Enhanced Automotive Object Detection via RGB-D Fusion in a DiffusionDet Framework
2406.03129
0
0

Abstract
Vision-based autonomous driving requires reliable and efficient object detection. This work proposes a DiffusionDet-based framework that exploits data fusion from the monocular camera and depth sensor to provide the RGB and depth (RGB-D) data. Within this framework, ground truth bounding boxes are randomly reshaped as part of the training phase, allowing the model to learn the reverse diffusion process of noise addition. The system methodically enhances a randomly generated set of boxes at the inference stage, guiding them toward accurate final detections. By integrating the textural and color features from RGB images with the spatial depth information from the LiDAR sensors, the proposed framework employs a feature fusion that substantially enhances object detection of automotive targets. The $2.3$ AP gain in detecting automotive targets is achieved through comprehensive experiments using the KITTI dataset. Specifically, the improved performance of the proposed approach in detecting small objects is demonstrated.
Create account to get full access
Overview
- This paper presents a novel approach for enhanced automotive object detection using a combination of RGB and depth (RGB-D) data within a DiffusionDet framework.
- The proposed method leverages the complementary strengths of RGB and depth information to improve the accuracy and robustness of object detection for automotive applications.
- The authors integrate the DiffusionDet model, a state-of-the-art object detection architecture, with an RGB-D fusion mechanism to enhance the detection of various objects, including vehicles, pedestrians, and cyclists.
Plain English Explanation
The paper describes a new technique for improving the detection of objects, such as cars, people, and bikes, in automotive settings. Typically, object detection systems use only camera (RGB) data, which can be challenging in complex environments with varying lighting conditions or occlusions.
To address this, the researchers combined the camera data with additional depth information, which provides a 3D understanding of the scene. By fusing the RGB and depth data within a powerful object detection model called DiffusionDet, the system can more accurately identify and locate different objects on the road.
The key innovation is the integration of the RGB-D (color and depth) data with the DiffusionDet architecture. DiffusionDet is a state-of-the-art object detection model that has shown impressive performance. By adapting it to work with both RGB and depth information, the researchers were able to create a more robust and reliable system for detecting a variety of automotive targets, even in challenging conditions.
Technical Explanation
The paper introduces an enhanced automotive object detection framework that leverages the fusion of RGB and depth (RGB-D) data within the DiffusionDet architecture. DiffusionBox: Refining 3D Object Detection from Point Clouds with Diffusion Models is a recently proposed object detection model that has demonstrated state-of-the-art performance.
The authors extend the DiffusionDet model by incorporating a feature fusion module that combines the complementary information from the RGB and depth modalities. This allows the system to better utilize the depth cues, which can provide valuable 3D spatial information and improve the detection of objects, especially in cluttered or occluded environments.
The proposed RGB-D fusion mechanism is designed to adaptively integrate the RGB and depth features at multiple stages of the DiffusionDet pipeline. This enhances the model's ability to capture and leverage the salient visual and depth characteristics of the automotive targets, leading to more accurate and robust object detection.
The authors evaluate the performance of their RGB-D fusion-based DiffusionDet framework on several automotive datasets, demonstrating significant improvements in detection accuracy compared to using RGB or depth information alone, as well as other state-of-the-art object detection methods.
Critical Analysis
The paper presents a compelling approach for enhancing automotive object detection by effectively fusing RGB and depth data within the DiffusionDet framework. The authors have thoroughly evaluated their method and provided compelling results, showcasing the benefits of incorporating depth information to improve detection performance.
However, the paper does not discuss the potential computational and memory overhead associated with the additional depth sensing and fusion components. While the improved detection accuracy is valuable, the real-world deployment of such a system may be constrained by resource limitations in automotive settings.
Additionally, the paper does not address the robustness of the system to environmental factors, such as varying weather conditions or sensor failures. It would be interesting to see how the RGB-D fusion-based DiffusionDet framework performs under these more challenging scenarios, which are common in real-world automotive applications.
Finally, the authors could have explored the potential for further improving the system by leveraging other sensor modalities, such as radar and vision fusion or salient object detection in RGB-D videos. Integrating additional sensing capabilities could lead to even more robust and comprehensive automotive object detection systems.
Conclusion
The paper presents a novel approach for enhanced automotive object detection by fusing RGB and depth data within the DiffusionDet framework. The researchers have demonstrated that the integration of depth information can significantly improve the accuracy and reliability of object detection for various automotive targets, including vehicles, pedestrians, and cyclists.
The proposed RGB-D fusion-based DiffusionDet framework represents an important advancement in the field of computer vision for autonomous driving and advanced driver assistance systems (ADAS). By leveraging the complementary strengths of both RGB and depth data, the system can better handle complex and challenging automotive environments, paving the way for more robust and reliable object detection solutions.
The findings of this research have the potential to contribute to the development of more comprehensive 3D object reconstruction and segmentation systems and improved object detection for RGB-infrared fusion, further enhancing the capabilities of autonomous vehicles and related technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Survey of Deep Learning Based Radar and Vision Fusion for 3D Object Detection in Autonomous Driving
Di Wu, Feng Yang, Benlian Xu, Pan Liao, Bo Liu
0
0
With the rapid advancement of autonomous driving technology, there is a growing need for enhanced safety and efficiency in the automatic environmental perception of vehicles during their operation. In modern vehicle setups, cameras and mmWave radar (radar), being the most extensively employed sensors, demonstrate complementary characteristics, inherently rendering them conducive to fusion and facilitating the achievement of both robust performance and cost-effectiveness. This paper focuses on a comprehensive survey of radar-vision (RV) fusion based on deep learning methods for 3D object detection in autonomous driving. We offer a comprehensive overview of each RV fusion category, specifically those employing region of interest (ROI) fusion and end-to-end fusion strategies. As the most promising fusion strategy at present, we provide a deeper classification of end-to-end fusion methods, including those 3D bounding box prediction based and BEV based approaches. Moreover, aligning with recent advancements, we delineate the latest information on 4D radar and its cutting-edge applications in autonomous vehicles (AVs). Finally, we present the possible future trends of RV fusion and summarize this paper.
6/4/2024
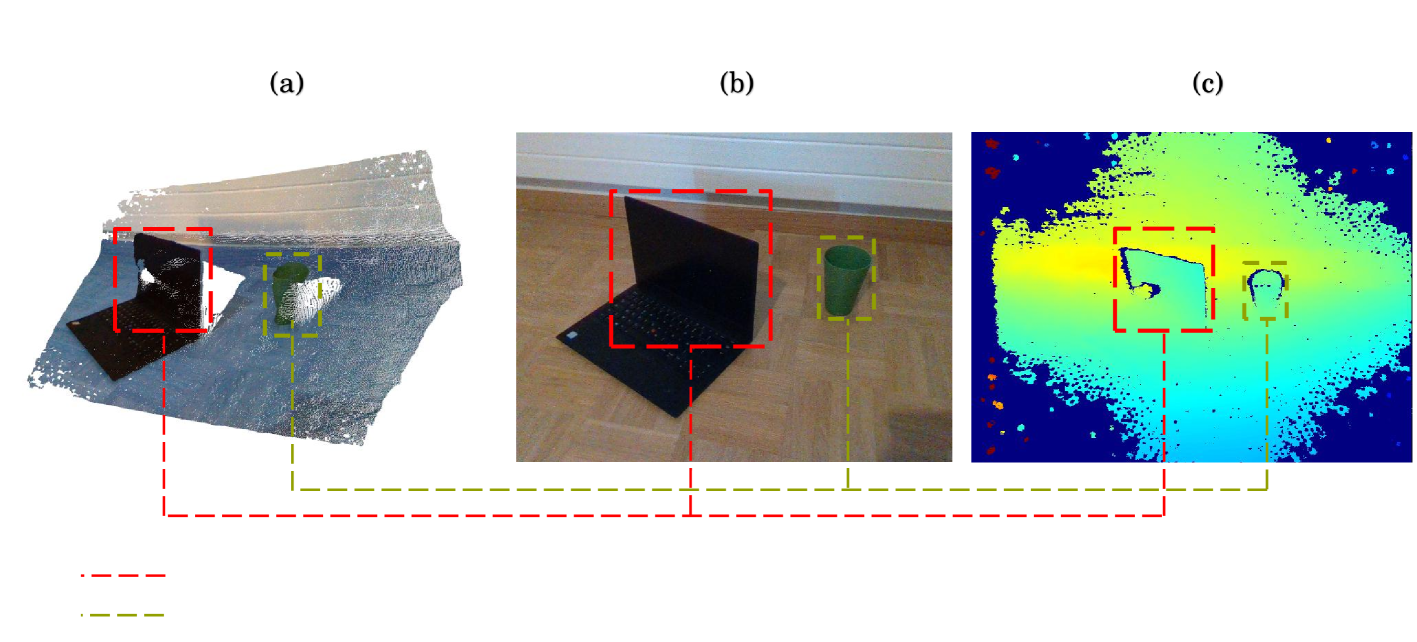
FusionVision: A comprehensive approach of 3D object reconstruction and segmentation from RGB-D cameras using YOLO and fast segment anything
Safouane El Ghazouali, Youssef Mhirit, Ali Oukhrid, Umberto Michelucci, Hichem Nouira
0
0
In the realm of computer vision, the integration of advanced techniques into the processing of RGB-D camera inputs poses a significant challenge, given the inherent complexities arising from diverse environmental conditions and varying object appearances. Therefore, this paper introduces FusionVision, an exhaustive pipeline adapted for the robust 3D segmentation of objects in RGB-D imagery. Traditional computer vision systems face limitations in simultaneously capturing precise object boundaries and achieving high-precision object detection on depth map as they are mainly proposed for RGB cameras. To address this challenge, FusionVision adopts an integrated approach by merging state-of-the-art object detection techniques, with advanced instance segmentation methods. The integration of these components enables a holistic (unified analysis of information obtained from both color textit{RGB} and depth textit{D} channels) interpretation of RGB-D data, facilitating the extraction of comprehensive and accurate object information. The proposed FusionVision pipeline employs YOLO for identifying objects within the RGB image domain. Subsequently, FastSAM, an innovative semantic segmentation model, is applied to delineate object boundaries, yielding refined segmentation masks. The synergy between these components and their integration into 3D scene understanding ensures a cohesive fusion of object detection and segmentation, enhancing overall precision in 3D object segmentation. The code and pre-trained models are publicly available at https://github.com/safouaneelg/FusionVision/.
5/2/2024
🔎
Salient Object Detection in RGB-D Videos
Ao Mou, Yukang Lu, Jiahao He, Dingyao Min, Keren Fu, Qijun Zhao
0
0
Given the widespread adoption of depth-sensing acquisition devices, RGB-D videos and related data/media have gained considerable traction in various aspects of daily life. Consequently, conducting salient object detection (SOD) in RGB-D videos presents a highly promising and evolving avenue. Despite the potential of this area, SOD in RGB-D videos remains somewhat under-explored, with RGB-D SOD and video SOD (VSOD) traditionally studied in isolation. To explore this emerging field, this paper makes two primary contributions: the dataset and the model. On one front, we construct the RDVS dataset, a new RGB-D VSOD dataset with realistic depth and characterized by its diversity of scenes and rigorous frame-by-frame annotations. We validate the dataset through comprehensive attribute and object-oriented analyses, and provide training and testing splits. Moreover, we introduce DCTNet+, a three-stream network tailored for RGB-D VSOD, with an emphasis on RGB modality and treats depth and optical flow as auxiliary modalities. In pursuit of effective feature enhancement, refinement, and fusion for precise final prediction, we propose two modules: the multi-modal attention module (MAM) and the refinement fusion module (RFM). To enhance interaction and fusion within RFM, we design a universal interaction module (UIM) and then integrate holistic multi-modal attentive paths (HMAPs) for refining multi-modal low-level features before reaching RFMs. Comprehensive experiments, conducted on pseudo RGB-D video datasets alongside our RDVS, highlight the superiority of DCTNet+ over 17 VSOD models and 14 RGB-D SOD models. Ablation experiments were performed on both pseudo and realistic RGB-D video datasets to demonstrate the advantages of individual modules as well as the necessity of introducing realistic depth. Our code together with RDVS dataset will be available at https://github.com/kerenfu/RDVS/.
5/22/2024
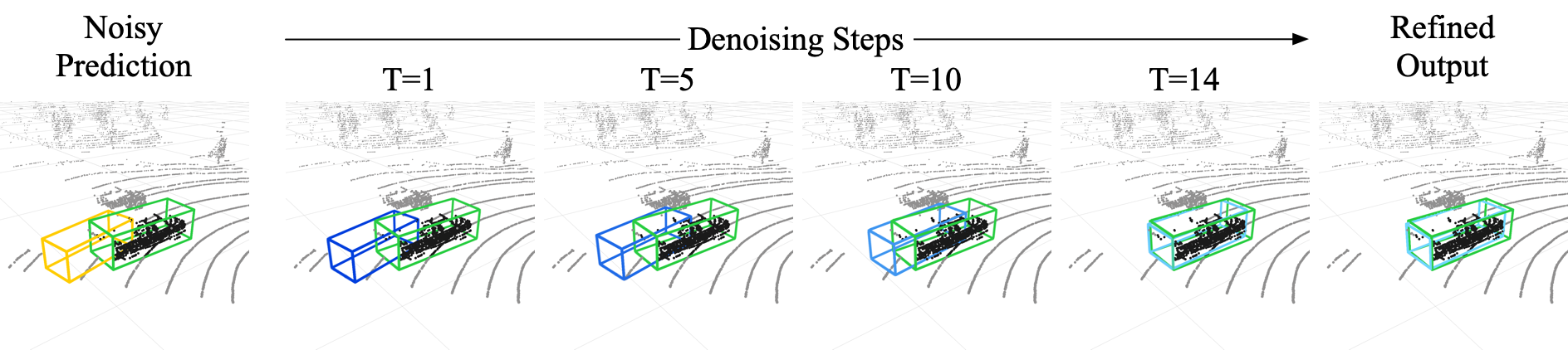
DiffuBox: Refining 3D Object Detection with Point Diffusion
Xiangyu Chen, Zhenzhen Liu, Katie Z Luo, Siddhartha Datta, Adhitya Polavaram, Yan Wang, Yurong You, Boyi Li, Marco Pavone, Wei-Lun Chao, Mark Campbell, Bharath Hariharan, Kilian Q. Weinberger
0
0
Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
5/28/2024