Causal Representation Learning Made Identifiable by Grouping of Observational Variables
2310.15709
0
0
🔎
Abstract
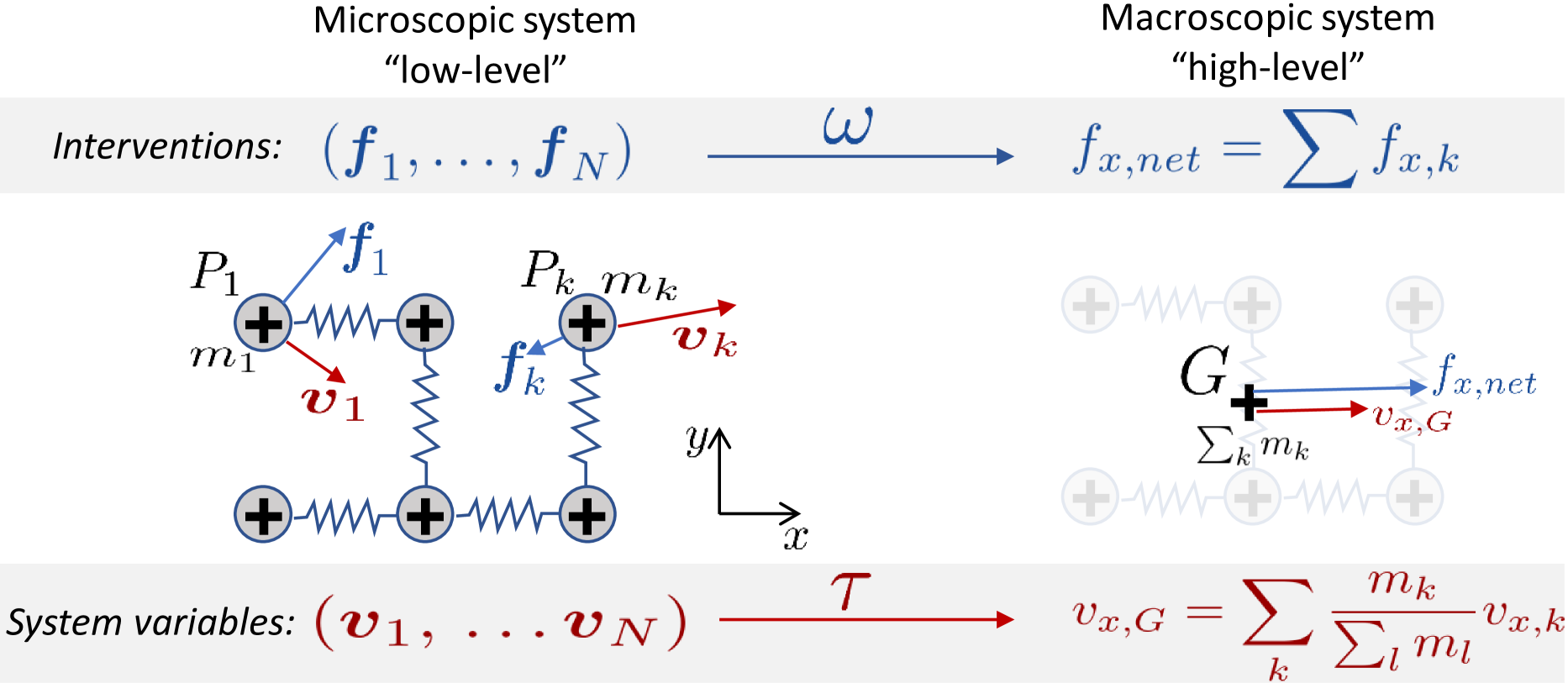
A topic of great current interest is Causal Representation Learning (CRL), whose goal is to learn a causal model for hidden features in a data-driven manner. Unfortunately, CRL is severely ill-posed since it is a combination of the two notoriously ill-posed problems of representation learning and causal discovery. Yet, finding practical identifiability conditions that guarantee a unique solution is crucial for its practical applicability. Most approaches so far have been based on assumptions on the latent causal mechanisms, such as temporal causality, or existence of supervision or interventions; these can be too restrictive in actual applications. Here, we show identifiability based on novel, weak constraints, which requires no temporal structure, intervention, nor weak supervision. The approach is based on assuming the observational mixing exhibits a suitable grouping of the observational variables. We also propose a novel self-supervised estimation framework consistent with the model, prove its statistical consistency, and experimentally show its superior CRL performances compared to the state-of-the-art baselines. We further demonstrate its robustness against latent confounders and causal cycles.
Create account to get full access
Overview
- This paper explores the challenge of Causal Representation Learning (CRL), which aims to learn a causal model for hidden features in a data-driven manner.
- CRL is inherently ill-posed, as it combines the notoriously ill-posed problems of representation learning and causal discovery.
- The paper proposes a novel approach that provides identifiability guarantees without relying on restrictive assumptions like temporal causality, interventions, or weak supervision.
- The approach assumes the observational mixing exhibits a suitable grouping of the observational variables, and a self-supervised estimation framework is developed that is statistically consistent.
- Experiments show the approach outperforms state-of-the-art baselines and is robust against latent confounders and causal cycles.
Plain English Explanation
Causal Representation Learning (CRL) is a technique that aims to automatically discover the underlying causal structure of hidden features in a data-driven way. This is a challenging task because it combines two already difficult problems: representation learning (extracting meaningful features from data) and causal discovery (inferring the causal relationships between variables).
The paper presents a new approach that can identify the causal model without requiring restrictive assumptions that are often needed in previous methods. For example, it doesn't need to assume the causal relationships have a particular temporal structure, or that there are interventions (deliberate changes to the system) or weak supervision (some additional information about the causal structure) available.
Instead, the key idea is to assume the observed data has a certain grouping structure. This means the observed variables can be divided into groups in a way that reveals information about the underlying causal model. The paper then develops a novel self-supervised estimation framework that can leverage this grouping structure to accurately recover the causal model, even in the presence of latent confounders (hidden variables that affect multiple observed variables) and causal cycles.
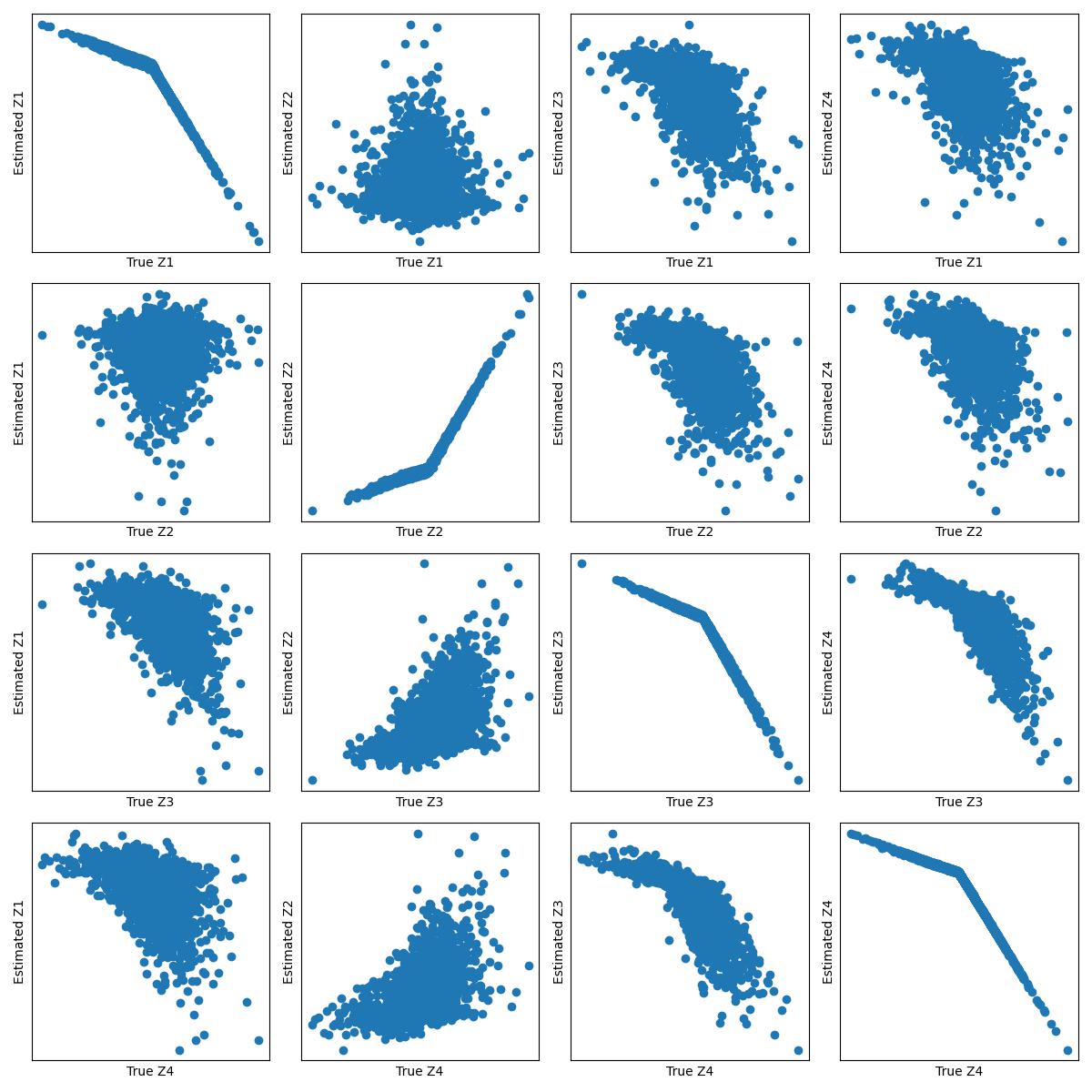
Experiments show this approach outperforms other state-of-the-art causal representation learning methods, particularly when dealing with complex causal structures like latent confounders and cycles. The ability to recover causal models from observational data alone, without restrictive assumptions, is an important step towards practical causal discovery.
Technical Explanation
The key challenge addressed in this paper is the inherent ill-posedness of Causal Representation Learning (CRL). CRL aims to learn a causal model for hidden features in a data-driven manner, but it combines the notoriously ill-posed problems of representation learning and causal discovery.
To tackle this challenge, the paper proposes a novel approach based on novel, weak constraints. Crucially, this approach requires no temporal structure, interventions, or weak supervision, which can be overly restrictive in many real-world applications.
The core idea is to assume the observational mixing exhibits a suitable grouping of the observational variables. The paper then develops a self-supervised estimation framework that is consistent with this model and can provably recover the underlying causal structure.
Experiments demonstrate the superiority of this approach compared to state-of-the-art baselines in CRL tasks. Furthermore, the method is shown to be robust against latent confounders and causal cycles, which are common issues in causal discovery.
Critical Analysis
The paper presents a promising approach to Causal Representation Learning that overcomes many of the limitations of prior methods. By relying on weaker assumptions about the data structure, the proposed technique has the potential for broader applicability in real-world scenarios.
However, the paper does acknowledge some caveats and areas for further research. For instance, the specific grouping structure assumed in the approach may not always be present in empirical data, and identifying suitable groupings could be challenging in practice. Additionally, the paper does not provide a comprehensive analysis of the computational complexity and scalability of the proposed self-supervised estimation framework.
Furthermore, while the experiments demonstrate the method's robustness to latent confounders and causal cycles, it would be valuable to explore the performance of the approach in the presence of other common challenges in causal discovery, such as measurement errors, missing data, or non-linear causal relationships.
Overall, the paper makes a significant contribution to the field of Causal Representation Learning by introducing a novel identifiability approach that relaxes many restrictive assumptions. However, further research is needed to fully understand the practical limitations and potential extensions of this work.
Conclusion
This paper presents a novel approach to Causal Representation Learning that overcomes the inherent ill-posedness of the problem by relying on weak constraints based on the grouping structure of observational variables. The proposed self-supervised estimation framework is shown to outperform state-of-the-art baselines and is robust against latent confounders and causal cycles.
The ability to recover causal models from observational data alone, without restrictive assumptions, is an important step towards practical causal discovery. This work demonstrates the potential for data-driven causal modeling techniques to uncover the underlying structure of complex systems, with applications in fields ranging from machine learning to social sciences. Further research is needed to address the remaining challenges and expand the applicability of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Identifiable Causal Representation Learning: Unsupervised, Multi-View, and Multi-Environment
Julius von Kugelgen
0
0
Causal models provide rich descriptions of complex systems as sets of mechanisms by which each variable is influenced by its direct causes. They support reasoning about manipulating parts of the system and thus hold promise for addressing some of the open challenges of artificial intelligence (AI), such as planning, transferring knowledge in changing environments, or robustness to distribution shifts. However, a key obstacle to more widespread use of causal models in AI is the requirement that the relevant variables be specified a priori, which is typically not the case for the high-dimensional, unstructured data processed by modern AI systems. At the same time, machine learning (ML) has proven quite successful at automatically extracting useful and compact representations of such complex data. Causal representation learning (CRL) aims to combine the core strengths of ML and causality by learning representations in the form of latent variables endowed with causal model semantics. In this thesis, we study and present new results for different CRL settings. A central theme is the question of identifiability: Given infinite data, when are representations satisfying the same learning objective guaranteed to be equivalent? This is an important prerequisite for CRL, as it formally characterises if and when a learning task is, at least in principle, feasible. Since learning causal models, even without a representation learning component, is notoriously difficult, we require additional assumptions on the model class or rich data beyond the classical i.i.d. setting. By partially characterising identifiability for different settings, this thesis investigates what is possible for CRL without direct supervision, and thus contributes to its theoretical foundations. Ideally, the developed insights can help inform data collection practices or inspire the design of new practical estimation methods.
6/21/2024
Targeted Reduction of Causal Models
Armin Keki'c, Bernhard Scholkopf, Michel Besserve
0
0
Why does a phenomenon occur? Addressing this question is central to most scientific inquiries and often relies on simulations of scientific models. As models become more intricate, deciphering the causes behind phenomena in high-dimensional spaces of interconnected variables becomes increasingly challenging. Causal Representation Learning (CRL) offers a promising avenue to uncover interpretable causal patterns within these simulations through an interventional lens. However, developing general CRL frameworks suitable for practical applications remains an open challenge. We introduce Targeted Causal Reduction (TCR), a method for condensing complex intervenable models into a concise set of causal factors that explain a specific target phenomenon. We propose an information theoretic objective to learn TCR from interventional data of simulations, establish identifiability for continuous variables under shift interventions and present a practical algorithm for learning TCRs. Its ability to generate interpretable high-level explanations from complex models is demonstrated on toy and mechanical systems, illustrating its potential to assist scientists in the study of complex phenomena in a broad range of disciplines.
6/4/2024
🤿
Linear Causal Representation Learning from Unknown Multi-node Interventions
Burak Var{i}c{i}, Emre Acarturk, Karthikeyan Shanmugam, Ali Tajer
0
0
Despite the multifaceted recent advances in interventional causal representation learning (CRL), they primarily focus on the stylized assumption of single-node interventions. This assumption is not valid in a wide range of applications, and generally, the subset of nodes intervened in an interventional environment is fully unknown. This paper focuses on interventional CRL under unknown multi-node (UMN) interventional environments and establishes the first identifiability results for general latent causal models (parametric or nonparametric) under stochastic interventions (soft or hard) and linear transformation from the latent to observed space. Specifically, it is established that given sufficiently diverse interventional environments, (i) identifiability up to ancestors is possible using only soft interventions, and (ii) perfect identifiability is possible using hard interventions. Remarkably, these guarantees match the best-known results for more restrictive single-node interventions. Furthermore, CRL algorithms are also provided that achieve the identifiability guarantees. A central step in designing these algorithms is establishing the relationships between UMN interventional CRL and score functions associated with the statistical models of different interventional environments. Establishing these relationships also serves as constructive proof of the identifiability guarantees.
6/11/2024
Causal Representation Learning from Multiple Distributions: A General Setting
Kun Zhang, Shaoan Xie, Ignavier Ng, Yujia Zheng
0
0
In many problems, the measured variables (e.g., image pixels) are just mathematical functions of the hidden causal variables (e.g., the underlying concepts or objects). For the purpose of making predictions in changing environments or making proper changes to the system, it is helpful to recover the hidden causal variables $Z_i$ and their causal relations represented by graph $mathcal{G}_Z$. This problem has recently been known as causal representation learning. This paper is concerned with a general, completely nonparametric setting of causal representation learning from multiple distributions (arising from heterogeneous data or nonstationary time series), without assuming hard interventions behind distribution changes. We aim to develop general solutions in this fundamental case; as a by product, this helps see the unique benefit offered by other assumptions such as parametric causal models or hard interventions. We show that under the sparsity constraint on the recovered graph over the latent variables and suitable sufficient change conditions on the causal influences, interestingly, one can recover the moralized graph of the underlying directed acyclic graph, and the recovered latent variables and their relations are related to the underlying causal model in a specific, nontrivial way. In some cases, each latent variable can even be recovered up to component-wise transformations. Experimental results verify our theoretical claims.
4/11/2024