Causal Understanding For Video Question Answering

0

Sign in to get full access
Overview
- Provides submission and formatting instructions for the International Conference on Machine Learning (ICML) 2022
- Covers key details like paper length, formatting requirements, and submission process
Plain English Explanation
This paper outlines the guidelines that researchers must follow when submitting their work to the International Conference on Machine Learning (ICML) 2022. The ICML is a prestigious machine learning conference where the latest advancements in the field are presented and discussed.
The instructions cover important details like the maximum length of the submitted paper, the required formatting such as font size and margins, and the steps involved in the submission process. Following these guidelines ensures that all papers are presented in a consistent format, making it easier for the conference organizers and attendees to review and understand the research.
By providing clear and comprehensive instructions, the ICML organizers aim to make the submission process straightforward for researchers, allowing them to focus on the content and quality of their work rather than the technical details of formatting.
Technical Explanation
The paper outlines the submission and formatting instructions for the International Conference on Machine Learning (ICML) 2022. The key elements covered include:
-
Paper Length: The maximum length for a full paper submission is 9 pages, plus an optional appendix of up to 5 additional pages.
-
Formatting Requirements: The paper must be formatted using the LaTeX template provided by the conference organizers, which specifies details such as font size, margins, and spacing.
-
Submission Process: Authors must submit their paper through the conference's electronic submission system, which includes steps like providing metadata, selecting appropriate topics, and agreeing to the conference's policies.
-
Supplementary Material: In addition to the main paper, authors can submit supplementary material such as code, datasets, or additional results, which will be made available to the reviewers but not included in the page limit.
-
Double-Blind Review: The ICML 2022 uses a double-blind review process, which means that the authors' identities are hidden from the reviewers, and vice versa, to ensure an unbiased evaluation of the research.
By following these instructions, researchers can ensure that their work is presented in a clear and consistent format, making it easier for the conference organizers and attendees to understand and evaluate the research.
Critical Analysis
The instructions provided in the paper are comprehensive and well-structured, clearly outlining the requirements for ICML 2022 submissions. The emphasis on formatting and submission details helps to ensure a streamlined review process, which is important for a large and prestigious conference like ICML.
However, one potential limitation is that the instructions may not provide much guidance on the actual content and quality of the research papers. While the formatting guidelines are necessary, the conference organizers could also consider including recommendations or suggestions for crafting high-quality research papers that are likely to be accepted.
Additionally, the instructions do not address potential issues that may arise during the review process, such as how authors can respond to reviewer comments or appeal decisions. Providing some information on these aspects could further assist researchers in navigating the ICML submission and review process.
Conclusion
The submission and formatting instructions for ICML 2022 are a critical component of the conference's organization and ensure that all submitted papers are presented in a consistent and accessible format. By clearly outlining the requirements, the organizers are helping to create a streamlined review process and an engaging conference experience for both presenters and attendees. While the instructions focus on the technical aspects of submission, future iterations could consider incorporating more guidance on the content and quality of the research papers themselves, as well as the review and decision-making process.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Causal Understanding For Video Question Answering
Bhanu Prakash Reddy Guda, Tanmay Kulkarni, Adithya Sampath, Swarnashree Mysore Sathyendra
Video Question Answering is a challenging task, which requires the model to reason over multiple frames and understand the interaction between different objects to answer questions based on the context provided within the video, especially in datasets like NExT-QA (Xiao et al., 2021a) which emphasize on causal and temporal questions. Previous approaches leverage either sub-sampled information or causal intervention techniques along with complete video features to tackle the NExT-QA task. In this work we elicit the limitations of these approaches and propose solutions along four novel directions of improvements on theNExT-QA dataset. Our approaches attempts to compensate for the shortcomings in the previous works by systematically attacking each of these problems by smartly sampling frames, explicitly encoding actions and creating interventions that challenge the understanding of the model. Overall, for both single-frame (+6.3%) and complete-video (+1.1%) based approaches, we obtain the state-of-the-art results on NExT-QA dataset.
Read more7/31/2024
0
End-to-End Video Question Answering with Frame Scoring Mechanisms and Adaptive Sampling
Jianxin Liang, Xiaojun Meng, Yueqian Wang, Chang Liu, Qun Liu, Dongyan Zhao
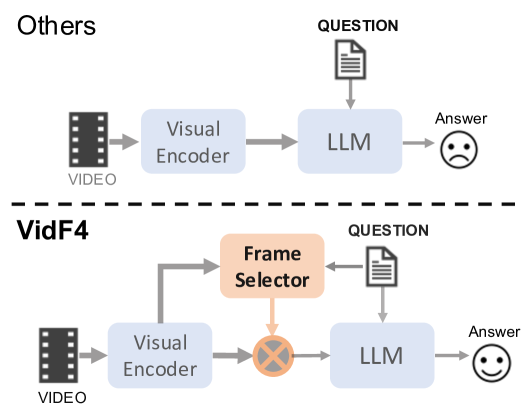
Video Question Answering (VideoQA) has emerged as a challenging frontier in the field of multimedia processing, requiring intricate interactions between visual and textual modalities. Simply uniformly sampling frames or indiscriminately aggregating frame-level visual features often falls short in capturing the nuanced and relevant contexts of videos to well perform VideoQA. To mitigate these issues, we propose VidF4, a novel VideoQA framework equipped with tailored frame selection strategy for effective and efficient VideoQA. We propose three frame-scoring mechanisms that consider both question relevance and inter-frame similarity to evaluate the importance of each frame for a given question on the video. Furthermore, we design a differentiable adaptive frame sampling mechanism to facilitate end-to-end training for the frame selector and answer generator. The experimental results across three widely adopted benchmarks demonstrate that our model consistently outperforms existing VideoQA methods, establishing a new SOTA across NExT-QA (+0.3%), STAR (+0.9%), and TVQA (+1.0%). Furthermore, through both quantitative and qualitative analyses, we validate the effectiveness of each design choice.
Read more7/24/2024
🤿
0
Open-Ended Multi-Modal Relational Reasoning for Video Question Answering
Haozheng Luo, Ruiyang Qin, Chenwei Xu, Guo Ye, Zening Luo
In this paper, we introduce a robotic agent specifically designed to analyze external environments and address participants' questions. The primary focus of this agent is to assist individuals using language-based interactions within video-based scenes. Our proposed method integrates video recognition technology and natural language processing models within the robotic agent. We investigate the crucial factors affecting human-robot interactions by examining pertinent issues arising between participants and robot agents. Methodologically, our experimental findings reveal a positive relationship between trust and interaction efficiency. Furthermore, our model demonstrates a 2% to 3% performance enhancement in comparison to other benchmark methods.
Read more6/12/2024

0
Top-down Activity Representation Learning for Video Question Answering
Yanan Wang, Shuichiro Haruta, Donghuo Zeng, Julio Vizcarra, Mori Kurokawa
Capturing complex hierarchical human activities, from atomic actions (e.g., picking up one present, moving to the sofa, unwrapping the present) to contextual events (e.g., celebrating Christmas) is crucial for achieving high-performance video question answering (VideoQA). Recent works have expanded multimodal models (e.g., CLIP, LLaVA) to process continuous video sequences, enhancing the model's temporal reasoning capabilities. However, these approaches often fail to capture contextual events that can be decomposed into multiple atomic actions non-continuously distributed over relatively long-term sequences. In this paper, to leverage the spatial visual context representation capability of the CLIP model for obtaining non-continuous visual representations in terms of contextual events in videos, we convert long-term video sequences into a spatial image domain and finetune the multimodal model LLaVA for the VideoQA task. Our approach achieves competitive performance on the STAR task, in particular, with a 78.4% accuracy score, exceeding the current state-of-the-art score by 2.8 points on the NExTQA task.
Read more9/14/2024