C${^2}$RL: Content and Context Representation Learning for Gloss-free Sign Language Translation and Retrieval

0

Sign in to get full access
Overview
- This paper introduces C2RL, a novel approach for learning content and context representations for gloss-free sign language translation and retrieval.
- C2RL aims to capture both the semantic meaning (content) and the visual-spatial information (context) of sign language without relying on gloss annotations.
- The proposed method uses self-supervised learning to extract these representations from unlabeled sign language videos, enabling more efficient and scalable sign language processing.
Plain English Explanation
Sign language is a visual-spatial language that uses hand gestures, facial expressions, and body movements to convey meaning. Traditionally, sign language processing has relied on gloss annotations, which are textual labels that describe each sign. However, creating these annotations is a labor-intensive process, limiting the scalability of sign language technology.
The C2RL approach proposed in this paper aims to overcome this limitation by learning sign language representations directly from the video data, without the need for gloss annotations. The key idea is to capture two essential aspects of sign language: the semantic meaning (content) and the visual-spatial information (context).
The content representation learning component learns to encode the meaning of the signs, while the context representation learning component captures the visual-spatial features, such as hand shapes, movements, and spatial relationships. By learning these complementary representations in a self-supervised manner, the model can effectively process sign language data without relying on manual annotations.
The benefits of this approach include more efficient and scalable sign language translation and retrieval, as well as the potential to enable new applications, such as sign language-based search and recommendation systems.
Technical Explanation
The C2RL framework consists of two main components: content representation learning and context representation learning.
The content representation learning component uses a pre-trained visual encoder to extract semantic features from the sign language videos. It then employs a self-supervised contrastive loss to align the video features with the corresponding text representations, which are obtained from a language model.
The context representation learning component focuses on capturing the visual-spatial information of the signs. It uses a spatio-temporal encoder to extract features related to hand shapes, movements, and spatial relationships. This component is also trained using a self-supervised contrastive loss, but in this case, the objective is to align the video features with the corresponding 3D hand and body pose information.
The experiments demonstrate that the C2RL approach outperforms several baseline methods on sign language translation and retrieval tasks, without relying on gloss annotations. The learned representations also show good transfer learning capabilities, improving performance on downstream tasks such as sign language recognition.
Critical Analysis
The C2RL approach presents a promising solution for addressing the annotation bottleneck in sign language processing. By learning content and context representations in a self-supervised manner, the method can effectively capture the semantic and visual-spatial aspects of sign language without requiring manual gloss annotations.
However, the paper acknowledges several limitations and avenues for future research:
- The experiments are conducted on relatively small-scale datasets, and the authors suggest that further scaling up the model and evaluating its performance on larger, more diverse sign language datasets would be valuable.
- The self-supervised learning approach relies on the availability of 3D hand and body pose information, which may not always be easily accessible. Exploring alternative strategies for context representation learning without this requirement could further improve the practicality of the method.
- The paper focuses on sign language translation and retrieval tasks, but the potential of the learned representations for other applications, such as sign language synthesis or automatic sign language generation, is not explored in depth.
Addressing these limitations and exploring additional applications of the C2RL framework could further strengthen the impact of this research in the field of sign language processing and accessibility.
Conclusion
The C2RL approach presented in this paper offers a novel solution for gloss-free sign language processing by learning content and context representations in a self-supervised manner. This method can enable more efficient and scalable sign language translation and retrieval, as well as potentially open up new applications, such as sign language-based search and recommendation systems.
The promising results and the identified avenues for future research suggest that the C2RL framework could make significant contributions to advancing the state-of-the-art in sign language technology and improving accessibility for the deaf and hard-of-hearing community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
C${^2}$RL: Content and Context Representation Learning for Gloss-free Sign Language Translation and Retrieval
Zhigang Chen, Benjia Zhou, Yiqing Huang, Jun Wan, Yibo Hu, Hailin Shi, Yanyan Liang, Zhen Lei, Du Zhang
Sign Language Representation Learning (SLRL) is crucial for a range of sign language-related downstream tasks such as Sign Language Translation (SLT) and Sign Language Retrieval (SLRet). Recently, many gloss-based and gloss-free SLRL methods have been proposed, showing promising performance. Among them, the gloss-free approach shows promise for strong scalability without relying on gloss annotations. However, it currently faces suboptimal solutions due to challenges in encoding the intricate, context-sensitive characteristics of sign language videos, mainly struggling to discern essential sign features using a non-monotonic video-text alignment strategy. Therefore, we introduce an innovative pretraining paradigm for gloss-free SLRL, called C${^2}$RL, in this paper. Specifically, rather than merely incorporating a non-monotonic semantic alignment of video and text to learn language-oriented sign features, we emphasize two pivotal aspects of SLRL: Implicit Content Learning (ICL) and Explicit Context Learning (ECL). ICL delves into the content of communication, capturing the nuances, emphasis, timing, and rhythm of the signs. In contrast, ECL focuses on understanding the contextual meaning of signs and converting them into equivalent sentences. Despite its simplicity, extensive experiments confirm that the joint optimization of ICL and ECL results in robust sign language representation and significant performance gains in gloss-free SLT and SLRet tasks. Notably, C${^2}$RL improves the BLEU-4 score by +5.3 on P14T, +10.6 on CSL-daily, +6.2 on OpenASL, and +1.3 on How2Sign. It also boosts the R@1 score by +8.3 on P14T, +14.4 on CSL-daily, and +5.9 on How2Sign. Additionally, we set a new baseline for the OpenASL dataset in the SLRet task.
Read more8/20/2024
💬
0
Improving Gloss-free Sign Language Translation by Reducing Representation Density
Jinhui Ye, Xing Wang, Wenxiang Jiao, Junwei Liang, Hui Xiong
Gloss-free sign language translation (SLT) aims to develop well-performing SLT systems with no requirement for the costly gloss annotations, but currently still lags behind gloss-based approaches significantly. In this paper, we identify a representation density problem that could be a bottleneck in restricting the performance of gloss-free SLT. Specifically, the representation density problem describes that the visual representations of semantically distinct sign gestures tend to be closely packed together in feature space, which makes gloss-free methods struggle with distinguishing different sign gestures and suffer from a sharp performance drop. To address the representation density problem, we introduce a simple but effective contrastive learning strategy, namely SignCL, which encourages gloss-free models to learn more discriminative feature representation in a self-supervised manner. Our experiments demonstrate that the proposed SignCL can significantly reduce the representation density and improve performance across various translation frameworks. Specifically, SignCL achieves a significant improvement in BLEU score for the Sign Language Transformer and GFSLT-VLP on the CSL-Daily dataset by 39% and 46%, respectively, without any increase of model parameters. Compared to Sign2GPT, a state-of-the-art method based on large-scale pre-trained vision and language models, SignCL achieves better performance with only 35% of its parameters. Implementation and Checkpoints are available at https://github.com/JinhuiYE/SignCL.
Read more5/24/2024
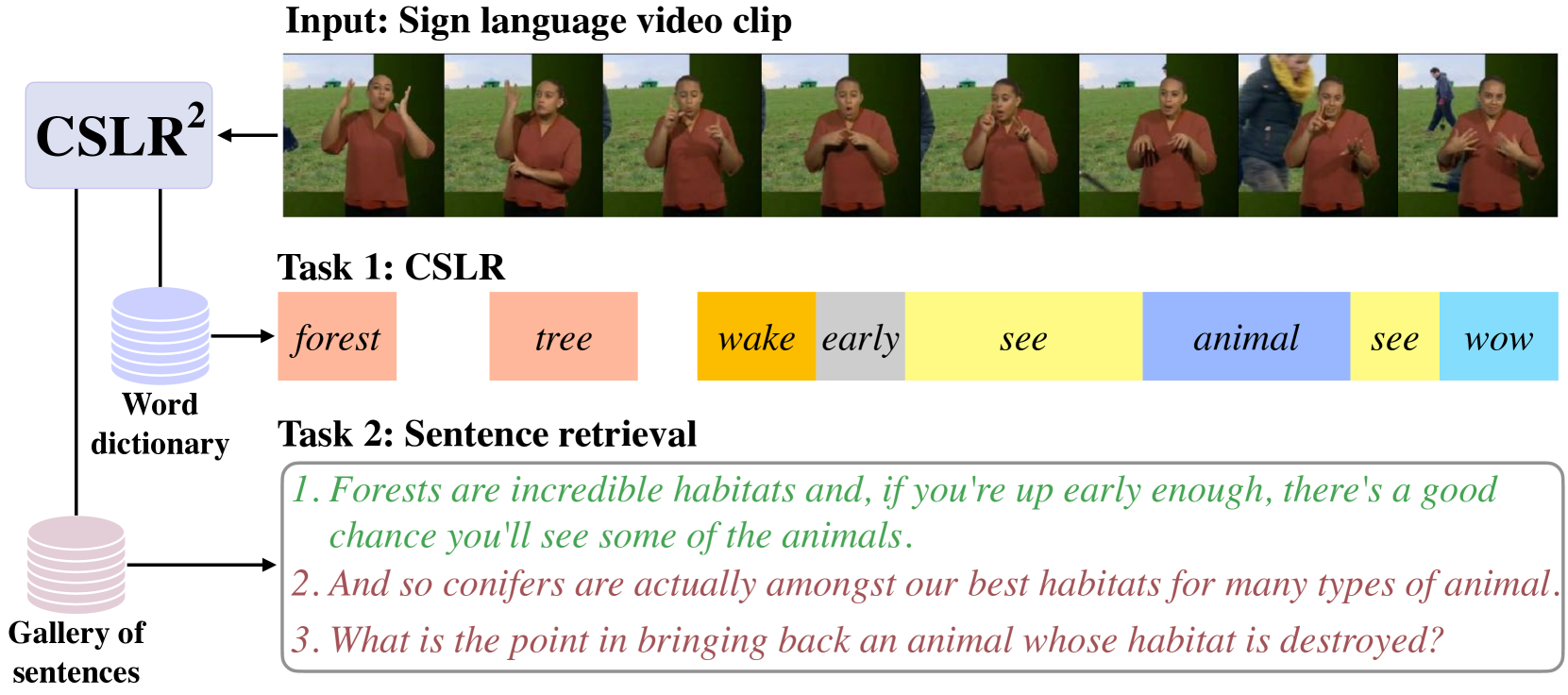
0
A Tale of Two Languages: Large-Vocabulary Continuous Sign Language Recognition from Spoken Language Supervision
Charles Raude, K R Prajwal, Liliane Momeni, Hannah Bull, Samuel Albanie, Andrew Zisserman, Gul Varol
In this work, our goals are two fold: large-vocabulary continuous sign language recognition (CSLR), and sign language retrieval. To this end, we introduce a multi-task Transformer model, CSLR2, that is able to ingest a signing sequence and output in a joint embedding space between signed language and spoken language text. To enable CSLR evaluation in the large-vocabulary setting, we introduce new dataset annotations that have been manually collected. These provide continuous sign-level annotations for six hours of test videos, and will be made publicly available. We demonstrate that by a careful choice of loss functions, training the model for both the CSLR and retrieval tasks is mutually beneficial in terms of performance -- retrieval improves CSLR performance by providing context, while CSLR improves retrieval with more fine-grained supervision. We further show the benefits of leveraging weak and noisy supervision from large-vocabulary datasets such as BOBSL, namely sign-level pseudo-labels, and English subtitles. Our model significantly outperforms the previous state of the art on both tasks.
Read more5/17/2024

0
Scaling up Multimodal Pre-training for Sign Language Understanding
Wengang Zhou, Weichao Zhao, Hezhen Hu, Zecheng Li, Houqiang Li
Sign language serves as the primary meaning of communication for the deaf-mute community. Different from spoken language, it commonly conveys information by the collaboration of manual features, i.e., hand gestures and body movements, and non-manual features, i.e., facial expressions and mouth cues. To facilitate communication between the deaf-mute and hearing people, a series of sign language understanding (SLU) tasks have been studied in recent years, including isolated/continuous sign language recognition (ISLR/CSLR), gloss-free sign language translation (GF-SLT) and sign language retrieval (SL-RT). Sign language recognition and translation aims to understand the semantic meaning conveyed by sign languages from gloss-level and sentence-level, respectively. In contrast, SL-RT focuses on retrieving sign videos or corresponding texts from a closed-set under the query-by-example search paradigm. These tasks investigate sign language topics from diverse perspectives and raise challenges in learning effective representation of sign language videos. To advance the development of sign language understanding, exploring a generalized model that is applicable across various SLU tasks is a profound research direction.
Read more8/19/2024