusion model to denoise the point cloud and output the 3D object proposals directly.
The experiments demonstrate that CatFree3D achieves competitive performance on standard 3D object detection benchmarks, while also showing the flexibility to detect a wider range of object types compared to previous category-specific approaches. The diffusion-based approach allows the model to learn general object detection capabilities rather than being constrained by predefined categories.
Critical Analysis
A key strength of the CatFree3D approach is its category-agnostic nature, which allows it to be more broadly applicable than prior work focused on specific object types. However, the paper does not provide a thorough analysis of the model's performance and limitations across a diverse range of object categories.
Additionally, while the diffusion model approach is novel for 3D object detection, the paper does not deeply explore potential drawbacks or failure modes of this technique compared to other object detection methods. Further research would be needed to fully understand the trade-offs and identify areas for improvement.
The authors also do not address potential biases or ethical considerations that may arise from a category-agnostic 3D object detector, such as concerns around equitable performance across different object types or environments. Exploring these aspects would strengthen the overall contribution.
Conclusion
CatFree3D presents a promising step towards more flexible and generalizable 3D object detection by leveraging diffusion models. This category-agnostic approach has the potential to unlock new applications and use cases where predefined object categories are insufficient.
While the initial results are encouraging, further research is needed to fully characterize the strengths, weaknesses, and broader implications of this diffusion-based technique. Addressing areas like model robustness, fairness, and ethical considerations would help solidify CatFree3D as a valuable contribution to the field of 3D computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CatFree3D: Category-agnostic 3D Object Detection with Diffusion
Wenjing Bian, Zirui Wang, Andrea Vedaldi
Image-based 3D object detection is widely employed in applications such as autonomous vehicles and robotics, yet current systems struggle with generalisation due to complex problem setup and limited training data. We introduce a novel pipeline that decouples 3D detection from 2D detection and depth prediction, using a diffusion-based approach to improve accuracy and support category-agnostic detection. Additionally, we introduce the Normalised Hungarian Distance (NHD) metric for an accurate evaluation of 3D detection results, addressing the limitations of traditional IoU and GIoU metrics. Experimental results demonstrate that our method achieves state-of-the-art accuracy and strong generalisation across various object categories and datasets.
Read more8/26/2024

0
DC3DO: Diffusion Classifier for 3D Objects
Nursena Koprucu (Luke), Meher Shashwat Nigam (Luke), Shicheng Xu (Luke), Biruk Abere, Gabriele Dominici, Andrew Rodriguez, Sharvaree Vadgam, Berfin Inal, Alberto Tono
Inspired by Geoffrey Hinton emphasis on generative modeling, To recognize shapes, first learn to generate them, we explore the use of 3D diffusion models for object classification. Leveraging the density estimates from these models, our approach, the Diffusion Classifier for 3D Objects (DC3DO), enables zero-shot classification of 3D shapes without additional training. On average, our method achieves a 12.5 percent improvement compared to its multiview counterparts, demonstrating superior multimodal reasoning over discriminative approaches. DC3DO employs a class-conditional diffusion model trained on ShapeNet, and we run inferences on point clouds of chairs and cars. This work highlights the potential of generative models in 3D object classification.
Read more8/14/2024
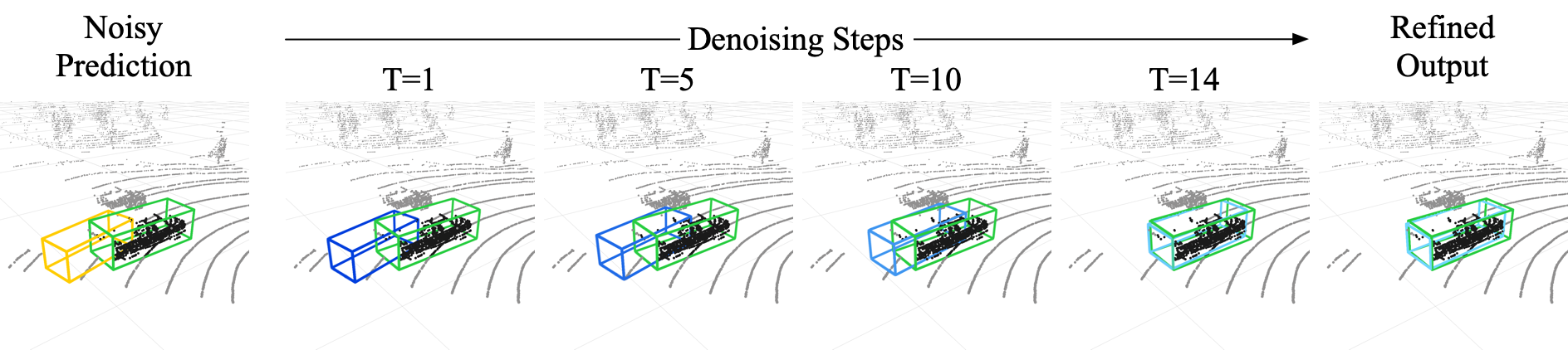
0
DiffuBox: Refining 3D Object Detection with Point Diffusion
Xiangyu Chen, Zhenzhen Liu, Katie Z Luo, Siddhartha Datta, Adhitya Polavaram, Yan Wang, Yurong You, Boyi Li, Marco Pavone, Wei-Lun Chao, Mark Campbell, Bharath Hariharan, Kilian Q. Weinberger
Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
Read more5/28/2024

0
Enhanced Automotive Object Detection via RGB-D Fusion in a DiffusionDet Framework
Eliraz Orfaig, Inna Stainvas, Igal Bilik
Vision-based autonomous driving requires reliable and efficient object detection. This work proposes a DiffusionDet-based framework that exploits data fusion from the monocular camera and depth sensor to provide the RGB and depth (RGB-D) data. Within this framework, ground truth bounding boxes are randomly reshaped as part of the training phase, allowing the model to learn the reverse diffusion process of noise addition. The system methodically enhances a randomly generated set of boxes at the inference stage, guiding them toward accurate final detections. By integrating the textural and color features from RGB images with the spatial depth information from the LiDAR sensors, the proposed framework employs a feature fusion that substantially enhances object detection of automotive targets. The $2.3$ AP gain in detecting automotive targets is achieved through comprehensive experiments using the KITTI dataset. Specifically, the improved performance of the proposed approach in detecting small objects is demonstrated.
Read more6/6/2024