Data Efficient Behavior Cloning for Fine Manipulation via Continuity-based Corrective Labels

0

Sign in to get full access
Overview
- This paper presents a data-efficient behavior cloning approach for fine manipulation tasks, using continuity-based corrective labels.
- The proposed method aims to address the challenge of learning complex robotic manipulation skills from a limited amount of demonstration data.
- The key idea is to leverage the continuity of trajectories in the demonstration data to generate additional "corrective labels" that can guide the learning process.
Plain English Explanation
The paper focuses on teaching robots how to perform precise, fine-scale manipulation tasks, like delicately handling fragile objects. This is a challenging problem because it requires robots to learn complex motor skills, but the amount of training data (demonstrations of the desired behavior) is often limited.
To address this, the researchers developed a new technique called "continuity-based corrective labels". The core idea is that when a robot is trying to learn a manipulation skill from example demonstrations, the continuity of the demonstration trajectories can provide valuable additional information to guide the learning process.
Imagine you're trying to teach a robot how to pour water from a pitcher into a glass without spilling. The demonstration data might show the pitcher moving smoothly and continuously from the table to the glass. The researchers' method can use this continuity information to generate "corrective labels" that nudge the robot's learning in the right direction, even when the demonstration data is sparse.
By incorporating these continuity-based corrective labels, the robot can learn the desired manipulation skills more efficiently, using fewer demonstration examples. This could be particularly useful in applications where gathering large amounts of high-quality demonstration data is difficult or costly, such as in healthcare robotics or manufacturing.
Technical Explanation
The paper introduces a novel behavior cloning approach that leverages the continuity of demonstration trajectories to generate additional "corrective labels" that can guide the learning process. This is motivated by the challenge of learning complex robotic manipulation skills from limited demonstration data.
The core technical idea is to model the continuity of the demonstration trajectories using a neural network that predicts the next state in a sequence, given the current state. This continuity model is then used to generate additional "corrective labels" that nudge the behavior cloning model towards producing continuous, smooth trajectories that match the demonstrations.
Specifically, the authors train the continuity model to predict the next state in a demonstration trajectory, given the current state. They then use the error between the predicted next state and the actual next state in the demonstration as a corrective label, which is combined with the standard behavior cloning loss to guide the learning of the policy network.
The authors evaluate their approach on a suite of fine manipulation tasks, including delicate object handling and tool use. They show that their continuity-based corrective labels significantly improve the data efficiency of the behavior cloning process, allowing the robot to learn complex manipulation skills from fewer demonstration examples compared to standard behavior cloning.
Critical Analysis
The key strength of this work is the innovative use of trajectory continuity information to overcome the challenge of learning from limited demonstration data. By generating corrective labels that encourage smooth, continuous trajectories, the method is able to learn more efficiently than standard behavior cloning approaches.
However, the paper does not extensively explore the limitations of the continuity-based corrective labels. For example, it's not clear how well the method would generalize to tasks where the optimal trajectories are not necessarily continuous, or where there is significant variation in the demonstration data.
Additionally, the paper does not provide a detailed analysis of the computational and sample complexity of the proposed approach compared to other data-efficient imitation learning techniques, such as those discussed in related papers, How to Leverage Diverse Demonstrations in Offline Imitation Learning, Provable Contrastive Continual Learning, Continuous Invariance Learning, and Multi-Label Continual Learning in the Medical Domain. A more comprehensive comparison would help situate this work within the broader context of data-efficient imitation learning research.
Conclusion
This paper presents a novel behavior cloning approach that leverages the continuity of demonstration trajectories to generate additional corrective labels, improving the data efficiency of learning complex robotic manipulation skills. By incorporating information about the smoothness and continuity of the desired behavior, the method can learn from fewer demonstration examples compared to standard behavior cloning techniques.
The core idea of using continuity information to guide the learning process is an interesting and promising approach that could have broader applications in imitation learning and other areas of robot learning. Further research is needed to fully understand the limitations and generalization capabilities of this method, as well as how it compares to other data-efficient imitation learning techniques. Nonetheless, this work represents an important contribution to the challenge of learning dexterous manipulation skills from limited data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data Efficient Behavior Cloning for Fine Manipulation via Continuity-based Corrective Labels
Abhay Deshpande, Liyiming Ke, Quinn Pfeifer, Abhishek Gupta, Siddhartha S. Srinivasa
We consider imitation learning with access only to expert demonstrations, whose real-world application is often limited by covariate shift due to compounding errors during execution. We investigate the effectiveness of the Continuity-based Corrective Labels for Imitation Learning (CCIL) framework in mitigating this issue for real-world fine manipulation tasks. CCIL generates corrective labels by learning a locally continuous dynamics model from demonstrations to guide the agent back toward expert states. Through extensive experiments on peg insertion and fine grasping, we provide the first empirical validation that CCIL can significantly improve imitation learning performance despite discontinuities present in contact-rich manipulation. We find that: (1) real-world manipulation exhibits sufficient local smoothness to apply CCIL, (2) generated corrective labels are most beneficial in low-data regimes, and (3) label filtering based on estimated dynamics model error enables performance gains. To effectively apply CCIL to robotic domains, we offer a practical instantiation of the framework and insights into design choices and hyperparameter selection. Our work demonstrates CCIL's practicality for alleviating compounding errors in imitation learning on physical robots.
Read more6/5/2024
📊
0
CCIL: Continuity-based Data Augmentation for Corrective Imitation Learning
Liyiming Ke, Yunchu Zhang, Abhay Deshpande, Siddhartha Srinivasa, Abhishek Gupta
We present a new technique to enhance the robustness of imitation learning methods by generating corrective data to account for compounding errors and disturbances. While existing methods rely on interactive expert labeling, additional offline datasets, or domain-specific invariances, our approach requires minimal additional assumptions beyond access to expert data. The key insight is to leverage local continuity in the environment dynamics to generate corrective labels. Our method first constructs a dynamics model from the expert demonstration, encouraging local Lipschitz continuity in the learned model. In locally continuous regions, this model allows us to generate corrective labels within the neighborhood of the demonstrations but beyond the actual set of states and actions in the dataset. Training on this augmented data enhances the agent's ability to recover from perturbations and deal with compounding errors. We demonstrate the effectiveness of our generated labels through experiments in a variety of robotics domains in simulation that have distinct forms of continuity and discontinuity, including classic control problems, drone flying, navigation with high-dimensional sensor observations, legged locomotion, and tabletop manipulation.
Read more6/5/2024
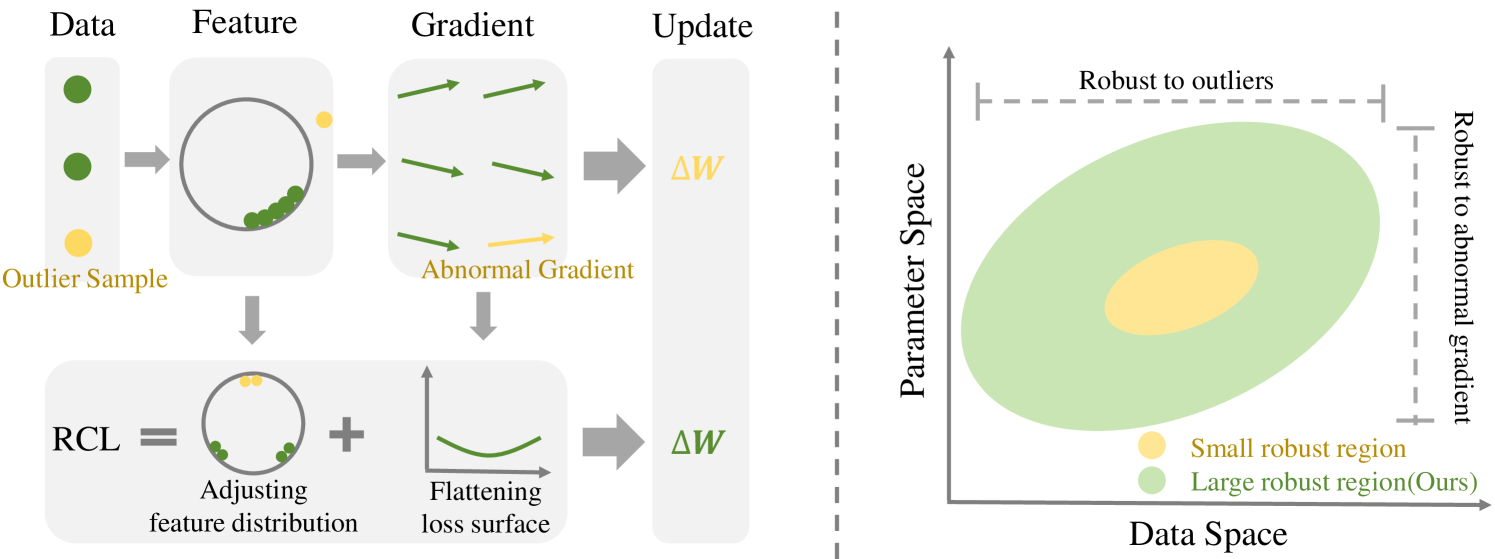
0
Improving Data-aware and Parameter-aware Robustness for Continual Learning
Hanxi Xiao, Fan Lyu
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
Read more5/28/2024

0
Trimming the Risk: Towards Reliable Continuous Training for Deep Learning Inspection Systems
Altaf Allah Abbassi, Houssem Ben Braiek, Foutse Khomh, Thomas Reid
The industry increasingly relies on deep learning (DL) technology for manufacturing inspections, which are challenging to automate with rule-based machine vision algorithms. DL-powered inspection systems derive defect patterns from labeled images, combining human-like agility with the consistency of a computerized system. However, finite labeled datasets often fail to encompass all natural variations necessitating Continuous Training (CT) to regularly adjust their models with recent data. Effective CT requires fresh labeled samples from the original distribution; otherwise, selfgenerated labels can lead to silent performance degradation. To mitigate this risk, we develop a robust CT-based maintenance approach that updates DL models using reliable data selections through a two-stage filtering process. The initial stage filters out low-confidence predictions, as the model inherently discredits them. The second stage uses variational auto-encoders and histograms to generate image embeddings that capture latent and pixel characteristics, then rejects the inputs of substantially shifted embeddings as drifted data with erroneous overconfidence. Then, a fine-tuning of the original DL model is executed on the filtered inputs while validating on a mixture of recent production and original datasets. This strategy mitigates catastrophic forgetting and ensures the model adapts effectively to new operational conditions. Evaluations on industrial inspection systems for popsicle stick prints and glass bottles using critical real-world datasets showed less than 9% of erroneous self-labeled data are retained after filtering and used for fine-tuning, improving model performance on production data by up to 14% without compromising its results on original validation data.
Read more9/17/2024