DiffuBox: Refining 3D Object Detection with Point Diffusion
2405.16034
0
0
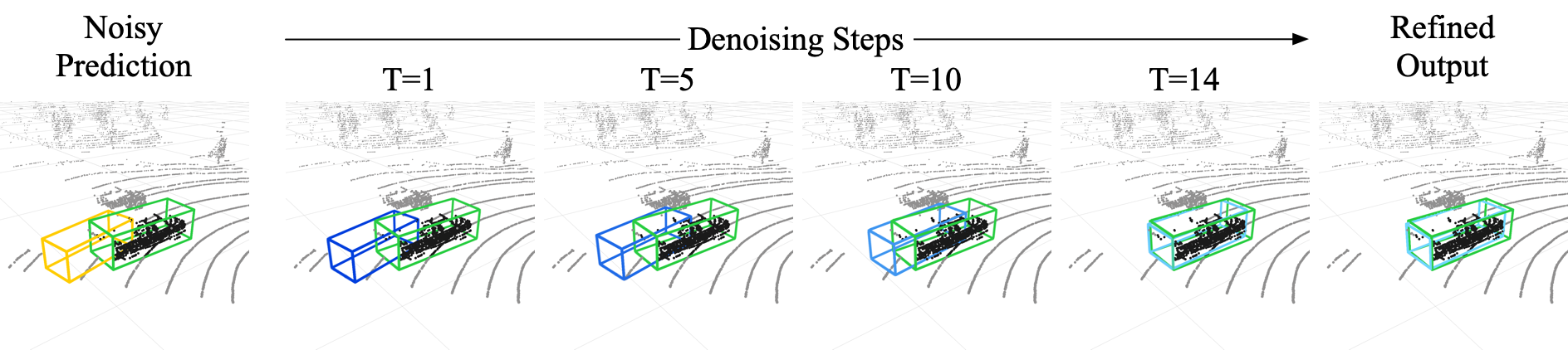
Abstract
Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
Create account to get full access
Overview
- This paper presents DiffuBox, a novel approach for refining 3D object detection using point diffusion models.
- The key idea is to leverage the powerful generative capabilities of diffusion models to enhance the performance of existing 3D object detectors.
- The proposed method outperforms state-of-the-art 3D object detection methods on several benchmark datasets.
Plain English Explanation
DiffuBox is a new technique that can improve the accuracy of 3D object detection systems. 3D object detection is the task of identifying and locating objects in 3D space, such as in point cloud data from a LiDAR sensor.
The core insight behind DiffuBox is to use a special type of AI model called a "diffusion model" to refine the output of a 3D object detector. Diffusion models are a powerful type of generative AI that can create new data that looks similar to the training data. In this case, the diffusion model is used to "clean up" the 3D object detections, correcting any mistakes or imperfections.
By combining a standard 3D object detector with the DiffuBox diffusion model refinement, the researchers were able to achieve higher accuracy on benchmark 3D detection tasks compared to using the object detector alone. This suggests that the diffusion model component is able to effectively enhance the 3D object detection capabilities.
The advantage of this approach is that it can be applied on top of existing 3D object detectors, allowing them to be improved without having to completely redesign the underlying model. This makes DiffuBox a practical and flexible solution for boosting 3D perception performance.
Technical Explanation
The DiffuBox framework consists of two key components: a 3D object detector and a point diffusion model. The object detector first generates bounding box proposals for 3D objects in the input point cloud. The point diffusion model then refines these proposals by generating "corrected" versions of the detected objects.
Specifically, the diffusion model is trained to take the initial object proposals as input and produce refined 3D point clouds that better match the ground truth object shapes. This is achieved by modeling the gradual "diffusion" of the noisy initial detections back to the clean object shapes, leveraging the powerful generative capabilities of diffusion models.
The researchers evaluated DiffuBox on several 3D object detection benchmarks, including [LINK: https://aimodels.fyi/papers/arxiv/difflow3d-toward-robust-uncertainty-aware-scene-flow], [LINK: https://aimodels.fyi/papers/arxiv/pseudo-label-refinery-unsupervised-domain-adaptation-cross], and [LINK: https://aimodels.fyi/papers/arxiv/odgen-domain-specific-object-detection-data-generation]. The results demonstrate that DiffuBox can consistently outperform state-of-the-art 3D object detectors, highlighting the benefits of integrating diffusion-based refinement into the 3D perception pipeline.
Critical Analysis
The primary limitation of DiffuBox is that it relies on the performance of the underlying 3D object detector. If the initial detections have significant errors, the diffusion model may struggle to fully correct them. The paper acknowledges this and suggests further research into robust object proposal generation as a potential avenue for improvement.
Additionally, the computational cost of running the diffusion model inference could be a concern, especially for real-time applications. The authors do not provide detailed analysis of the runtime or memory footprint of DiffuBox, which would be important to assess its practical viability.
Another potential issue is the reliance on point cloud data, which can be noisier and sparser than other 3D representations like voxels or meshes. Exploring the use of DiffuBox with alternative 3D data formats could be an interesting direction for future work.
Overall, the DiffuBox approach is a promising step towards leveraging the power of diffusion models for enhancing 3D object detection. With further refinements and analysis, it could become a valuable tool for improving 3D perception capabilities in various applications.
Conclusion
The DiffuBox paper presents a novel method for refining 3D object detection using point diffusion models. By integrating a diffusion-based refinement component with a standard 3D object detector, the researchers were able to achieve state-of-the-art performance on several benchmark datasets.
The key innovation of DiffuBox is its ability to leverage the generative capabilities of diffusion models to "clean up" the initial object detections, correcting errors and improving the overall accuracy. This approach is attractive because it can be applied on top of existing 3D object detectors, rather than requiring a complete redesign of the underlying model.
While DiffuBox shows promising results, there are still some limitations and areas for further research, such as improving the robustness to noisy object proposals and exploring the computational efficiency of the diffusion model inference. Nonetheless, this work demonstrates the potential of diffusion-based techniques for enhancing 3D perception, which could have important implications for a wide range of applications, from autonomous vehicles to robotics and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Enhanced Automotive Object Detection via RGB-D Fusion in a DiffusionDet Framework
Eliraz Orfaig, Inna Stainvas, Igal Bilik
0
0
Vision-based autonomous driving requires reliable and efficient object detection. This work proposes a DiffusionDet-based framework that exploits data fusion from the monocular camera and depth sensor to provide the RGB and depth (RGB-D) data. Within this framework, ground truth bounding boxes are randomly reshaped as part of the training phase, allowing the model to learn the reverse diffusion process of noise addition. The system methodically enhances a randomly generated set of boxes at the inference stage, guiding them toward accurate final detections. By integrating the textural and color features from RGB images with the spatial depth information from the LiDAR sensors, the proposed framework employs a feature fusion that substantially enhances object detection of automotive targets. The $2.3$ AP gain in detecting automotive targets is achieved through comprehensive experiments using the KITTI dataset. Specifically, the improved performance of the proposed approach in detecting small objects is demonstrated.
6/6/2024
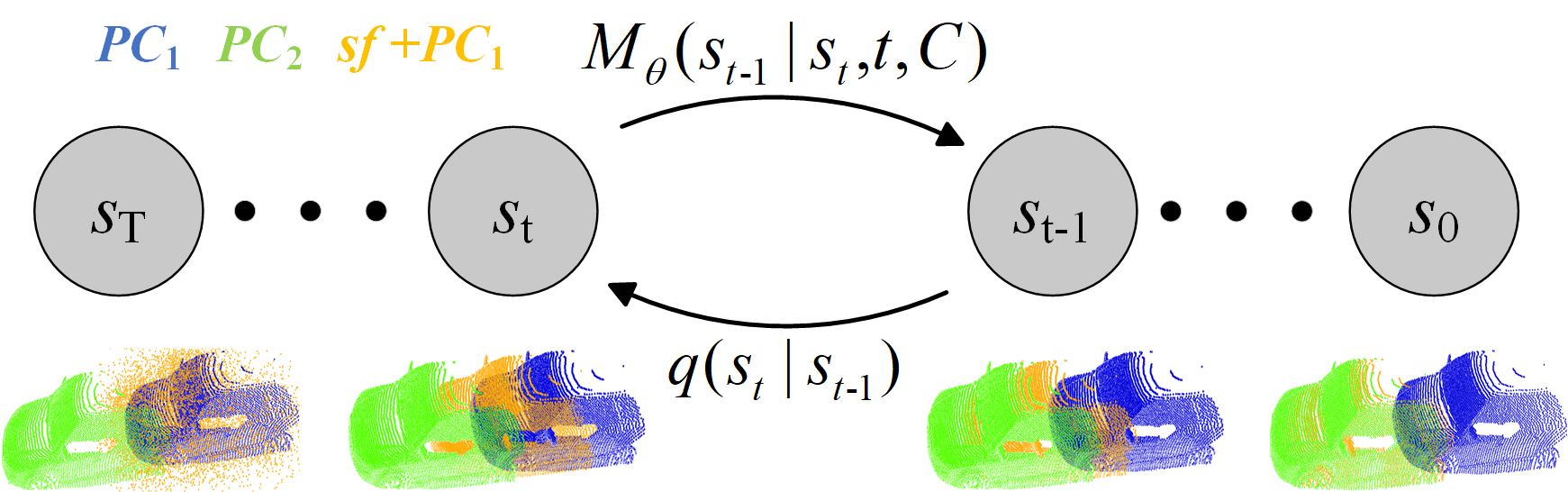
DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Diffusion Model
Jiuming Liu, Guangming Wang, Weicai Ye, Chaokang Jiang, Jinru Han, Zhe Liu, Guofeng Zhang, Dalong Du, Hesheng Wang
0
0
Scene flow estimation, which aims to predict per-point 3D displacements of dynamic scenes, is a fundamental task in the computer vision field. However, previous works commonly suffer from unreliable correlation caused by locally constrained searching ranges, and struggle with accumulated inaccuracy arising from the coarse-to-fine structure. To alleviate these problems, we propose a novel uncertainty-aware scene flow estimation network (DifFlow3D) with the diffusion probabilistic model. Iterative diffusion-based refinement is designed to enhance the correlation robustness and resilience to challenging cases, e.g. dynamics, noisy inputs, repetitive patterns, etc. To restrain the generation diversity, three key flow-related features are leveraged as conditions in our diffusion model. Furthermore, we also develop an uncertainty estimation module within diffusion to evaluate the reliability of estimated scene flow. Our DifFlow3D achieves state-of-the-art performance, with 24.0% and 29.1% EPE3D reduction respectively on FlyingThings3D and KITTI 2015 datasets. Notably, our method achieves an unprecedented millimeter-level accuracy (0.0078m in EPE3D) on the KITTI dataset. Additionally, our diffusion-based refinement paradigm can be readily integrated as a plug-and-play module into existing scene flow networks, significantly increasing their estimation accuracy. Codes are released at https://github.com/IRMVLab/DifFlow3D.
5/13/2024

Pseudo Label Refinery for Unsupervised Domain Adaptation on Cross-dataset 3D Object Detection
Zhanwei Zhang, Minghao Chen, Shuai Xiao, Liang Peng, Hengjia Li, Binbin Lin, Ping Li, Wenxiao Wang, Boxi Wu, Deng Cai
0
0
Recent self-training techniques have shown notable improvements in unsupervised domain adaptation for 3D object detection (3D UDA). These techniques typically select pseudo labels, i.e., 3D boxes, to supervise models for the target domain. However, this selection process inevitably introduces unreliable 3D boxes, in which 3D points cannot be definitively assigned as foreground or background. Previous techniques mitigate this by reweighting these boxes as pseudo labels, but these boxes can still poison the training process. To resolve this problem, in this paper, we propose a novel pseudo label refinery framework. Specifically, in the selection process, to improve the reliability of pseudo boxes, we propose a complementary augmentation strategy. This strategy involves either removing all points within an unreliable box or replacing it with a high-confidence box. Moreover, the point numbers of instances in high-beam datasets are considerably higher than those in low-beam datasets, also degrading the quality of pseudo labels during the training process. We alleviate this issue by generating additional proposals and aligning RoI features across different domains. Experimental results demonstrate that our method effectively enhances the quality of pseudo labels and consistently surpasses the state-of-the-art methods on six autonomous driving benchmarks. Code will be available at https://github.com/Zhanwei-Z/PERE.
5/1/2024
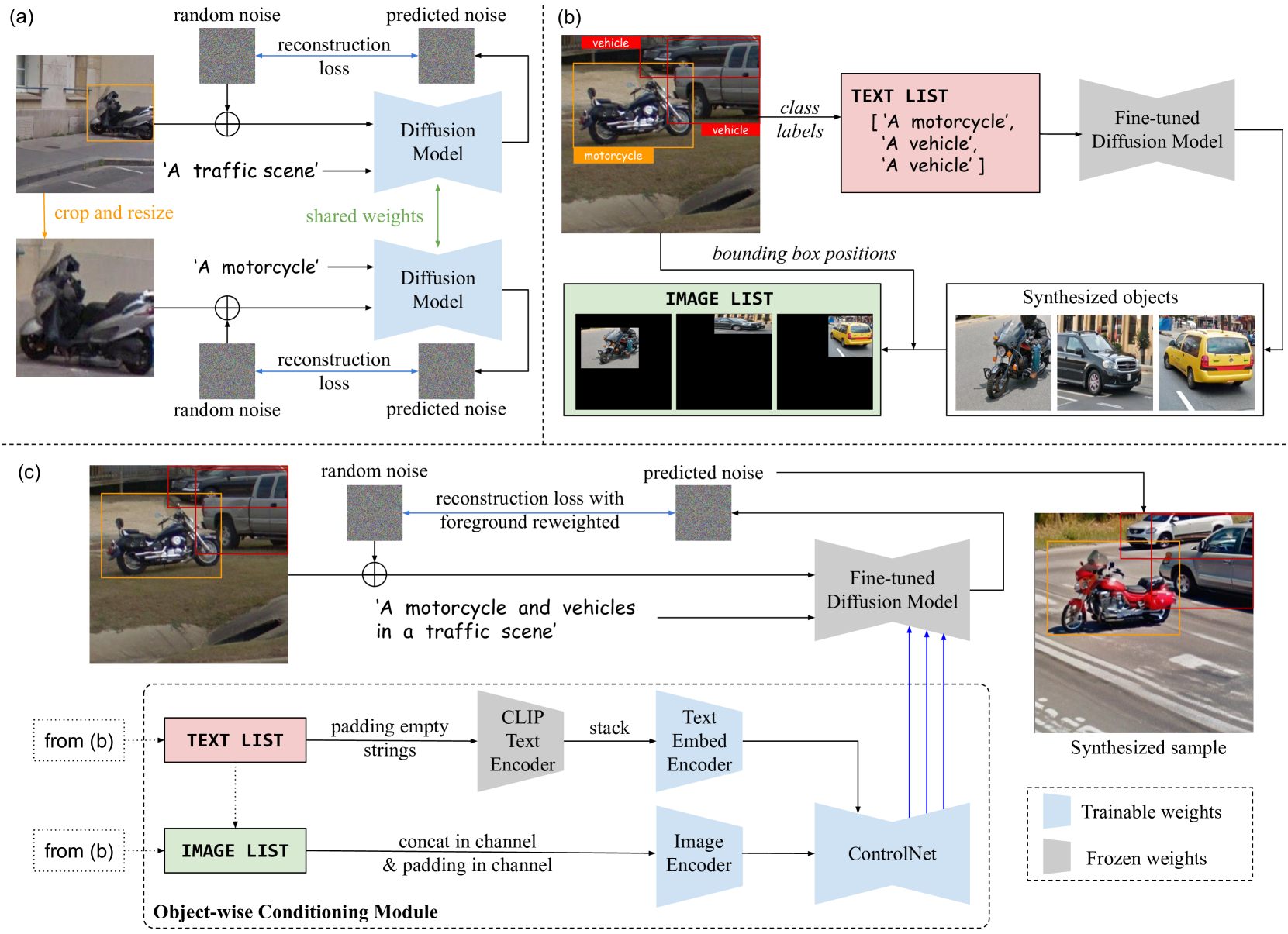
ODGEN: Domain-specific Object Detection Data Generation with Diffusion Models
Jingyuan Zhu, Shiyu Li, Yuxuan Liu, Ping Huang, Jiulong Shan, Huimin Ma, Jian Yuan
0
0
Modern diffusion-based image generative models have made significant progress and become promising to enrich training data for the object detection task. However, the generation quality and the controllability for complex scenes containing multi-class objects and dense objects with occlusions remain limited. This paper presents ODGEN, a novel method to generate high-quality images conditioned on bounding boxes, thereby facilitating data synthesis for object detection. Given a domain-specific object detection dataset, we first fine-tune a pre-trained diffusion model on both cropped foreground objects and entire images to fit target distributions. Then we propose to control the diffusion model using synthesized visual prompts with spatial constraints and object-wise textual descriptions. ODGEN exhibits robustness in handling complex scenes and specific domains. Further, we design a dataset synthesis pipeline to evaluate ODGEN on 7 domain-specific benchmarks to demonstrate its effectiveness. Adding training data generated by ODGEN improves up to 25.3% [email protected]:.95 with object detectors like YOLOv5 and YOLOv7, outperforming prior controllable generative methods. In addition, we design an evaluation protocol based on COCO-2014 to validate ODGEN in general domains and observe an advantage up to 5.6% in [email protected]:.95 against existing methods.
5/27/2024