CCIL: Continuity-based Data Augmentation for Corrective Imitation Learning
2310.12972
0
0
📊
Abstract
We present a new technique to enhance the robustness of imitation learning methods by generating corrective data to account for compounding errors and disturbances. While existing methods rely on interactive expert labeling, additional offline datasets, or domain-specific invariances, our approach requires minimal additional assumptions beyond access to expert data. The key insight is to leverage local continuity in the environment dynamics to generate corrective labels. Our method first constructs a dynamics model from the expert demonstration, encouraging local Lipschitz continuity in the learned model. In locally continuous regions, this model allows us to generate corrective labels within the neighborhood of the demonstrations but beyond the actual set of states and actions in the dataset. Training on this augmented data enhances the agent's ability to recover from perturbations and deal with compounding errors. We demonstrate the effectiveness of our generated labels through experiments in a variety of robotics domains in simulation that have distinct forms of continuity and discontinuity, including classic control problems, drone flying, navigation with high-dimensional sensor observations, legged locomotion, and tabletop manipulation.
Create account to get full access
Overview
- Presents a new technique to enhance the robustness of imitation learning methods
- Generates corrective data to account for compounding errors and disturbances
- Leverages local continuity in the environment dynamics to generate corrective labels
- Demonstrates effectiveness in various robotics domains with distinct continuity and discontinuity
Plain English Explanation
This paper introduces a new approach to improve the robustness of imitation learning methods. Imitation learning is a way for AI systems to learn by observing expert behavior, rather than through trial-and-error. However, these systems can struggle when faced with unexpected situations or compounding errors.
The key insight of this work is to leverage the local continuity of the environment dynamics. By constructing a model of the expert's behavior that encourages local smoothness, the researchers can generate additional "corrective" data points beyond the original expert demonstrations. This helps the AI system learn to recover from perturbations and deal with compounding errors.
Unlike prior methods that require additional expert labeling, offline datasets, or domain-specific assumptions, this approach has minimal additional requirements. The authors demonstrate the effectiveness of their generated labels across a variety of robotics domains, including classic control problems, drone flying, navigation, legged locomotion, and tabletop manipulation.
Technical Explanation
The core of this work is a technique to generate corrective labels from the expert demonstrations. The researchers first construct a dynamics model of the expert's behavior, encouraging the model to have local Lipschitz continuity.
In regions where the model is locally continuous, the researchers can then generate additional data points within the neighborhood of the demonstrations but beyond the original states and actions. This augmented dataset helps the agent learn to better recover from perturbations and compounding errors during deployment.
The authors evaluate their approach across a diverse set of simulated robotics domains, including classic control problems, drone flying, high-dimensional navigation, legged locomotion, and tabletop manipulation. These environments exhibit varying degrees of continuity and discontinuity in their dynamics, allowing the researchers to assess the generality of their technique.
Critical Analysis
The paper provides a clever and principled approach to enhancing the robustness of imitation learning methods. By leveraging local continuity in the environment dynamics, the researchers are able to generate corrective labels without requiring additional expert interaction or domain-specific assumptions.
However, the technique is still reliant on having access to a good dynamics model of the expert's behavior. In highly complex or stochastic environments, constructing such a model may be challenging. The authors acknowledge this as a potential limitation and suggest further research into model-free approaches.
Additionally, the evaluation is conducted entirely in simulation, leaving open questions about the real-world applicability and robustness to modeling errors. Validating the approach on physical robotic systems would be an important next step to demonstrate its practical value.
Overall, this work presents a promising direction for improving the robustness and data-efficiency of imitation learning, with opportunities for further research and real-world deployment.
Conclusion
This paper introduces a new technique to enhance the robustness of imitation learning methods by generating corrective data based on the local continuity of the environment dynamics. The approach is able to improve the agent's ability to recover from perturbations and deal with compounding errors without requiring additional expert labeling or domain-specific assumptions.
The researchers demonstrate the effectiveness of their generated labels across a variety of simulated robotics domains, showcasing the generality of the technique. While the reliance on a good dynamics model and the lack of real-world validation present some limitations, this work represents an important step forward in improving the robustness and data-efficiency of imitation learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Data Efficient Behavior Cloning for Fine Manipulation via Continuity-based Corrective Labels
Abhay Deshpande, Liyiming Ke, Quinn Pfeifer, Abhishek Gupta, Siddhartha S. Srinivasa
0
0
We consider imitation learning with access only to expert demonstrations, whose real-world application is often limited by covariate shift due to compounding errors during execution. We investigate the effectiveness of the Continuity-based Corrective Labels for Imitation Learning (CCIL) framework in mitigating this issue for real-world fine manipulation tasks. CCIL generates corrective labels by learning a locally continuous dynamics model from demonstrations to guide the agent back toward expert states. Through extensive experiments on peg insertion and fine grasping, we provide the first empirical validation that CCIL can significantly improve imitation learning performance despite discontinuities present in contact-rich manipulation. We find that: (1) real-world manipulation exhibits sufficient local smoothness to apply CCIL, (2) generated corrective labels are most beneficial in low-data regimes, and (3) label filtering based on estimated dynamics model error enables performance gains. To effectively apply CCIL to robotic domains, we offer a practical instantiation of the framework and insights into design choices and hyperparameter selection. Our work demonstrates CCIL's practicality for alleviating compounding errors in imitation learning on physical robots.
6/5/2024
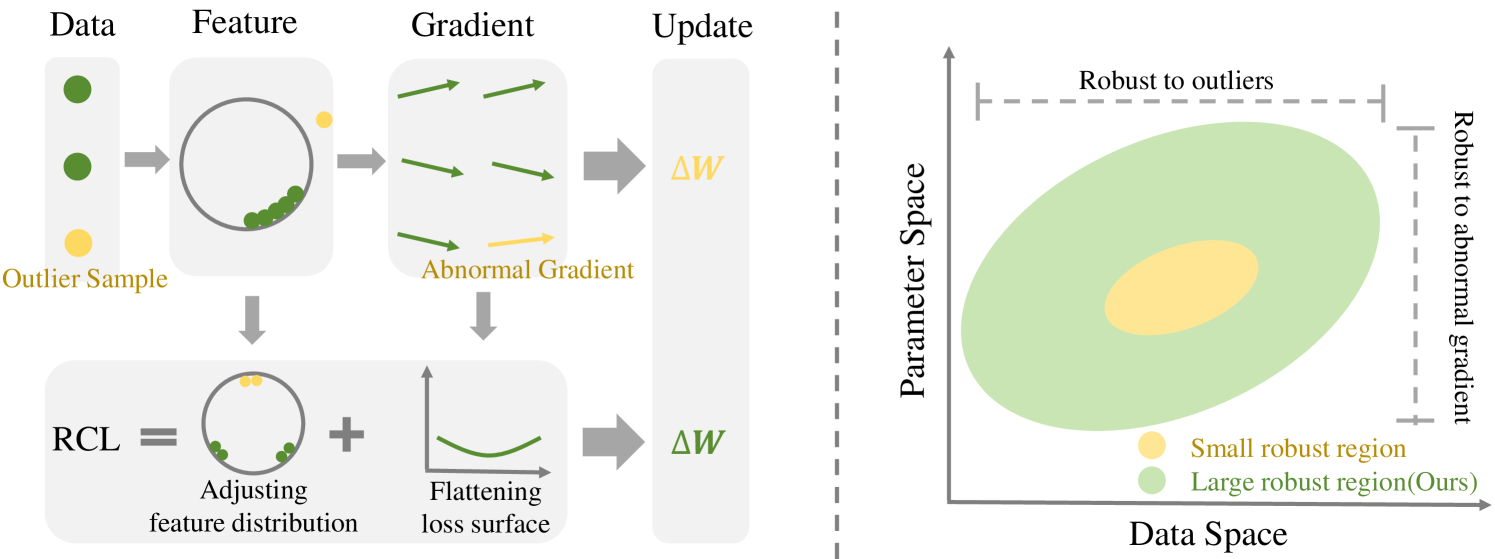
Improving Data-aware and Parameter-aware Robustness for Continual Learning
Hanxi Xiao, Fan Lyu
0
0
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
5/28/2024

Provable Contrastive Continual Learning
Yichen Wen, Zhiquan Tan, Kaipeng Zheng, Chuanlong Xie, Weiran Huang
0
0
Continual learning requires learning incremental tasks with dynamic data distributions. So far, it has been observed that employing a combination of contrastive loss and distillation loss for training in continual learning yields strong performance. To the best of our knowledge, however, this contrastive continual learning framework lacks convincing theoretical explanations. In this work, we fill this gap by establishing theoretical performance guarantees, which reveal how the performance of the model is bounded by training losses of previous tasks in the contrastive continual learning framework. Our theoretical explanations further support the idea that pre-training can benefit continual learning. Inspired by our theoretical analysis of these guarantees, we propose a novel contrastive continual learning algorithm called CILA, which uses adaptive distillation coefficients for different tasks. These distillation coefficients are easily computed by the ratio between average distillation losses and average contrastive losses from previous tasks. Our method shows great improvement on standard benchmarks and achieves new state-of-the-art performance.
5/30/2024

Causal Action Influence Aware Counterfactual Data Augmentation
N'uria Armengol Urp'i, Marco Bagatella, Marin Vlastelica, Georg Martius
0
0
Offline data are both valuable and practical resources for teaching robots complex behaviors. Ideally, learning agents should not be constrained by the scarcity of available demonstrations, but rather generalize beyond the training distribution. However, the complexity of real-world scenarios typically requires huge amounts of data to prevent neural network policies from picking up on spurious correlations and learning non-causal relationships. We propose CAIAC, a data augmentation method that can create feasible synthetic transitions from a fixed dataset without having access to online environment interactions. By utilizing principled methods for quantifying causal influence, we are able to perform counterfactual reasoning by swapping $it{action}$-unaffected parts of the state-space between independent trajectories in the dataset. We empirically show that this leads to a substantial increase in robustness of offline learning algorithms against distributional shift.
5/30/2024