CERT-ED: Certifiably Robust Text Classification for Edit Distance

0

Sign in to get full access
Overview
- The paper proposes a method called CERT-ED for achieving certifiable robustness of text classification models against edit distance-based adversarial attacks.
- Edit distance is a measure of the similarity between two strings, and adversarial attacks can exploit this to generate small perturbations that fool classification models.
- CERT-ED provides provable guarantees that a model's predictions will be unchanged under a specified edit distance budget.
Plain English Explanation
CERT-ED is a way to make text classification models more robust - that is, less vulnerable to small changes in the input text that could cause the model to make incorrect predictions. This is important because sometimes attackers can make tiny tweaks to text that trick the model, even though the changes seem minor to a human.
The key idea behind CERT-ED is to use the concept of "edit distance" to quantify how different two pieces of text are. Edit distance measures things like how many words or characters need to be added, removed, or changed to get from one text to another. CERT-ED ensures the model's predictions won't change as long as the edit distance between the original text and any modified version stays within a specified budget.
This provides a strong certification that the model is robust against a certain level of text perturbation. Even if an attacker tries to subtly alter the input, the model will still give the same output as long as the changes don't exceed the allowed edit distance.
Technical Explanation
CERT-ED builds on previous work on achieving certified robustness for text classification, but specifically targets edit distance-based adversarial attacks. The key innovation is a way to efficiently compute tight edit distance-based robustness certificates for neural network-based text classifiers.
The approach involves training the model with a novel regularization term that encourages robustness to edit distance perturbations. During inference, CERT-ED can then provide provable guarantees about the model's predictions remaining unchanged under a specified edit distance budget. This is achieved by solving a constrained optimization problem to find the maximum edit distance that still preserves the model's original prediction.
Experiments demonstrate that CERT-ED achieves state-of-the-art certified robustness against edit distance attacks across several standard text classification benchmarks, outperforming previous approaches. The method is also computationally efficient, making it practical for real-world deployment.
Critical Analysis
The authors thoroughly explore the limitations and potential issues with CERT-ED. For example, they note that the method assumes a known edit distance budget, and that the robustness guarantees only hold for that specific budget. There is also a tradeoff between the level of certified robustness and model accuracy, which the authors investigate.
Additionally, the paper does not address the potential for cascading edit distance-based attacks, where multiple small changes are combined. It's unclear how well CERT-ED would perform in such scenarios.
Overall, the paper presents a well-designed and comprehensive approach to certified robustness for text classification, but there are still opportunities for further research to address the remaining limitations.
Conclusion
CERT-ED is a significant advancement in the field of certifiable robustness for text classification models. By providing provable guarantees against edit distance-based adversarial attacks, it represents an important step towards building more reliable and trustworthy AI systems for critical applications. While the method has some limitations, the insights and techniques presented in this paper will likely inspire further progress in this important area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CERT-ED: Certifiably Robust Text Classification for Edit Distance
Zhuoqun Huang, Neil G Marchant, Olga Ohrimenko, Benjamin I. P. Rubinstein
With the growing integration of AI in daily life, ensuring the robustness of systems to inference-time attacks is crucial. Among the approaches for certifying robustness to such adversarial examples, randomized smoothing has emerged as highly promising due to its nature as a wrapper around arbitrary black-box models. Previous work on randomized smoothing in natural language processing has primarily focused on specific subsets of edit distance operations, such as synonym substitution or word insertion, without exploring the certification of all edit operations. In this paper, we adapt Randomized Deletion (Huang et al., 2023) and propose, CERTified Edit Distance defense (CERT-ED) for natural language classification. Through comprehensive experiments, we demonstrate that CERT-ED outperforms the existing Hamming distance method RanMASK (Zeng et al., 2023) in 4 out of 5 datasets in terms of both accuracy and the cardinality of the certificate. By covering various threat models, including 5 direct and 5 transfer attacks, our method improves empirical robustness in 38 out of 50 settings.
Read more8/2/2024
✅
0
Text-CRS: A Generalized Certified Robustness Framework against Textual Adversarial Attacks
Xinyu Zhang, Hanbin Hong, Yuan Hong, Peng Huang, Binghui Wang, Zhongjie Ba, Kui Ren
The language models, especially the basic text classification models, have been shown to be susceptible to textual adversarial attacks such as synonym substitution and word insertion attacks. To defend against such attacks, a growing body of research has been devoted to improving the model robustness. However, providing provable robustness guarantees instead of empirical robustness is still widely unexplored. In this paper, we propose Text-CRS, a generalized certified robustness framework for natural language processing (NLP) based on randomized smoothing. To our best knowledge, existing certified schemes for NLP can only certify the robustness against $ell_0$ perturbations in synonym substitution attacks. Representing each word-level adversarial operation (i.e., synonym substitution, word reordering, insertion, and deletion) as a combination of permutation and embedding transformation, we propose novel smoothing theorems to derive robustness bounds in both permutation and embedding space against such adversarial operations. To further improve certified accuracy and radius, we consider the numerical relationships between discrete words and select proper noise distributions for the randomized smoothing. Finally, we conduct substantial experiments on multiple language models and datasets. Text-CRS can address all four different word-level adversarial operations and achieve a significant accuracy improvement. We also provide the first benchmark on certified accuracy and radius of four word-level operations, besides outperforming the state-of-the-art certification against synonym substitution attacks.
Read more6/12/2024
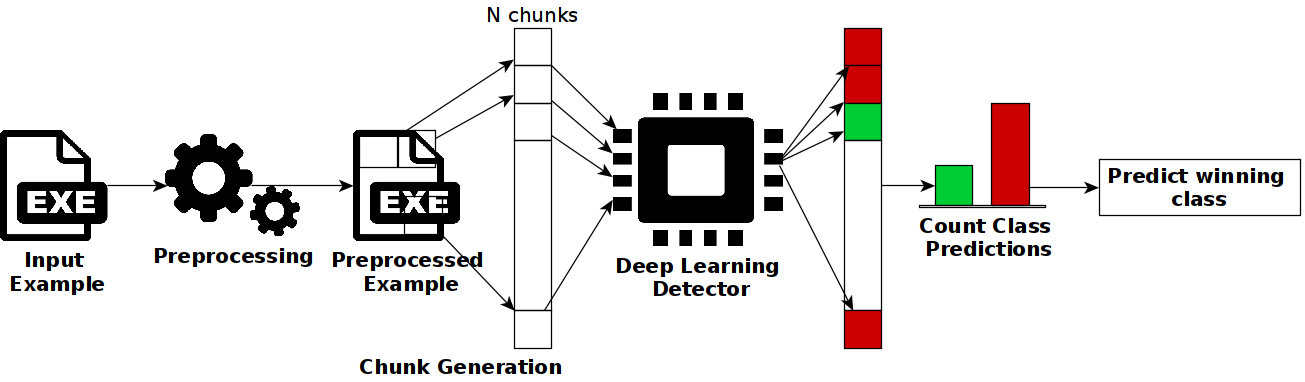
0
Certified Adversarial Robustness of Machine Learning-based Malware Detectors via (De)Randomized Smoothing
Daniel Gibert, Luca Demetrio, Giulio Zizzo, Quan Le, Jordi Planes, Battista Biggio
Deep learning-based malware detection systems are vulnerable to adversarial EXEmples - carefully-crafted malicious programs that evade detection with minimal perturbation. As such, the community is dedicating effort to develop mechanisms to defend against adversarial EXEmples. However, current randomized smoothing-based defenses are still vulnerable to attacks that inject blocks of adversarial content. In this paper, we introduce a certifiable defense against patch attacks that guarantees, for a given executable and an adversarial patch size, no adversarial EXEmple exist. Our method is inspired by (de)randomized smoothing which provides deterministic robustness certificates. During training, a base classifier is trained using subsets of continguous bytes. At inference time, our defense splits the executable into non-overlapping chunks, classifies each chunk independently, and computes the final prediction through majority voting to minimize the influence of injected content. Furthermore, we introduce a preprocessing step that fixes the size of the sections and headers to a multiple of the chunk size. As a consequence, the injected content is confined to an integer number of chunks without tampering the other chunks containing the real bytes of the input examples, allowing us to extend our certified robustness guarantees to content insertion attacks. We perform an extensive ablation study, by comparing our defense with randomized smoothing-based defenses against a plethora of content manipulation attacks and neural network architectures. Results show that our method exhibits unmatched robustness against strong content-insertion attacks, outperforming randomized smoothing-based defenses in the literature.
Read more5/2/2024

0
Provably Robust Cost-Sensitive Learning via Randomized Smoothing
Yuan Xin, Michael Backes, Xiao Zhang
We study the problem of robust learning against adversarial perturbations under cost-sensitive scenarios, where the potential harm of different types of misclassifications is encoded in a cost matrix. Existing approaches are either empirical and cannot certify robustness or suffer from inherent scalability issues. In this work, we investigate whether randomized smoothing, a scalable framework for robustness certification, can be leveraged to certify and train for cost-sensitive robustness. Built upon the notion of cost-sensitive certified radius, we first illustrate how to adapt the standard certification algorithm of randomized smoothing to produce tight robustness certificates for any binary cost matrix, and then develop a robust training method to promote certified cost-sensitive robustness while maintaining the model's overall accuracy. Through extensive experiments on image benchmarks, we demonstrate the superiority of our proposed certification algorithm and training method under various cost-sensitive scenarios. Our implementation is available as open source code at: https://github.com/TrustMLRG/CS-RS.
Read more5/31/2024