Causal Agent based on Large Language Model

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) have achieved impressive success across various domains.
- However, they face challenges in accurately describing and comprehending causal problems and causal theory.
- Causal methods are not easily conveyed through natural language, hindering LLMs' ability to apply them effectively.
- Causal datasets are typically tabular, while LLMs excel in handling natural language data, creating a structural mismatch.
- This lack of causal reasoning capability limits the development of LLMs.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. They have shown remarkable capabilities in a wide range of tasks, such as writing articles, making decisions, and analyzing complex information. However, LLMs often struggle to fully grasp and work with causal problems and the underlying causal theory.
Causal reasoning, which involves understanding the relationships between causes and effects, is not easily conveyed through natural language. This makes it challenging for LLMs to accurately apply causal methods and reasoning. Additionally, the typical format of causal datasets, which are often in tabular form, does not align well with the natural language-based strengths of LLMs. This structural mismatch further hinders LLMs' ability to effectively reason with causal information.
To address these challenges, researchers have developed a Causal Agent – an AI system that equips LLMs with causal tools and reasoning capabilities. The Causal Agent comprises various modules, including tools for aligning tabular data with natural language, a reasoning module that employs the ReAct framework to perform causal reasoning, and a memory module for storing and accessing causal graphs.
Technical Explanation
The researchers have designed the Causal Agent to tackle causal problems more effectively than standard LLMs. The Causal Agent's architecture includes three key components:
-
Tools Module: This module applies causal methods to align tabular data, which is the typical format of causal datasets, with natural language. This helps bridge the gap between the LLM's strengths in natural language processing and the structure of causal data.
-
Reasoning Module: The Causal Agent employs the ReAct framework to perform causal reasoning through multiple iterations, leveraging the tools and information from the other modules.
-
Memory Module: The Causal Agent maintains a dictionary-like data structure, where the keys are unique names, and the values are causal graphs. This allows the system to store and retrieve causal knowledge as needed during the reasoning process.
To evaluate the Causal Agent's causal reasoning capabilities, the researchers established a benchmark consisting of four levels of causal problems: variable level, edge level, causal graph level, and causal effect level. They generated a test dataset of 1.3K examples using ChatGPT-3.5 and evaluated the Causal Agent's performance on this dataset. The results showed remarkable efficacy, with accuracy rates above 80% for all four levels of causal problems.
Critical Analysis
The research presented in this paper is a promising step towards enhancing the causal reasoning capabilities of large language models. By equipping the LLM with specialized tools, reasoning modules, and a memory system, the Causal Agent demonstrates the potential to overcome the challenges posed by the inherent complexity of causal problems and the structural mismatch between causal datasets and natural language.
However, the paper does not address certain limitations and potential issues that may warrant further investigation. For example, the researchers do not discuss the scalability of the Causal Agent's architecture, especially as the complexity and size of causal problems increase. Additionally, the evaluation is limited to a relatively small, synthetic dataset, and it would be valuable to assess the Causal Agent's performance on real-world, diverse causal datasets.
Furthermore, the paper does not explore the potential biases or limitations of the ChatGPT-3.5 model used to generate the test dataset. These biases could inadvertently influence the Causal Agent's performance, and it would be important to understand their impact and potential mitigation strategies.
Conclusion
The development of the Causal Agent represents a significant step forward in enhancing the causal reasoning capabilities of large language models. By bridging the gap between causal methods and natural language, the Causal Agent demonstrates the potential to unlock new applications and insights that require a deeper understanding of causal relationships.
While the research presented in this paper is promising, further exploration and refinement of the Causal Agent's architecture, evaluation on diverse real-world datasets, and investigation of potential biases and limitations will be crucial to fully realize the potential of this approach. As the field of AI continues to advance, the ability to reason effectively with causal information will become increasingly important, making the Causal Agent a valuable tool for the development of more robust and capable language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Causal Agent based on Large Language Model
Kairong Han, Kun Kuang, Ziyu Zhao, Junjian Ye, Fei Wu
Large language models (LLMs) have achieved significant success across various domains. However, the inherent complexity of causal problems and causal theory poses challenges in accurately describing them in natural language, making it difficult for LLMs to comprehend and use them effectively. Causal methods are not easily conveyed through natural language, which hinders LLMs' ability to apply them accurately. Additionally, causal datasets are typically tabular, while LLMs excel in handling natural language data, creating a structural mismatch that impedes effective reasoning with tabular data. This lack of causal reasoning capability limits the development of LLMs. To address these challenges, we have equipped the LLM with causal tools within an agent framework, named the Causal Agent, enabling it to tackle causal problems. The causal agent comprises tools, memory, and reasoning modules. In the tools module, the causal agent applies causal methods to align tabular data with natural language. In the reasoning module, the causal agent employs the ReAct framework to perform reasoning through multiple iterations with the tools. In the memory module, the causal agent maintains a dictionary instance where the keys are unique names and the values are causal graphs. To verify the causal ability of the causal agent, we established a benchmark consisting of four levels of causal problems: variable level, edge level, causal graph level, and causal effect level. We generated a test dataset of 1.3K using ChatGPT-3.5 for these four levels of issues and tested the causal agent on the datasets. Our methodology demonstrates remarkable efficacy on the four-level causal problems, with accuracy rates all above 80%. For further insights and implementation details, our code is accessible via the GitHub repository https://github.com/Kairong-Han/Causal_Agent.
Read more8/14/2024
0
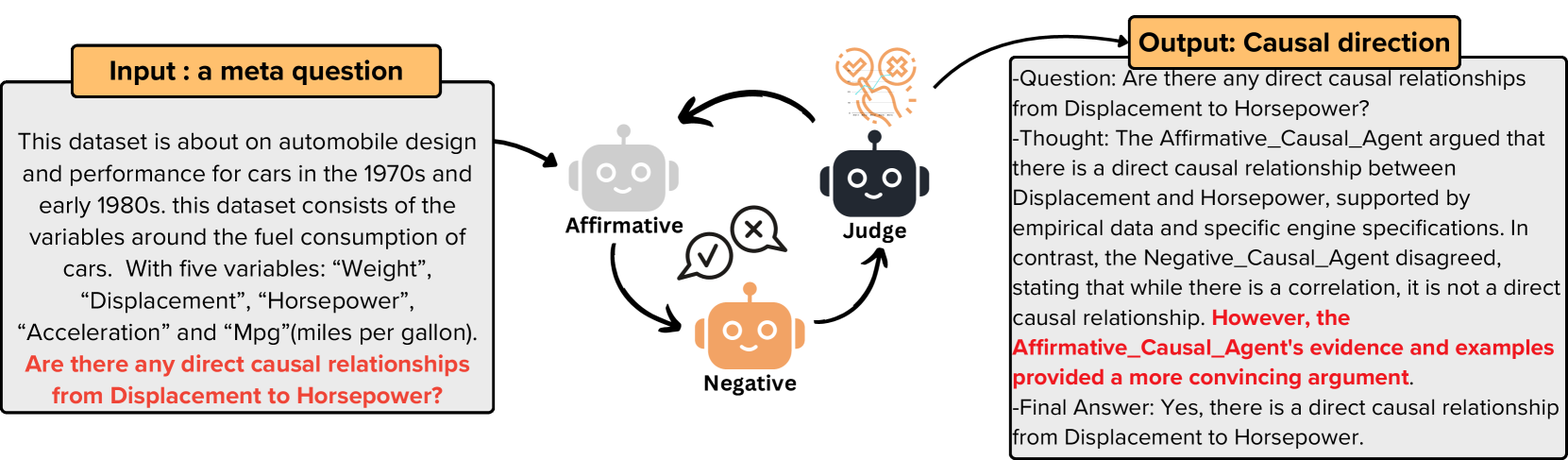
Multi-Agent Causal Discovery Using Large Language Models
Hao Duong Le, Xin Xia, Zhang Chen
Large Language Models (LLMs) have demonstrated significant potential in causal discovery tasks by utilizing their vast expert knowledge from extensive text corpora. However, the multi-agent capabilities of LLMs in causal discovery remain underexplored. This paper introduces a general framework to investigate this potential. The first is the Meta Agents Model, which relies exclusively on reasoning and discussions among LLM agents to conduct causal discovery. The second is the Coding Agents Model, which leverages the agents' ability to plan, write, and execute code, utilizing advanced statistical libraries for causal discovery. The third is the Hybrid Model, which integrates both the Meta Agents Model and CodingAgents Model approaches, combining the statistical analysis and reasoning skills of multiple agents. Our proposed framework shows promising results by effectively utilizing LLMs expert knowledge, reasoning capabilities, multi-agent cooperation, and statistical causal methods. By exploring the multi-agent potential of LLMs, we aim to establish a foundation for further research in utilizing LLMs multi-agent for solving causal-related problems.
Read more7/23/2024
💬
4
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
Emre K{i}c{i}man, Robert Ness, Amit Sharma, Chenhao Tan
The causal capabilities of large language models (LLMs) are a matter of significant debate, with critical implications for the use of LLMs in societally impactful domains such as medicine, science, law, and policy. We conduct a behavorial study of LLMs to benchmark their capability in generating causal arguments. Across a wide range of tasks, we find that LLMs can generate text corresponding to correct causal arguments with high probability, surpassing the best-performing existing methods. Algorithms based on GPT-3.5 and 4 outperform existing algorithms on a pairwise causal discovery task (97%, 13 points gain), counterfactual reasoning task (92%, 20 points gain) and event causality (86% accuracy in determining necessary and sufficient causes in vignettes). We perform robustness checks across tasks and show that the capabilities cannot be explained by dataset memorization alone, especially since LLMs generalize to novel datasets that were created after the training cutoff date. That said, LLMs exhibit unpredictable failure modes, and we discuss the kinds of errors that may be improved and what are the fundamental limits of LLM-based answers. Overall, by operating on the text metadata, LLMs bring capabilities so far understood to be restricted to humans, such as using collected knowledge to generate causal graphs or identifying background causal context from natural language. As a result, LLMs may be used by human domain experts to save effort in setting up a causal analysis, one of the biggest impediments to the widespread adoption of causal methods. Given that LLMs ignore the actual data, our results also point to a fruitful research direction of developing algorithms that combine LLMs with existing causal techniques. Code and datasets are available at https://github.com/py-why/pywhy-llm.
Read more8/21/2024
0
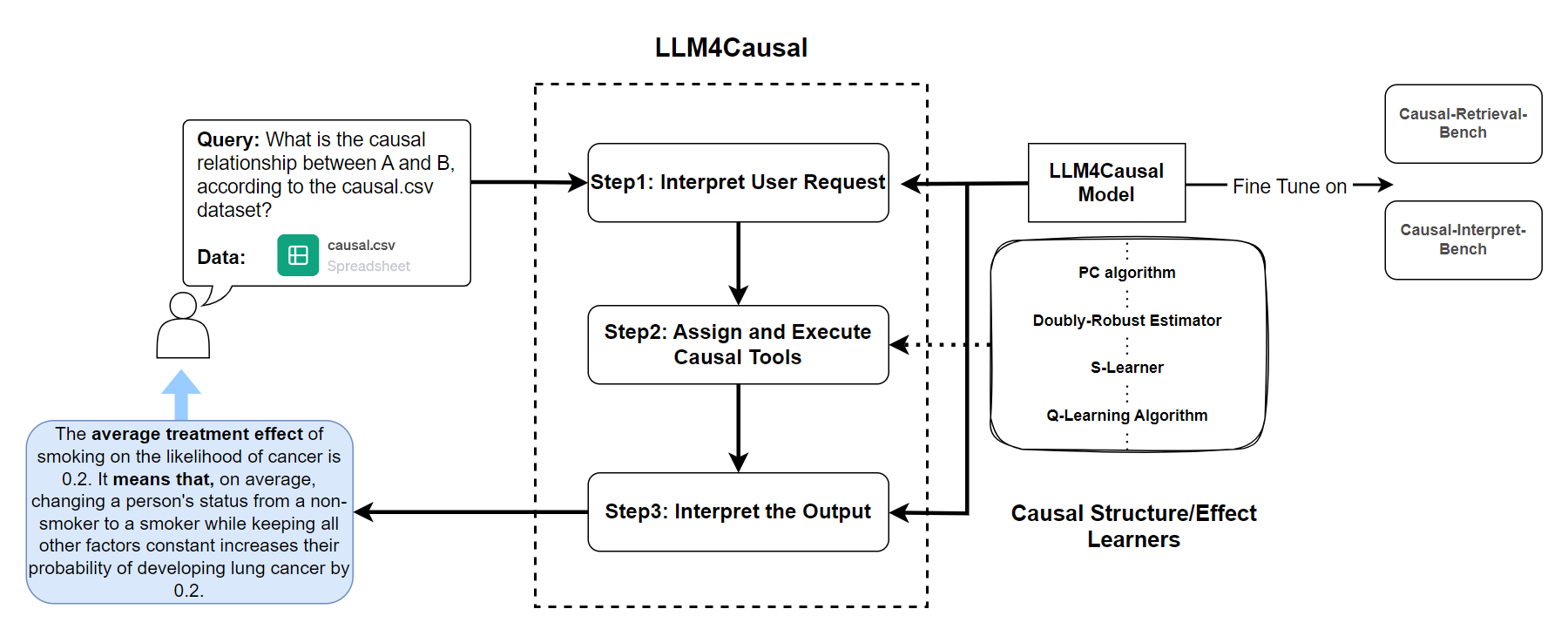
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
Read more4/15/2024