Cell-Free Multi-User MIMO Equalization via In-Context Learning
2404.05538
0
0

Abstract
Large pre-trained sequence models, such as transformers, excel as few-shot learners capable of in-context learning (ICL). In ICL, a model is trained to adapt its operation to a new task based on limited contextual information, typically in the form of a few training examples for the given task. Previous work has explored the use of ICL for channel equalization in single-user multi-input and multiple-output (MIMO) systems. In this work, we demonstrate that ICL can be also used to tackle the problem of multi-user equalization in cell-free MIMO systems with limited fronthaul capacity. In this scenario, a task is defined by channel statistics, signal-to-noise ratio, and modulation schemes. The context encompasses the users' pilot sequences, the corresponding quantized received signals, and the current received data signal. Different prompt design strategies are proposed and evaluated that encompass also large-scale fading and modulation information. Experiments demonstrate that ICL-based equalization provides estimates with lower mean squared error as compared to the linear minimum mean squared error equalizer, especially in the presence of limited fronthaul capacity and pilot contamination.
Create account to get full access
Overview
- This paper explores a novel approach called "cell-free multi-user MIMO equalization via in-context learning" for improving wireless communications in scenarios with multiple users and antennas.
- The key ideas involve using transformer models and in-context learning to perform equalization - the process of compensating for distortions in wireless signals.
- The proposed method aims to enhance performance in cell-free massive MIMO systems, where multiple antennas are distributed rather than co-located.
Plain English Explanation
In wireless communications, multiple users often need to share the same radio spectrum and transmit data simultaneously. This can lead to interference between the signals, making it difficult for the receiver to accurately decode the intended message.
The researchers in this paper propose a clever solution using transformer models and in-context learning. Transformer models are a type of machine learning architecture that have shown impressive results in various language processing tasks. In this case, the researchers apply transformers to the problem of equalization - the process of compensating for distortions in the wireless signal.
The key insight is that by leveraging in-context learning, the transformer model can adapt its equalization strategy on-the-fly based on the current wireless environment, rather than using a one-size-fits-all approach. This allows the system to better handle the dynamic interference patterns that arise in cell-free massive MIMO settings, where the antennas are distributed rather than co-located.
The proposed method has the potential to significantly improve the performance and reliability of wireless communications, especially in scenarios with many users and antennas. This could lead to more efficient use of the radio spectrum and better quality of service for applications like high-speed internet, video streaming, and remote healthcare.
Technical Explanation
The paper presents a novel approach for cell-free multi-user MIMO equalization using transformer models and in-context learning. In a cell-free MIMO system, multiple antennas are distributed throughout the coverage area rather than co-located, which can introduce additional challenges for signal processing and equalization.
The researchers propose using a transformer-based architecture to perform the equalization task. Transformers are a type of neural network that have shown impressive results in various natural language processing and computer vision tasks. The key innovation in this work is the application of in-context learning, where the transformer model adapts its equalization strategy based on the current wireless environment.
The experimental evaluation compares the proposed approach to traditional MIMO equalization techniques, demonstrating significant performance improvements in terms of bit error rate and spectral efficiency. The results suggest that the transformer-based approach is better able to handle the dynamic interference patterns and channel conditions encountered in cell-free MIMO systems.
Critical Analysis
The paper presents a promising approach to improving wireless communications in scenarios with multiple users and antennas. The use of transformer models and in-context learning is a novel and interesting idea that could lead to more robust and adaptive equalization strategies.
However, the paper does not address some potential limitations and areas for further research. For example, the computational complexity of the transformer-based approach is not discussed, which could be a concern for real-time applications with tight latency requirements. Additionally, the performance of the proposed method in more realistic and complex wireless environments, such as those with mobility, non-line-of-sight propagation, or heterogeneous device capabilities, is not explored.
It would also be valuable to explore the trade-offs between using more samples versus more prompts for in-context learning in this application, as this could impact the practical deployment and scaling of the proposed approach.
Overall, the research presented in this paper represents an important step towards more effective and adaptive wireless communications, but further investigation is needed to fully understand the strengths, limitations, and real-world applicability of the proposed techniques.
Conclusion
This paper introduces a novel approach for cell-free multi-user MIMO equalization that leverages transformer models and in-context learning. The key idea is to use the adaptive capabilities of transformer-based architectures to improve the performance and robustness of the equalization process, particularly in challenging cell-free MIMO environments with distributed antennas and dynamic interference patterns.
The experimental results demonstrate the potential of this approach, showing significant improvements in bit error rate and spectral efficiency compared to traditional equalization techniques. While the paper does not address all the potential limitations and areas for further research, it represents an important contribution towards more effective and adaptive wireless communications solutions.
As 5G and future wireless networks continue to evolve, techniques like the one proposed in this paper could play a crucial role in enabling reliable, high-performance, and efficient data transmission for a wide range of applications, from high-speed internet to remote healthcare and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
Implicit In-context Learning
Zhuowei Li, Zihao Xu, Ligong Han, Yunhe Gao, Song Wen, Di Liu, Hao Wang, Dimitris N. Metaxas
0
0
In-context Learning (ICL) empowers large language models (LLMs) to adapt to unseen tasks during inference by prefixing a few demonstration examples prior to test queries. Despite its versatility, ICL incurs substantial computational and memory overheads compared to zero-shot learning and is susceptible to the selection and order of demonstration examples. In this work, we introduce Implicit In-context Learning (I2CL), an innovative paradigm that addresses the challenges associated with traditional ICL by absorbing demonstration examples within the activation space. I2CL first generates a condensed vector representation, namely a context vector, from the demonstration examples. It then integrates the context vector during inference by injecting a linear combination of the context vector and query activations into the model's residual streams. Empirical evaluation on nine real-world tasks across three model architectures demonstrates that I2CL achieves few-shot performance with zero-shot cost and exhibits robustness against the variation of demonstration examples. Furthermore, I2CL facilitates a novel representation of task-ids, enhancing task similarity detection and enabling effective transfer learning. We provide a comprehensive analysis of I2CL, offering deeper insights into its mechanisms and broader implications for ICL. The source code is available at: https://github.com/LzVv123456/I2CL.
5/24/2024
Many-Shot In-Context Learning
Rishabh Agarwal, Avi Singh, Lei M. Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D. Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, Hugo Larochelle
0
0
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
5/24/2024
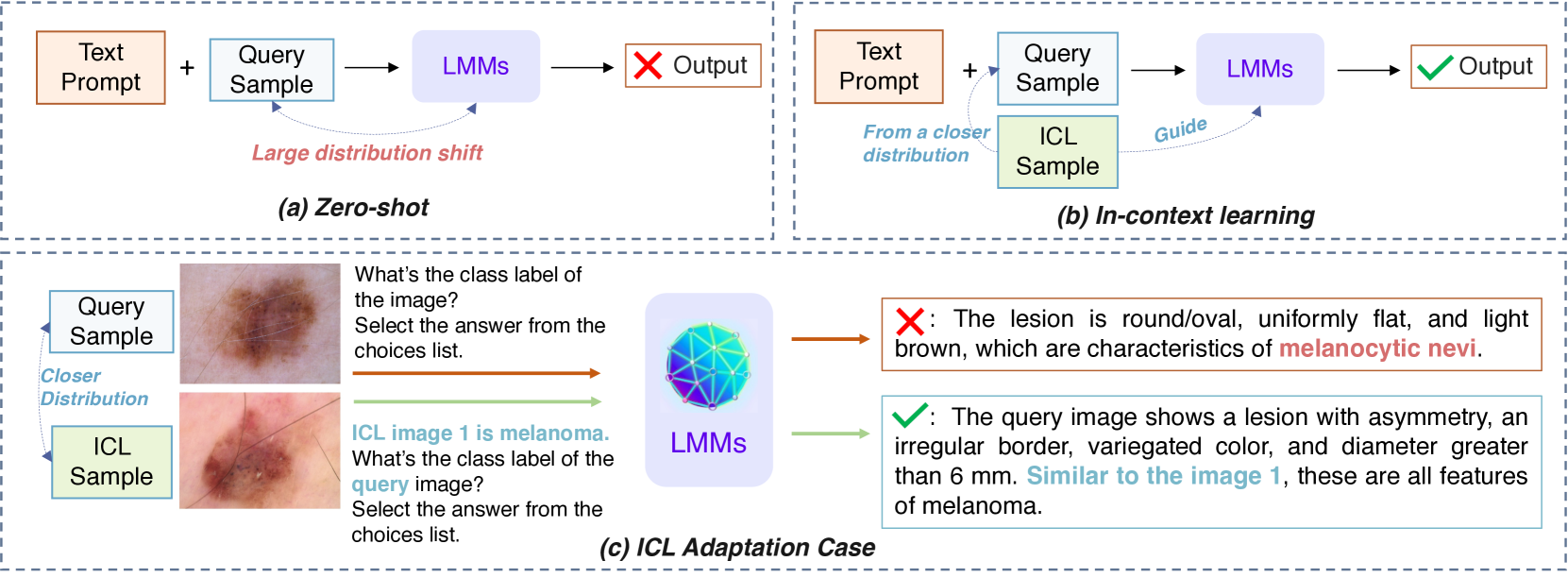
Adapting Large Multimodal Models to Distribution Shifts: The Role of In-Context Learning
Guanglin Zhou, Zhongyi Han, Shiming Chen, Biwei Huang, Liming Zhu, Salman Khan, Xin Gao, Lina Yao
0
0
Recent studies indicate that large multimodal models (LMMs) are highly robust against natural distribution shifts, often surpassing previous baselines. Despite this, domain-specific adaptation is still necessary, particularly in specialized areas like healthcare. Due to the impracticality of fine-tuning LMMs given their vast parameter space, this work investigates in-context learning (ICL) as an effective alternative for enhancing LMMs' adaptability. We find that the success of ICL heavily relies on the choice of demonstration, mirroring challenges seen in large language models but introducing unique complexities for LMMs facing distribution shifts. Our study addresses this by evaluating an unsupervised ICL method, TopKNearestPR, which selects in-context examples through a nearest example search based on feature similarity. We uncover that its effectiveness is limited by the deficiencies of pre-trained vision encoders under distribution shift scenarios. To address these challenges, we propose InvariantSelectPR, a novel method leveraging Class-conditioned Contrastive Invariance (CCI) for more robust demonstration selection. Specifically, CCI enhances pre-trained vision encoders by improving their discriminative capabilities across different classes and ensuring invariance to domain-specific variations. This enhancement allows the encoders to effectively identify and retrieve the most informative examples, which are then used to guide LMMs in adapting to new query samples under varying distributions. Our experiments show that InvariantSelectPR substantially improves the adaptability of LMMs, achieving significant performance gains on benchmark datasets, with a 34.2%$uparrow$ accuracy increase in 7-shot on Camelyon17 and 16.9%$uparrow$ increase in 7-shot on HAM10000 compared to the baseline zero-shot performance.
5/21/2024
💬
AIM: Let Any Multi-modal Large Language Models Embrace Efficient In-Context Learning
Jun Gao, Qian Qiao, Ziqiang Cao, Zili Wang, Wenjie Li
0
0
In-context learning (ICL) facilitates Large Language Models (LLMs) exhibiting emergent ability on downstream tasks without updating billions of parameters. However, in the area of multi-modal Large Language Models (MLLMs), two problems hinder the application of multi-modal ICL: (1) Most primary MLLMs are only trained on single-image datasets, making them unable to read multi-modal demonstrations. (2) With the demonstrations increasing, thousands of visual tokens highly challenge hardware and degrade ICL performance. During preliminary explorations, we discovered that the inner LLM tends to focus more on the linguistic modality within multi-modal demonstrations to generate responses. Therefore, we propose a general and light-weighted framework textbf{AIM} to tackle the mentioned problems through textbf{A}ggregating textbf{I}mage information of textbf{M}ultimodal demonstrations to the dense latent space of the corresponding linguistic part. Specifically, AIM first uses the frozen backbone MLLM to read each image-text demonstration and extracts the vector representations on top of the text. These vectors naturally fuse the information of the image-text pair, and AIM transforms them into fused virtual tokens acceptable for the inner LLM via a trainable projection layer. Ultimately, these fused tokens function as variants of multi-modal demonstrations, fed into the MLLM to direct its response to the current query as usual. Because these fused tokens stem from the textual component of the image-text pair, a multi-modal demonstration is nearly reduced to a pure textual demonstration, thus seamlessly applying to any MLLMs. With its de facto MLLM frozen, AIM is parameter-efficient and we train it on public multi-modal web corpora which have nothing to do with downstream test tasks.
7/2/2024