CECILIA: Comprehensive Secure Machine Learning Framework

0
✨
Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
CECILIA: Comprehensive Secure Machine Learning Framework
Ali Burak Unal, Nico Pfeifer, Mete Akgun
Since ML algorithms have proven their success in many different applications, there is also a big interest in privacy preserving (PP) ML methods for building models on sensitive data. Moreover, the increase in the number of data sources and the high computational power required by those algorithms force individuals to outsource the training and/or the inference of a ML model to the clouds providing such services. To address this, we propose a secure 3-party computation framework, CECILIA, offering PP building blocks to enable complex operations privately. In addition to the adapted and common operations like addition and multiplication, it offers multiplexer, most significant bit and modulus conversion. The first two are novel in terms of methodology and the last one is novel in terms of both functionality and methodology. CECILIA also has two complex novel methods, which are the exact exponential of a public base raised to the power of a secret value and the inverse square root of a secret Gram matrix. We use CECILIA to realize the private inference on pre-trained RKNs, which require more complex operations than most other DNNs, on the structural classification of proteins as the first study ever accomplishing the PP inference on RKNs. In addition to the successful private computation of basic building blocks, the results demonstrate that we perform the exact and fully private exponential computation, which is done by approximation in the literature so far. Moreover, they also show that we compute the exact inverse square root of a secret Gram matrix up to a certain privacy level, which has not been addressed in the literature at all. We also analyze the scalability of CECILIA to various settings on a synthetic dataset. The framework shows a great promise to make other ML algorithms as well as further computations privately computable by the building blocks of the framework.
Read more5/28/2024
🏷️
0
Machine Learning with Confidential Computing: A Systematization of Knowledge
Fan Mo, Zahra Tarkhani, Hamed Haddadi
Privacy and security challenges in Machine Learning (ML) have become increasingly severe, along with ML's pervasive development and the recent demonstration of large attack surfaces. As a mature system-oriented approach, Confidential Computing has been utilized in both academia and industry to mitigate privacy and security issues in various ML scenarios. In this paper, the conjunction between ML and Confidential Computing is investigated. We systematize the prior work on Confidential Computing-assisted ML techniques that provide i) confidentiality guarantees and ii) integrity assurances, and discuss their advanced features and drawbacks. Key challenges are further identified, and we provide dedicated analyses of the limitations in existing Trusted Execution Environment (TEE) systems for ML use cases. Finally, prospective works are discussed, including grounded privacy definitions for closed-loop protection, partitioned executions of efficient ML, dedicated TEE-assisted designs for ML, TEE-aware ML, and ML full pipeline guarantees. By providing these potential solutions in our systematization of knowledge, we aim to build the bridge to help achieve a much stronger TEE-enabled ML for privacy guarantees without introducing computation and system costs.
Read more6/4/2024
0
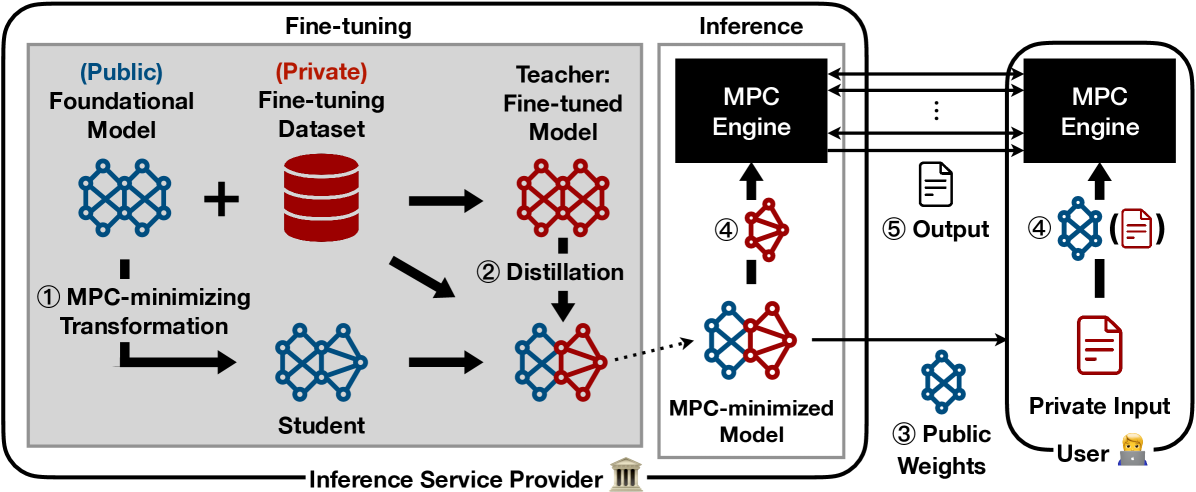
MPC-Minimized Secure LLM Inference
Deevashwer Rathee, Dacheng Li, Ion Stoica, Hao Zhang, Raluca Popa
Many inference services based on large language models (LLMs) pose a privacy concern, either revealing user prompts to the service or the proprietary weights to the user. Secure inference offers a solution to this problem through secure multi-party computation (MPC), however, it is still impractical for modern LLM workload due to the large overhead imposed by MPC. To address this overhead, we propose Marill, a framework that adapts LLM fine-tuning to minimize MPC usage during secure inference. Marill introduces high-level architectural changes during fine-tuning that significantly reduce the number of expensive operations needed within MPC during inference, by removing some and relocating others outside MPC without compromising security. As a result, Marill-generated models are more efficient across all secure inference protocols and our approach complements MPC-friendly approximations for such operations. Compared to standard fine-tuning, Marill results in 3.6-11.3x better runtime and 2.4-6.9x better communication during secure inference across various MPC settings, while typically preserving over 90% performance across downstream tasks.
Read more8/9/2024
0
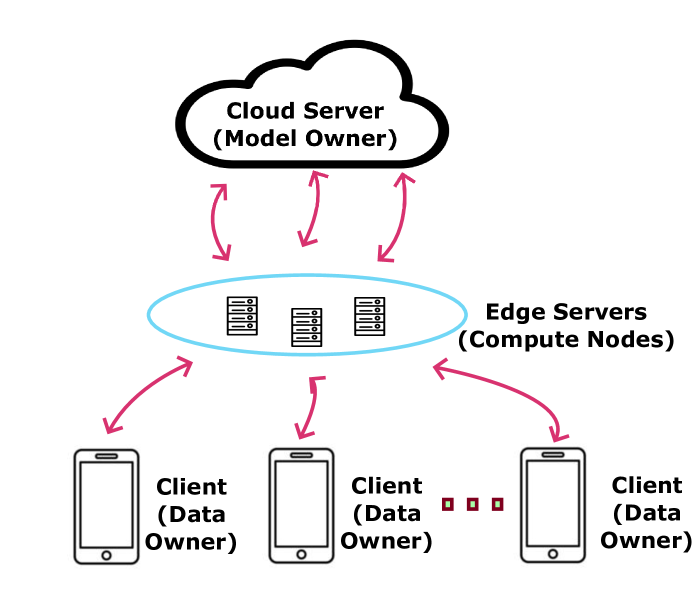
Privacy-Preserving Model-Distributed Inference at the Edge
Fatemeh Jafarian Dehkordi, Yasaman Keshtkarjahromi, Hulya Seferoglu
This paper focuses on designing a privacy-preserving Machine Learning (ML) inference protocol for a hierarchical setup, where clients own/generate data, model owners (cloud servers) have a pre-trained ML model, and edge servers perform ML inference on clients' data using the cloud server's ML model. Our goal is to speed up ML inference while providing privacy to both data and the ML model. Our approach (i) uses model-distributed inference (model parallelization) at the edge servers and (ii) reduces the amount of communication to/from the cloud server. Our privacy-preserving hierarchical model-distributed inference, privateMDI design uses additive secret sharing and linearly homomorphic encryption to handle linear calculations in the ML inference, and garbled circuit and a novel three-party oblivious transfer are used to handle non-linear functions. privateMDI consists of offline and online phases. We designed these phases in a way that most of the data exchange is done in the offline phase while the communication overhead of the online phase is reduced. In particular, there is no communication to/from the cloud server in the online phase, and the amount of communication between the client and edge servers is minimized. The experimental results demonstrate that privateMDI significantly reduces the ML inference time as compared to the baselines.
Read more9/17/2024