On Centralized Critics in Multi-Agent Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- This is a technical paper discussing issues with submitting a paper to the Journal of Artificial Intelligence Research (JAIR).
- The paper covers three main topics: simplification, history-based gradients, and state-based gradients.
- It provides insights and analysis on these technical aspects of machine learning research.
Plain English Explanation
The paper examines some challenges that can come up when submitting research to academic journals like JAIR. One issue is simplification - the authors discuss how to effectively simplify complex technical concepts for a general audience. They also look at the tradeoffs between using history-based gradients versus state-based gradients in machine learning models, and how to properly define these gradient types.
The goal is to help researchers navigate the process of getting their work published in top-tier AI journals. By addressing common problems that can arise, the paper aims to provide guidance and best practices for successfully communicating technical machine learning research.
Technical Explanation
The paper first discusses the challenge of Simplification. When submitting to academic journals, researchers must explain their technical approaches in a way that is understandable to a broad audience, not just experts in the field. The authors explore strategies for effectively simplifying complex ideas without losing important nuances.
Next, the paper examines the question of Which History-Based Gradient to Use. In reinforcement learning, there are different ways to calculate the gradient based on an agent's past actions and observations. The authors analyze the tradeoffs between using Monte Carlo, TD, and other history-based gradient methods.
Finally, the paper tackles the problem of How to Define State-Based Gradient. State-based gradients offer an alternative to history-based approaches, but there are challenges in properly defining and applying this technique. The authors discuss potential solutions and their implications.
Critical Analysis
The paper acknowledges some limitations in its scope, noting that it focuses on three specific technical issues rather than providing a comprehensive guide to JAIR submissions. While the analysis is thorough, there may be other common challenges that are not addressed.
Additionally, the paper does not delve into potential biases or ethical concerns that can arise in machine learning research. As this field continues to evolve, it will be important for future work to consider the societal impact of the techniques being developed.
Conclusion
This technical paper offers valuable insights for researchers seeking to publish their work in leading AI journals like JAIR. By tackling common issues around simplification, gradient calculations, and state-based methods, the authors provide a roadmap for effectively communicating complex machine learning concepts.
While the analysis is focused on the specific context of JAIR submissions, the principles discussed have broader applicability. Researchers in various fields can benefit from learning strategies for making their technical work more accessible and impactful.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
On Centralized Critics in Multi-Agent Reinforcement Learning
Xueguang Lyu, Andrea Baisero, Yuchen Xiao, Brett Daley, Christopher Amato
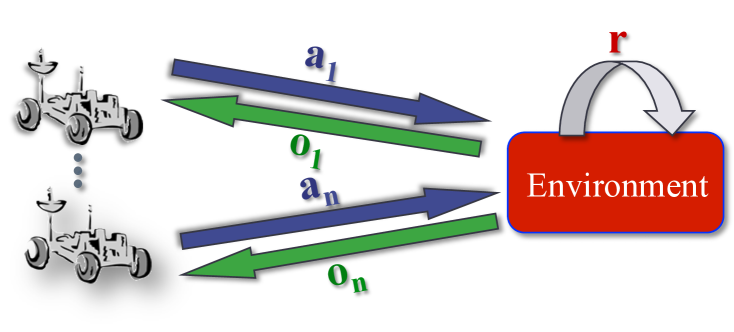
Centralized Training for Decentralized Execution where agents are trained offline in a centralized fashion and execute online in a decentralized manner, has become a popular approach in Multi-Agent Reinforcement Learning (MARL). In particular, it has become popular to develop actor-critic methods that train decentralized actors with a centralized critic where the centralized critic is allowed access global information of the entire system, including the true system state. Such centralized critics are possible given offline information and are not used for online execution. While these methods perform well in a number of domains and have become a de facto standard in MARL, using a centralized critic in this context has yet to be sufficiently analyzed theoretically or empirically. In this paper, we therefore formally analyze centralized and decentralized critic approaches, and analyze the effect of using state-based critics in partially observable environments. We derive theories contrary to the common intuition: critic centralization is not strictly beneficial, and using state values can be harmful. We further prove that, in particular, state-based critics can introduce unexpected bias and variance compared to history-based critics. Finally, we demonstrate how the theory applies in practice by comparing different forms of critics on a wide range of common multi-agent benchmarks. The experiments show practical issues such as the difficulty of representation learning with partial observability, which highlights why the theoretical problems are often overlooked in the literature.
Read more8/28/2024

0
Multi-agent Off-policy Actor-Critic Reinforcement Learning for Partially Observable Environments
Ainur Zhaikhan, Ali H. Sayed
This study proposes the use of a social learning method to estimate a global state within a multi-agent off-policy actor-critic algorithm for reinforcement learning (RL) operating in a partially observable environment. We assume that the network of agents operates in a fully-decentralized manner, possessing the capability to exchange variables with their immediate neighbors. The proposed design methodology is supported by an analysis demonstrating that the difference between final outcomes, obtained when the global state is fully observed versus estimated through the social learning method, is $varepsilon$-bounded when an appropriate number of iterations of social learning updates are implemented. Unlike many existing dec-POMDP-based RL approaches, the proposed algorithm is suitable for model-free multi-agent reinforcement learning as it does not require knowledge of a transition model. Furthermore, experimental results illustrate the efficacy of the algorithm and demonstrate its superiority over the current state-of-the-art methods.
Read more7/9/2024
0
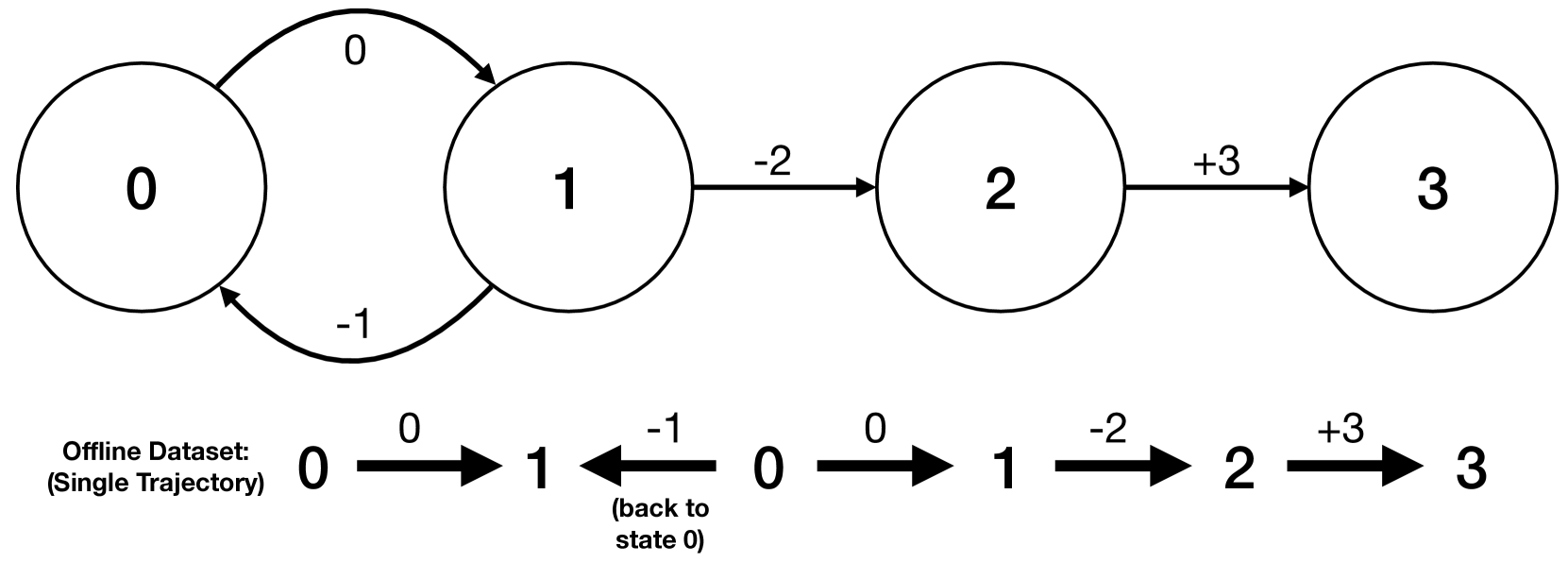
Efficient Offline Reinforcement Learning: The Critic is Critical
Adam Jelley, Trevor McInroe, Sam Devlin, Amos Storkey
Recent work has demonstrated both benefits and limitations from using supervised approaches (without temporal-difference learning) for offline reinforcement learning. While off-policy reinforcement learning provides a promising approach for improving performance beyond supervised approaches, we observe that training is often inefficient and unstable due to temporal difference bootstrapping. In this paper we propose a best-of-both approach by first learning the behavior policy and critic with supervised learning, before improving with off-policy reinforcement learning. Specifically, we demonstrate improved efficiency by pre-training with a supervised Monte-Carlo value-error, making use of commonly neglected downstream information from the provided offline trajectories. We find that we are able to more than halve the training time of the considered offline algorithms on standard benchmarks, and surprisingly also achieve greater stability. We further build on the importance of having consistent policy and value functions to propose novel hybrid algorithms, TD3+BC+CQL and EDAC+BC, that regularize both the actor and the critic towards the behavior policy. This helps to more reliably improve on the behavior policy when learning from limited human demonstrations. Code is available at https://github.com/AdamJelley/EfficientOfflineRL
Read more6/21/2024
0
An Introduction to Centralized Training for Decentralized Execution in Cooperative Multi-Agent Reinforcement Learning
Christopher Amato
Multi-agent reinforcement learning (MARL) has exploded in popularity in recent years. Many approaches have been developed but they can be divided into three main types: centralized training and execution (CTE), centralized training for decentralized execution (CTDE), and Decentralized training and execution (DTE). CTDE methods are the most common as they can use centralized information during training but execute in a decentralized manner -- using only information available to that agent during execution. CTDE is the only paradigm that requires a separate training phase where any available information (e.g., other agent policies, underlying states) can be used. As a result, they can be more scalable than CTE methods, do not require communication during execution, and can often perform well. CTDE fits most naturally with the cooperative case, but can be potentially applied in competitive or mixed settings depending on what information is assumed to be observed. This text is an introduction to CTDE in cooperative MARL. It is meant to explain the setting, basic concepts, and common methods. It does not cover all work in CTDE MARL as the subarea is quite extensive. I have included work that I believe is important for understanding the main concepts in the subarea and apologize to those that I have omitted.
Read more9/6/2024