Centrality Estimators for Probability Density Functions

0

Sign in to get full access
Overview
- This paper introduces two new measures for quantifying the complexity of probability distributions: the Hölder measure and the Lehmer measure.
- The Hölder measure captures the "roughness" or irregularity of a distribution, while the Lehmer measure captures its "unevenness" or concentration.
- The authors compare these new measures to the commonly used Kullback-Leibler (KL) divergence and demonstrate their advantages in certain situations.
Plain English Explanation
The paper explores new ways to quantify the complexity of probability distributions, which are mathematical representations of how likely different outcomes are. The researchers introduce two new measures: the Hölder measure and the Lehmer measure.
The Hölder measure captures how "rough" or irregular a distribution is. Imagine a distribution that jumps up and down dramatically - this would have a high Hölder measure. In contrast, a smooth, gradual distribution would have a low Hölder measure.
The Lehmer measure, on the other hand, captures how "uneven" or concentrated a distribution is. A distribution with most of its probability concentrated in a small region would have a high Lehmer measure, while a more evenly spread-out distribution would have a low Lehmer measure.
These new measures are compared to the commonly used Kullback-Leibler (KL) divergence, which is a way of quantifying the difference between two probability distributions. The authors show that the Hölder and Lehmer measures can provide additional insights that the KL divergence doesn't capture.
Technical Explanation
The paper introduces two new complexity measures for probability distributions: the Hölder measure and the Lehmer measure.
The Hölder measure is defined as the supremum of the ratio of the absolute difference in probabilities between two points and the distance between those points, raised to a power α. This captures the "roughness" or irregularity of the distribution.
The Lehmer measure is defined as the ratio of the sum of the probabilities raised to some power p and the sum of the probabilities. This captures the "unevenness" or concentration of the distribution.
The authors compare these new measures to the commonly used Kullback-Leibler (KL) divergence, which quantifies the difference between two probability distributions. They show that the Hölder and Lehmer measures can provide additional insights that the KL divergence does not capture.
The paper also provides theoretical results on the properties of the Hölder and Lehmer measures, as well as their connections to other complexity measures like the Fisher information matrix and the generalized chi-square distribution.
Critical Analysis
The paper introduces two novel measures for quantifying the complexity of probability distributions, which can provide additional insights beyond the commonly used Kullback-Leibler divergence. The authors demonstrate the theoretical properties of these measures and their connections to other complexity measures, which is a valuable contribution to the field.
One potential limitation of the research is that the paper does not provide extensive empirical validation of the usefulness of the Hölder and Lehmer measures in practical applications. While the theoretical analysis is strong, more evidence on how these measures perform in real-world scenarios would strengthen the case for their adoption.
Additionally, the paper does not discuss potential pitfalls or caveats in the use of these measures. For example, the choice of the parameters α and p in the definitions of the Hölder and Lehmer measures, respectively, could have a significant impact on the results, and the paper does not provide guidance on how to select these parameters.
Overall, the paper presents an interesting and potentially useful approach to quantifying the complexity of probability distributions, but further research may be needed to fully understand the practical implications and limitations of these new measures.
Conclusion
This paper introduces two new measures, the Hölder measure and the Lehmer measure, for quantifying the complexity of probability distributions. These measures capture different aspects of complexity - the Hölder measure focusing on the "roughness" or irregularity of a distribution, and the Lehmer measure focusing on its "unevenness" or concentration.
The authors demonstrate the theoretical properties of these new measures and compare them to the commonly used Kullback-Leibler divergence, showing that they can provide additional insights. This work contributes to the ongoing effort to develop better tools for understanding and analyzing complex probability distributions, which have applications in areas like machine learning, information theory, and statistical physics.
While the paper provides a strong theoretical foundation, more empirical validation and exploration of potential limitations would be valuable next steps to fully assess the usefulness of the Hölder and Lehmer measures in practical settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Centrality Estimators for Probability Density Functions
Djemel Ziou
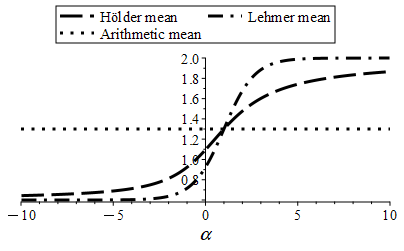
In this report, we explore the data selection leading to a family of estimators maximizing a centrality. The family allows a nice properties leading to accurate and robust probability density function fitting according to some criteria we define. We establish a link between the centrality estimator and the maximum likelihood, showing that the latter is a particular case. Therefore, a new probability interpretation of Fisher maximum likelihood is provided. We will introduce and study two specific centralities that we have named Holder and Lehmer estimators. A numerical simulation is provided showing the effectiveness of the proposed families of estimators opening the door to development of new concepts and algorithms in machine learning, data mining, statistics, and data analysis.
Read more4/10/2024
0
Deriving Lehmer and Holder means as maximum weighted likelihood estimates for the multivariate exponential family
Djemel Ziou, Issam Fakir
The links between the mean families of Lehmer and Holder and the weighted maximum likelihood estimator have recently been established in the case of a regular univariate exponential family. In this article, we will extend the outcomes obtained to the multivariate case. This extension provides a probabilistic interpretation of these families of means and could therefore broaden their uses in various applications.
Read more5/3/2024

0
A Density Ratio Super Learner
Wencheng Wu, David Benkeser
The estimation of the ratio of two density probability functions is of great interest in many statistics fields, including causal inference. In this study, we develop an ensemble estimator of density ratios with a novel loss function based on super learning. We show that this novel loss function is qualified for building super learners. Two simulations corresponding to mediation analysis and longitudinal modified treatment policy in causal inference, where density ratios are nuisance parameters, are conducted to show our density ratio super learner's performance empirically.
Read more8/12/2024
0
Binary Losses for Density Ratio Estimation
Werner Zellinger
Estimating the ratio of two probability densities from finitely many observations of the densities, is a central problem in machine learning and statistics. A large class of methods constructs estimators from binary classifiers which distinguish observations from the two densities. However, the error of these constructions depends on the choice of the binary loss function, raising the question of which loss function to choose based on desired error properties. In this work, we start from prescribed error measures in a class of Bregman divergences and characterize all loss functions that lead to density ratio estimators with a small error. Our characterization provides a simple recipe for constructing loss functions with certain properties, such as loss functions that prioritize an accurate estimation of large values. This contrasts with classical loss functions, such as the logistic loss or boosting loss, which prioritize accurate estimation of small values. We provide numerical illustrations with kernel methods and test their performance in applications of parameter selection for deep domain adaptation.
Read more7/2/2024