FLIP: Towards Fine-grained Alignment between ID-based Models and Pretrained Language Models for CTR Prediction

0
💬
Sign in to get full access
Overview
- Click-through rate (CTR) prediction is a crucial function in personalized online services.
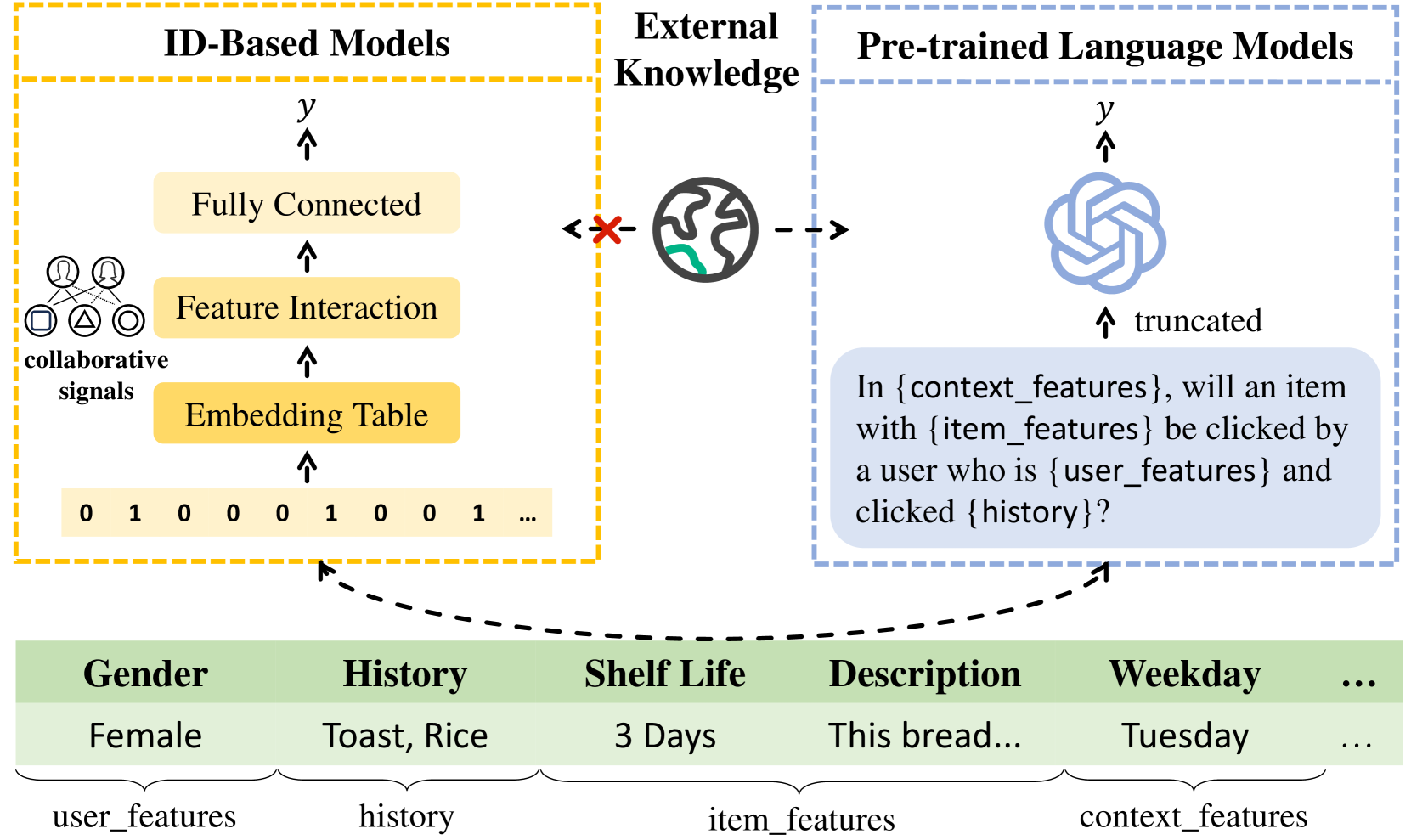
- Traditional ID-based models use one-hot encoded ID features, capturing collaborative signals through feature interaction modeling.
- However, one-hot encoding discards semantic information from the original feature texts.
- Pretrained Language Models (PLMs) can extract semantic knowledge from textual input, but they ignore field-wise collaborative signals.
- These two approaches focus on different characteristics of the input data, forming a complementary relationship.
Plain English Explanation
The paper presents a novel approach called FLIP (Fine-grained feature-level ALignment between ID-based Models and Pretrained Language Models) for improving click-through rate (CTR) prediction in personalized online services. Traditional ID-based models for CTR prediction use one-hot encoded IDs as input, which can capture collaborative signals through feature interaction modeling. However, this approach discards the semantic information contained in the original feature texts. On the other hand, the emergence of Pretrained Language Models (PLMs) has led to a different approach, where the input is the textual content obtained through hard prompt templates, and the PLM is used to extract the semantic knowledge.
The key idea behind FLIP is to establish a fine-grained feature-level alignment between the ID-based models and the PLMs. This is achieved through a novel joint reconstruction pretraining task, where the masked data of one modality (tokens or features) has to be recovered with the help of the other modality. This process helps to extract mutual information between the dual modalities and establish feature-level interaction and alignment. Furthermore, the authors propose to jointly fine-tune the ID-based model and the PLM for the downstream CTR prediction tasks, combining the advantages of both models.
Technical Explanation
The paper proposes the FLIP (Fine-grained feature-level ALignment between ID-based Models and Pretrained Language Models) approach for CTR prediction. FLIP aims to bridge the gap between the traditional ID-based models and the emerging PLM-based models, which focus on different characteristics of the input data.
The key technical contributions of the paper are as follows:
-
Joint Reconstruction Pretraining: The authors design a novel joint reconstruction pretraining task, where the masked data of one modality (tokens or features) has to be recovered with the help of the other modality. This establishes feature-level interaction and alignment via mutual information extraction between the dual modalities.
-
Joint Finetuning: The authors propose to jointly fine-tune the ID-based model and the PLM for the downstream CTR prediction tasks, combining the advantages of both models.
The authors conduct extensive experiments on three real-world datasets, demonstrating that FLIP outperforms state-of-the-art baselines and is highly compatible with various ID-based models and PLMs.
Critical Analysis
The paper presents a promising approach to improve CTR prediction by leveraging the complementary strengths of ID-based models and PLMs. However, the authors do not discuss potential limitations or caveats of their approach. For example, the performance gains may be limited to specific datasets or scenarios, and the computational overhead of the joint pretraining and finetuning process could be a concern for real-world deployment.
Additionally, the authors could have explored alternative approaches for aligning the ID-based and PLM-based models, such as contrastive learning or other alignment techniques. The paper also lacks a deeper discussion on the potential societal and ethical implications of using such models in personalized online services.
Conclusion
The FLIP approach presented in this paper represents an innovative way to combine the strengths of ID-based models and Pretrained Language Models for improving click-through rate prediction in personalized online services. By establishing fine-grained feature-level alignment between the two modalities, the authors have demonstrated significant performance improvements over state-of-the-art baselines. This research highlights the potential for further advancements in the field of recommendation systems, which could lead to more engaging and personalized online experiences for users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
FLIP: Towards Fine-grained Alignment between ID-based Models and Pretrained Language Models for CTR Prediction
Hangyu Wang, Jianghao Lin, Xiangyang Li, Bo Chen, Chenxu Zhu, Ruiming Tang, Weinan Zhang, Yong Yu
Click-through rate (CTR) prediction plays as a core function module in various personalized online services. The traditional ID-based models for CTR prediction take as inputs the one-hot encoded ID features of tabular modality, which capture the collaborative signals via feature interaction modeling. But the one-hot encoding discards the semantic information conceived in the original feature texts. Recently, the emergence of Pretrained Language Models (PLMs) has given rise to another paradigm, which takes as inputs the sentences of textual modality obtained by hard prompt templates and adopts PLMs to extract the semantic knowledge. However, PLMs generally tokenize the input text data into subword tokens and ignore field-wise collaborative signals. Therefore, these two lines of research focus on different characteristics of the same input data (i.e., textual and tabular modalities), forming a distinct complementary relationship with each other. In this paper, we propose to conduct Fine-grained feature-level ALignment between ID-based Models and Pretrained Language Models (FLIP) for CTR prediction. We design a novel joint reconstruction pretraining task for both masked language and tabular modeling. Specifically, the masked data of one modality (i.e., tokens or features) has to be recovered with the help of the other modality, which establishes the feature-level interaction and alignment via sufficient mutual information extraction between dual modalities. Moreover, we propose to jointly finetune the ID-based model and PLM for downstream CTR prediction tasks, thus achieving superior performance by combining the advantages of both models. Extensive experiments on three real-world datasets demonstrate that FLIP outperforms SOTA baselines, and is highly compatible for various ID-based models and PLMs. The code is at url{https://github.com/justarter/FLIP}.
Read more5/8/2024
💬
0
ClickPrompt: CTR Models are Strong Prompt Generators for Adapting Language Models to CTR Prediction
Jianghao Lin, Bo Chen, Hangyu Wang, Yunjia Xi, Yanru Qu, Xinyi Dai, Kangning Zhang, Ruiming Tang, Yong Yu, Weinan Zhang
Click-through rate (CTR) prediction has become increasingly indispensable for various Internet applications. Traditional CTR models convert the multi-field categorical data into ID features via one-hot encoding, and extract the collaborative signals among features. Such a paradigm suffers from the problem of semantic information loss. Another line of research explores the potential of pretrained language models (PLMs) for CTR prediction by converting input data into textual sentences through hard prompt templates. Although semantic signals are preserved, they generally fail to capture the collaborative information (e.g., feature interactions, pure ID features), not to mention the unacceptable inference overhead brought by the huge model size. In this paper, we aim to model both the semantic knowledge and collaborative knowledge for accurate CTR estimation, and meanwhile address the inference inefficiency issue. To benefit from both worlds and close their gaps, we propose a novel model-agnostic framework (i.e., ClickPrompt), where we incorporate CTR models to generate interaction-aware soft prompts for PLMs. We design a prompt-augmented masked language modeling (PA-MLM) pretraining task, where PLM has to recover the masked tokens based on the language context, as well as the soft prompts generated by CTR model. The collaborative and semantic knowledge from ID and textual features would be explicitly aligned and interacted via the prompt interface. Then, we can either tune the CTR model with PLM for superior performance, or solely tune the CTR model without PLM for inference efficiency. Experiments on four real-world datasets validate the effectiveness of ClickPrompt compared with existing baselines.
Read more6/27/2024
0
CELA: Cost-Efficient Language Model Alignment for CTR Prediction
Xingmei Wang, Weiwen Liu, Xiaolong Chen, Qi Liu, Xu Huang, Defu Lian, Xiangyang Li, Yasheng Wang, Zhenhua Dong, Ruiming Tang
Click-Through Rate (CTR) prediction holds a paramount position in recommender systems. The prevailing ID-based paradigm underperforms in cold-start scenarios due to the skewed distribution of feature frequency. Additionally, the utilization of a single modality fails to exploit the knowledge contained within textual features. Recent efforts have sought to mitigate these challenges by integrating Pre-trained Language Models (PLMs). They design hard prompts to structure raw features into text for each interaction and then apply PLMs for text processing. With external knowledge and reasoning capabilities, PLMs extract valuable information even in cases of sparse interactions. Nevertheless, compared to ID-based models, pure text modeling degrades the efficacy of collaborative filtering, as well as feature scalability and efficiency during both training and inference. To address these issues, we propose textbf{C}ost-textbf{E}fficient textbf{L}anguage Model textbf{A}lignment (textbf{CELA}) for CTR prediction. CELA incorporates textual features and language models while preserving the collaborative filtering capabilities of ID-based models. This model-agnostic framework can be equipped with plug-and-play textual features, with item-level alignment enhancing the utilization of external information while maintaining training and inference efficiency. Through extensive offline experiments, CELA demonstrates superior performance compared to state-of-the-art methods. Furthermore, an online A/B test conducted on an industrial App recommender system showcases its practical effectiveness, solidifying the potential for real-world applications of CELA.
Read more6/19/2024
🧪
0
ID-centric Pre-training for Recommendation
Yiqing Wu, Ruobing Xie, Zhao Zhang, Fuzhen Zhuang, Xu Zhang, Leyu Lin, Zhanhui Kang, Yongjun Xu
Classical sequential recommendation models generally adopt ID embeddings to store knowledge learned from user historical behaviors and represent items. However, these unique IDs are challenging to be transferred to new domains. With the thriving of pre-trained language model (PLM), some pioneer works adopt PLM for pre-trained recommendation, where modality information (e.g., text) is considered universal across domains via PLM. Unfortunately, the behavioral information in ID embeddings is still verified to be dominating in PLM-based recommendation models compared to modality information and thus limits these models' performance. In this work, we propose a novel ID-centric recommendation pre-training paradigm (IDP), which directly transfers informative ID embeddings learned in pre-training domains to item representations in new domains. Specifically, in pre-training stage, besides the ID-based sequential model for recommendation, we also build a Cross-domain ID-matcher (CDIM) learned by both behavioral and modality information. In the tuning stage, modality information of new domain items is regarded as a cross-domain bridge built by CDIM. We first leverage the textual information of downstream domain items to retrieve behaviorally and semantically similar items from pre-training domains using CDIM. Next, these retrieved pre-trained ID embeddings, rather than certain textual embeddings, are directly adopted to generate downstream new items' embeddings. Through extensive experiments on real-world datasets, both in cold and warm settings, we demonstrate that our proposed model significantly outperforms all baselines. Codes will be released upon acceptance.
Read more5/8/2024