Provable Contrastive Continual Learning
2405.18756
0
0

Abstract
Continual learning requires learning incremental tasks with dynamic data distributions. So far, it has been observed that employing a combination of contrastive loss and distillation loss for training in continual learning yields strong performance. To the best of our knowledge, however, this contrastive continual learning framework lacks convincing theoretical explanations. In this work, we fill this gap by establishing theoretical performance guarantees, which reveal how the performance of the model is bounded by training losses of previous tasks in the contrastive continual learning framework. Our theoretical explanations further support the idea that pre-training can benefit continual learning. Inspired by our theoretical analysis of these guarantees, we propose a novel contrastive continual learning algorithm called CILA, which uses adaptive distillation coefficients for different tasks. These distillation coefficients are easily computed by the ratio between average distillation losses and average contrastive losses from previous tasks. Our method shows great improvement on standard benchmarks and achieves new state-of-the-art performance.
Create account to get full access
Overview
- This paper proposes a novel approach called Provable Contrastive Continual Learning (PCCL) that aims to address the challenge of continual learning in machine learning.
- Continual learning refers to the ability of a model to learn new tasks or data without catastrophically forgetting previous knowledge.
- PCCL leverages contrastive learning, a technique that learns representations by contrasting positive and negative examples, to enable continual learning with provable guarantees.
Plain English Explanation
The paper discusses a new method called Provable Contrastive Continual Learning (PCCL) that helps machine learning models continuously learn new information without forgetting what they have learned before. This is an important problem, as models often struggle to retain knowledge as they encounter new data or tasks.
PCCL leverages contrastive learning, which trains models to distinguish between "positive" examples that are similar and "negative" examples that are different. The key insight is that by learning strong representations through contrastive learning, the model can more effectively adapt to new tasks without catastrophically forgetting previous knowledge.
The paper claims that PCCL comes with theoretical guarantees, meaning the authors can prove that it has certain desirable properties. This is an important advancement, as many continual learning techniques lack such formal analyses.
Overall, PCCL represents a promising approach to making machine learning models more robust and adaptable as they encounter new information over time, which has significant implications for real-world applications.
Technical Explanation
The paper introduces Provable Contrastive Continual Learning (PCCL), a novel approach to continual learning that leverages contrastive learning principles. Continual learning refers to the ability of a model to learn new tasks or data without forgetting previous knowledge, which is a key challenge in machine learning.
PCCL works by training the model to learn strong representations through contrastive learning. Specifically, the model learns to map similar inputs (positive examples) close together in the representation space, and dissimilar inputs (negative examples) far apart. This encourages the model to extract the most salient features of the data.
When encountering new tasks or data, PCCL fine-tunes the model's representations using contrastive loss, allowing it to adapt to the new information while preserving knowledge from previous tasks. The authors provide theoretical guarantees, showing that under certain conditions, PCCL can achieve bounded forgetting and near-optimal performance on new tasks.
Experiments on benchmark continual learning datasets demonstrate the effectiveness of PCCL compared to other continual learning approaches. The model is able to learn new tasks while maintaining high performance on previous ones, showcasing its ability to continually adapt without catastrophic forgetting.
Critical Analysis
The paper makes a compelling case for the effectiveness of PCCL in addressing the continual learning problem. The theoretical guarantees provided are a notable strength, as they offer formal assurances about the model's behavior, which is often lacking in continual learning research.
However, the paper does not extensively discuss the potential limitations or caveats of the PCCL approach. For example, the authors do not explore how PCCL might perform in more complex or realistic scenarios, such as when the data distributions shift significantly between tasks or when the task boundaries are not clearly defined.
Additionally, the paper could benefit from a more thorough discussion of the computational and memory requirements of PCCL, as these factors can be important in practical deployments of continual learning systems.
Overall, the paper presents a well-designed and theoretically grounded approach to continual learning, but there is room for further exploration of the method's robustness and scalability to more challenging real-world scenarios.
Conclusion
This paper introduces Provable Contrastive Continual Learning (PCCL), a novel continual learning technique that leverages contrastive learning principles to enable models to adapt to new tasks and data without catastrophically forgetting previous knowledge. The key innovation is the use of contrastive learning to build robust representations that can be effectively fine-tuned for new tasks.
The paper's theoretical analysis and empirical results demonstrate the promise of PCCL as a powerful continual learning approach. By providing formal guarantees and strong performance on benchmark datasets, the authors have made a significant contribution to the field of continual learning, which is a critical capability for deploying machine learning systems in real-world applications.
Further research is needed to explore the limitations and practical considerations of PCCL, but this work represents an important step forward in developing continual learning methods that can truly adapt and learn over time without forgetting.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
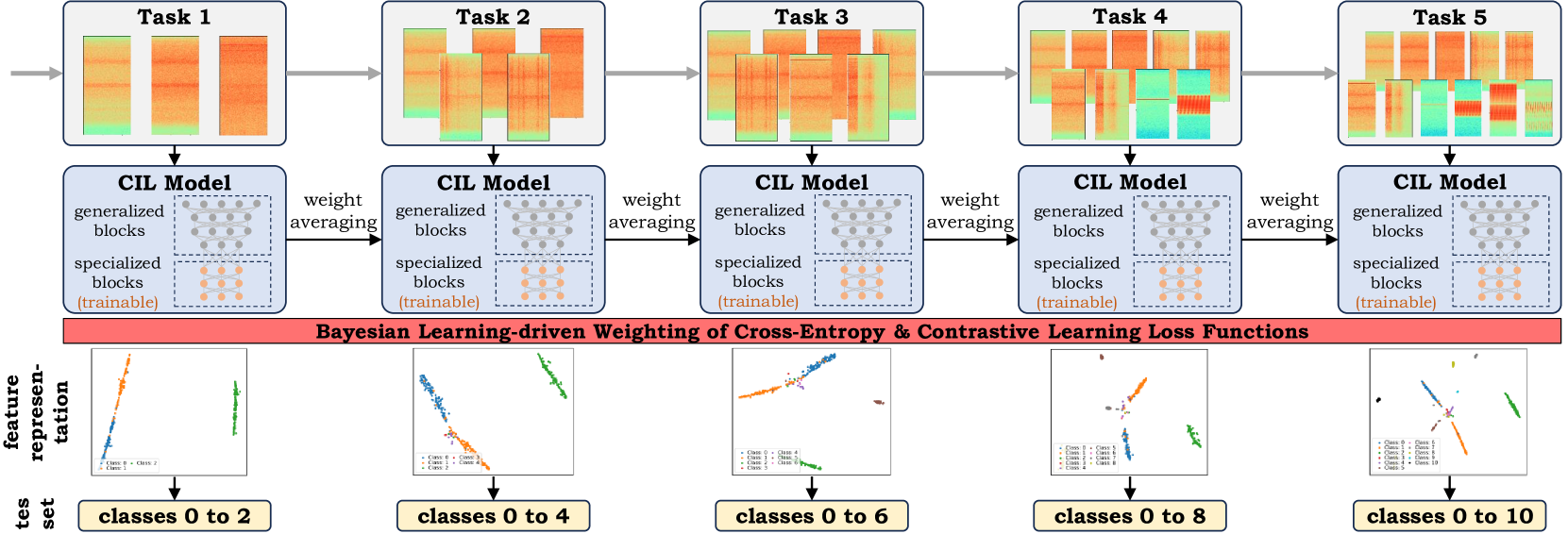
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
Nisha L. Raichur, Lucas Heublein, Tobias Feigl, Alexander Rugamer, Christopher Mutschler, Felix Ott
0
0
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
5/21/2024
On the Convergence of Continual Learning with Adaptive Methods
Seungyub Han, Yeongmo Kim, Taehyun Cho, Jungwoo Lee
0
0
One of the objectives of continual learning is to prevent catastrophic forgetting in learning multiple tasks sequentially, and the existing solutions have been driven by the conceptualization of the plasticity-stability dilemma. However, the convergence of continual learning for each sequential task is less studied so far. In this paper, we provide a convergence analysis of memory-based continual learning with stochastic gradient descent and empirical evidence that training current tasks causes the cumulative degradation of previous tasks. We propose an adaptive method for nonconvex continual learning (NCCL), which adjusts step sizes of both previous and current tasks with the gradients. The proposed method can achieve the same convergence rate as the SGD method when the catastrophic forgetting term which we define in the paper is suppressed at each iteration. Further, we demonstrate that the proposed algorithm improves the performance of continual learning over existing methods for several image classification tasks.
4/16/2024
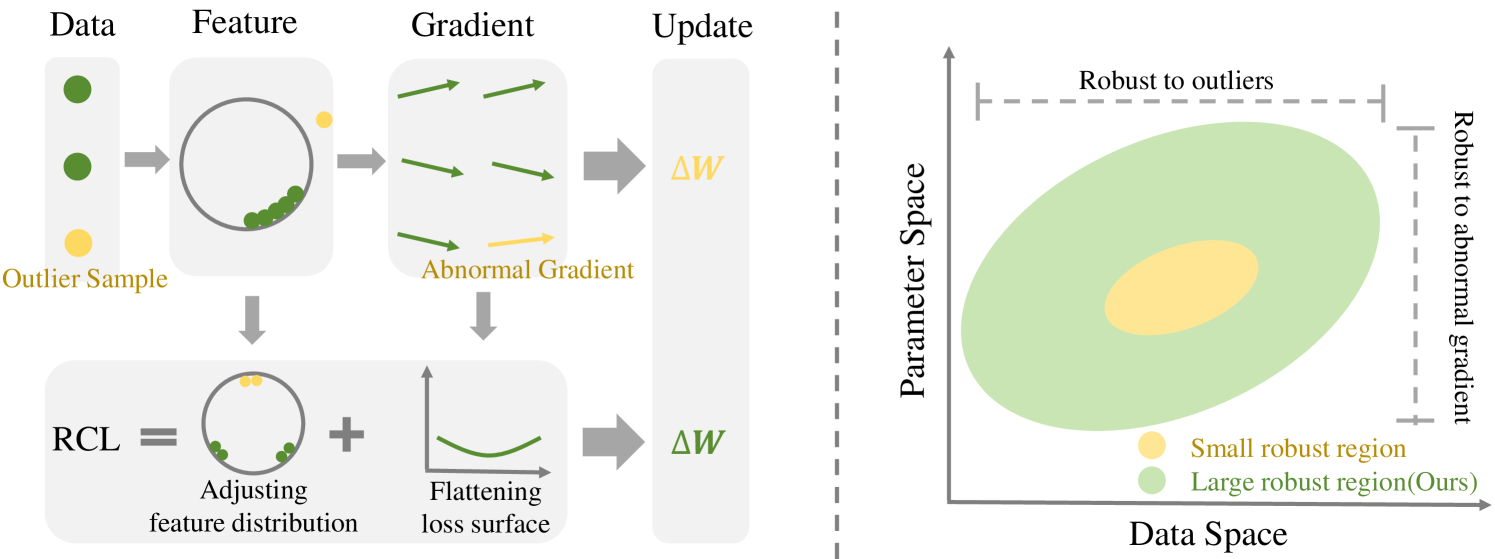
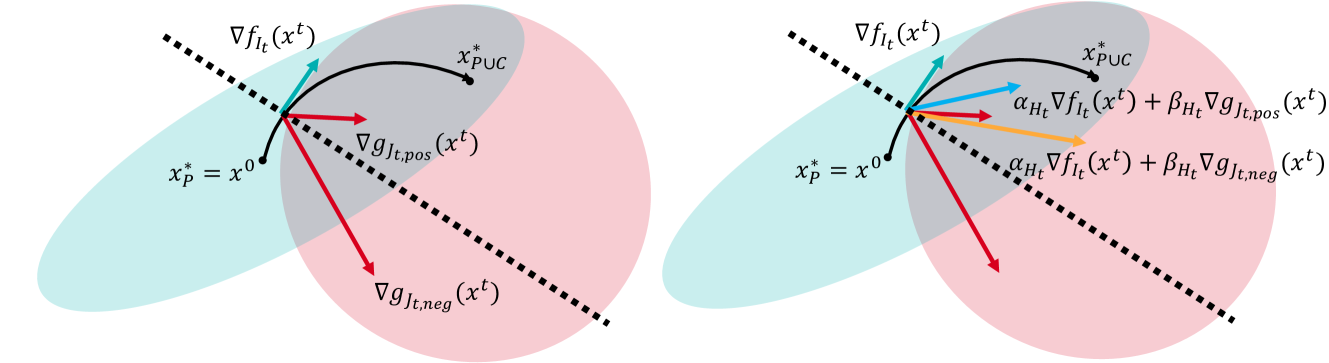
Improving Data-aware and Parameter-aware Robustness for Continual Learning
Hanxi Xiao, Fan Lyu
0
0
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
5/28/2024

Continual Learning of Diffusion Models with Generative Distillation
Sergi Masip, Pau Rodriguez, Tinne Tuytelaars, Gido M. van de Ven
0
0
Diffusion models are powerful generative models that achieve state-of-the-art performance in image synthesis. However, training them demands substantial amounts of data and computational resources. Continual learning would allow for incrementally learning new tasks and accumulating knowledge, thus enabling the reuse of trained models for further learning. One potentially suitable continual learning approach is generative replay, where a copy of a generative model trained on previous tasks produces synthetic data that are interleaved with data from the current task. However, standard generative replay applied to diffusion models results in a catastrophic loss in denoising capabilities. In this paper, we propose generative distillation, an approach that distils the entire reverse process of a diffusion model. We demonstrate that our approach substantially improves the continual learning performance of generative replay with only a modest increase in the computational costs.
5/21/2024