CELA: Cost-Efficient Language Model Alignment for CTR Prediction

0
Sign in to get full access
Overview
- Proposes a cost-efficient approach called CELA (Cost-Efficient Language Model Alignment) for click-through rate (CTR) prediction in recommender systems
- Leverages pre-trained language models and cross-modal alignment to capture textual features in a more efficient manner
- Aims to improve CTR prediction performance while reducing computational and memory costs compared to existing approaches
Plain English Explanation
CELA is a new method for predicting how likely users are to click on recommended items in an online system, such as an e-commerce website or social media platform. Traditional approaches to this problem often rely on complex machine learning models that are computationally intensive and require a lot of memory.
CELA takes a different approach by using pre-trained language models, which are AI systems that have been trained on massive amounts of text data to understand and generate human language. These language models can capture rich textual features that are relevant for predicting user clicks. However, directly using these language models can still be costly.
To address this, CELA aligns the language model with the specific task of CTR prediction in a cost-efficient manner. This means it finds a way to adapt the language model to work well for click prediction, while minimizing the computational resources required. The key insight is that CELA can identify the most relevant parts of the language model and selectively activate them, rather than using the entire model.
By doing this, CELA is able to achieve better CTR prediction performance than existing approaches, while also being more efficient in terms of the computational power and memory required. This could allow companies to deploy more accurate recommender systems on a wider range of devices and platforms, ultimately improving the user experience.
Technical Explanation
CELA builds on the idea of using pre-trained language models to capture textual features for CTR prediction, as explored in previous work such as FLIP: Towards Fine-grained Alignment between ID Embeddings and Pre-trained Language Models and CALREC: Contrastive Alignment between Generative LLMs and Sequential Recommendation. However, CELA introduces a more cost-efficient approach to this cross-modal alignment.
The key components of CELA are:
-
Selective Activation: Instead of using the entire pre-trained language model, CELA identifies the most relevant parts of the model for the CTR prediction task and selectively activates them. This is done through a gating mechanism that learns to focus on the most informative features.
-
Alignment Regularization: CELA aligns the selectively activated language model with the CTR prediction task by introducing a regularization term that encourages the model to capture textual features that are useful for predicting clicks.
-
Efficient Inference: By selectively activating only the most relevant parts of the language model, CELA can perform CTR prediction in a more computationally and memory-efficient manner compared to using the full language model.
The authors evaluate CELA on several real-world CTR prediction datasets and demonstrate that it outperforms state-of-the-art approaches in terms of both prediction accuracy and efficiency. CELA is also shown to be robust to different language models and can be easily integrated into existing recommender system architectures.
Critical Analysis
The CELA paper presents a novel and promising approach to leveraging pre-trained language models for CTR prediction in a cost-efficient manner. The authors' key insights around selective activation and alignment regularization are well-motivated and appear to be effective in practice.
One potential limitation is that the paper does not provide a deep analysis of the specific textual features or patterns that CELA is able to capture and leverage for improved CTR prediction. A more detailed exploration of this could help better understand the model's inner workings and potentially inspire further innovations.
Additionally, while the authors demonstrate CELA's efficiency compared to using the full language model, there may be opportunities to further optimize the approach, such as by exploring more advanced techniques for selectively activating the language model or by incorporating additional efficiency-enhancing methods.
It would also be valuable to see CELA evaluated on a broader range of recommender system tasks and datasets, as well as in real-world deployment scenarios, to better understand its broader applicability and potential limitations.
Conclusion
The CELA paper presents an innovative approach to leveraging pre-trained language models for cost-efficient CTR prediction in recommender systems. By selectively activating the most relevant parts of the language model and aligning it with the CTR prediction task, CELA is able to achieve strong performance while requiring fewer computational resources compared to existing methods.
This work has the potential to enable more accurate and efficient recommender systems, which could lead to improved user experiences and better outcomes for businesses across a wide range of online platforms and applications. As the use of large language models continues to grow, techniques like CELA will become increasingly important for making these powerful AI systems more accessible and practical for real-world use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CELA: Cost-Efficient Language Model Alignment for CTR Prediction
Xingmei Wang, Weiwen Liu, Xiaolong Chen, Qi Liu, Xu Huang, Defu Lian, Xiangyang Li, Yasheng Wang, Zhenhua Dong, Ruiming Tang
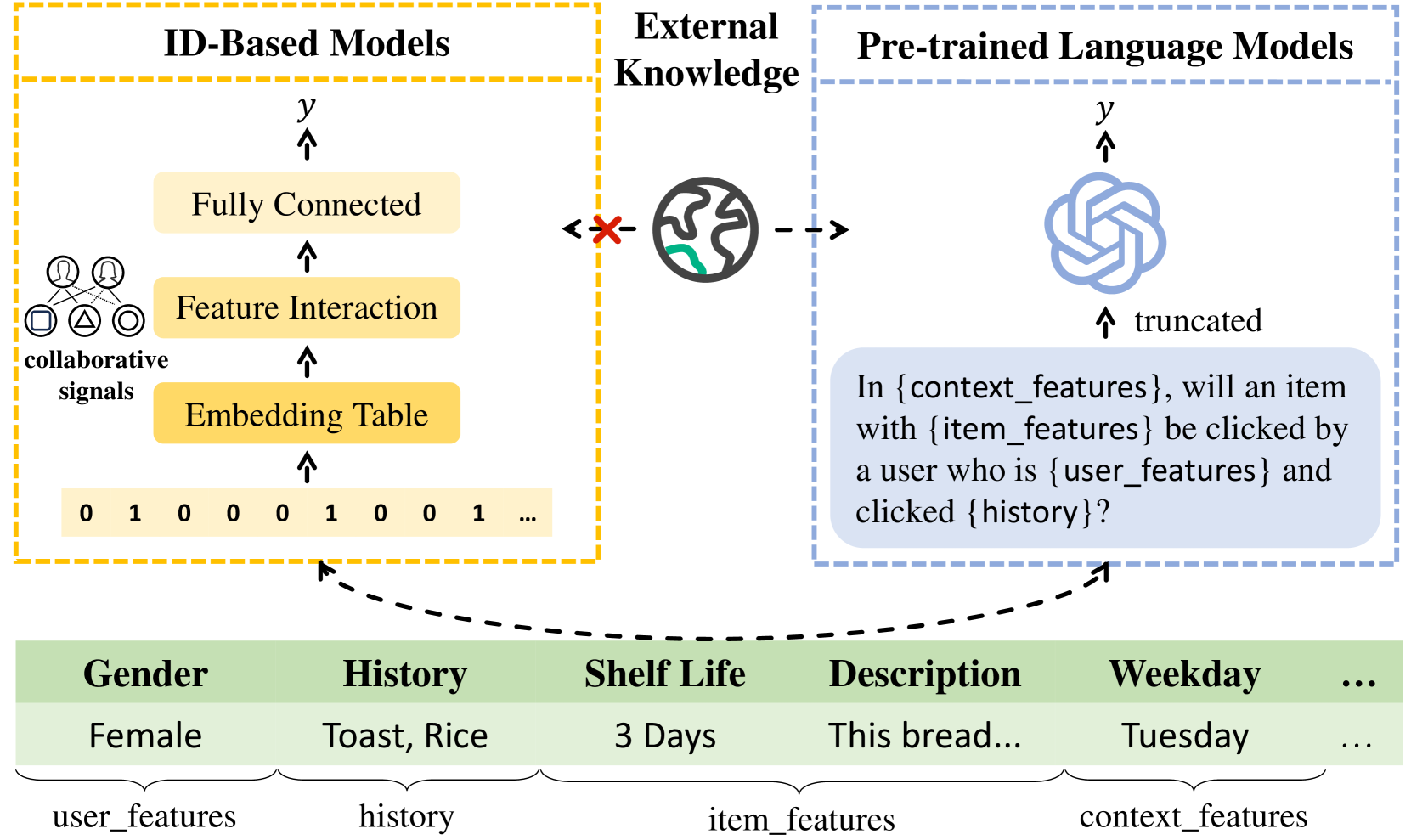
Click-Through Rate (CTR) prediction holds a paramount position in recommender systems. The prevailing ID-based paradigm underperforms in cold-start scenarios due to the skewed distribution of feature frequency. Additionally, the utilization of a single modality fails to exploit the knowledge contained within textual features. Recent efforts have sought to mitigate these challenges by integrating Pre-trained Language Models (PLMs). They design hard prompts to structure raw features into text for each interaction and then apply PLMs for text processing. With external knowledge and reasoning capabilities, PLMs extract valuable information even in cases of sparse interactions. Nevertheless, compared to ID-based models, pure text modeling degrades the efficacy of collaborative filtering, as well as feature scalability and efficiency during both training and inference. To address these issues, we propose textbf{C}ost-textbf{E}fficient textbf{L}anguage Model textbf{A}lignment (textbf{CELA}) for CTR prediction. CELA incorporates textual features and language models while preserving the collaborative filtering capabilities of ID-based models. This model-agnostic framework can be equipped with plug-and-play textual features, with item-level alignment enhancing the utilization of external information while maintaining training and inference efficiency. Through extensive offline experiments, CELA demonstrates superior performance compared to state-of-the-art methods. Furthermore, an online A/B test conducted on an industrial App recommender system showcases its practical effectiveness, solidifying the potential for real-world applications of CELA.
Read more6/19/2024
💬
0
FLIP: Towards Fine-grained Alignment between ID-based Models and Pretrained Language Models for CTR Prediction
Hangyu Wang, Jianghao Lin, Xiangyang Li, Bo Chen, Chenxu Zhu, Ruiming Tang, Weinan Zhang, Yong Yu
Click-through rate (CTR) prediction plays as a core function module in various personalized online services. The traditional ID-based models for CTR prediction take as inputs the one-hot encoded ID features of tabular modality, which capture the collaborative signals via feature interaction modeling. But the one-hot encoding discards the semantic information conceived in the original feature texts. Recently, the emergence of Pretrained Language Models (PLMs) has given rise to another paradigm, which takes as inputs the sentences of textual modality obtained by hard prompt templates and adopts PLMs to extract the semantic knowledge. However, PLMs generally tokenize the input text data into subword tokens and ignore field-wise collaborative signals. Therefore, these two lines of research focus on different characteristics of the same input data (i.e., textual and tabular modalities), forming a distinct complementary relationship with each other. In this paper, we propose to conduct Fine-grained feature-level ALignment between ID-based Models and Pretrained Language Models (FLIP) for CTR prediction. We design a novel joint reconstruction pretraining task for both masked language and tabular modeling. Specifically, the masked data of one modality (i.e., tokens or features) has to be recovered with the help of the other modality, which establishes the feature-level interaction and alignment via sufficient mutual information extraction between dual modalities. Moreover, we propose to jointly finetune the ID-based model and PLM for downstream CTR prediction tasks, thus achieving superior performance by combining the advantages of both models. Extensive experiments on three real-world datasets demonstrate that FLIP outperforms SOTA baselines, and is highly compatible for various ID-based models and PLMs. The code is at url{https://github.com/justarter/FLIP}.
Read more5/8/2024
💬
0
ClickPrompt: CTR Models are Strong Prompt Generators for Adapting Language Models to CTR Prediction
Jianghao Lin, Bo Chen, Hangyu Wang, Yunjia Xi, Yanru Qu, Xinyi Dai, Kangning Zhang, Ruiming Tang, Yong Yu, Weinan Zhang
Click-through rate (CTR) prediction has become increasingly indispensable for various Internet applications. Traditional CTR models convert the multi-field categorical data into ID features via one-hot encoding, and extract the collaborative signals among features. Such a paradigm suffers from the problem of semantic information loss. Another line of research explores the potential of pretrained language models (PLMs) for CTR prediction by converting input data into textual sentences through hard prompt templates. Although semantic signals are preserved, they generally fail to capture the collaborative information (e.g., feature interactions, pure ID features), not to mention the unacceptable inference overhead brought by the huge model size. In this paper, we aim to model both the semantic knowledge and collaborative knowledge for accurate CTR estimation, and meanwhile address the inference inefficiency issue. To benefit from both worlds and close their gaps, we propose a novel model-agnostic framework (i.e., ClickPrompt), where we incorporate CTR models to generate interaction-aware soft prompts for PLMs. We design a prompt-augmented masked language modeling (PA-MLM) pretraining task, where PLM has to recover the masked tokens based on the language context, as well as the soft prompts generated by CTR model. The collaborative and semantic knowledge from ID and textual features would be explicitly aligned and interacted via the prompt interface. Then, we can either tune the CTR model with PLM for superior performance, or solely tune the CTR model without PLM for inference efficiency. Experiments on four real-world datasets validate the effectiveness of ClickPrompt compared with existing baselines.
Read more6/27/2024

0
Towards Aligning Language Models with Textual Feedback
Sauc Abadal Lloret, Shehzaad Dhuliawala, Keerthiram Murugesan, Mrinmaya Sachan
We present ALT (ALignment with Textual feedback), an approach that aligns language models with user preferences expressed in text. We argue that text offers greater expressiveness, enabling users to provide richer feedback than simple comparative preferences and this richer feedback can lead to more efficient and effective alignment. ALT aligns the model by conditioning its generation on the textual feedback. Our method relies solely on language modeling techniques and requires minimal hyper-parameter tuning, though it still presents the main benefits of RL-based alignment algorithms and can effectively learn from textual feedback. We explore the efficacy and efficiency of textual feedback across different tasks such as toxicity reduction, summarization, and dialog response generation. We find that ALT outperforms PPO for the task of toxicity reduction while being able to match its performance on summarization with only 20% of the samples. We also explore how ALT can be used with feedback provided by an existing LLM where we explore an LLM providing constrained and unconstrained textual feedback. We also outline future directions to align models with natural language feedback.
Read more7/25/2024