Text-CRS: A Generalized Certified Robustness Framework against Textual Adversarial Attacks

0
✅
Sign in to get full access
Overview
- The paper proposes a new framework called Text-CRS to provide certified robustness for natural language processing (NLP) models against various adversarial attacks.
- Existing certified robustness schemes for NLP can only handle synonym substitution attacks, but Text-CRS can defend against a wider range of attacks, including word reordering, insertion, and deletion.
- Text-CRS represents adversarial operations as a combination of permutation and embedding transformations, and uses randomized smoothing to derive robustness bounds in both spaces.
- The paper also explores numerical relationships between discrete words to select proper noise distributions and further improve certified accuracy and radius.
- Experiments show Text-CRS can significantly improve certified accuracy compared to prior work, especially against the wider range of adversarial attacks it can handle.
Plain English Explanation
Machine learning models, especially basic text classification models, can be tricked by small changes to the input text. For example, replacing a word with a synonym or adding extra words can cause the model to make mistakes. Researchers have been working on ways to make these models more robust and resistant to such adversarial attacks.
This paper proposes a new approach called Text-CRS that can provide a mathematical guarantee of robustness, rather than just empirical robustness. Text-CRS represents different types of adversarial attacks, like replacing words with synonyms or rearranging the order of words, as a combination of changes to the text's structure (permutations) and changes to the meaning of individual words (embeddings).
By using a statistical technique called randomized smoothing, Text-CRS can then calculate bounds on how much the model's output can change due to these adversarial modifications. This allows the model to be "certified" as robust up to a certain level of attack.
The paper also explores ways to further improve the robustness, such as carefully selecting the type of random noise added during smoothing to better match the discrete nature of language. Experiments show Text-CRS can significantly outperform previous approaches, especially for the wider range of attacks it can handle compared to prior work.
Technical Explanation
The paper proposes a generalized certified robustness framework for NLP called Text-CRS, based on the randomized smoothing technique. Existing certified robustness schemes for NLP can only handle ℓ₀ perturbations in synonym substitution attacks, but Text-CRS can defend against a wider range of word-level adversarial operations including reordering, insertion, and deletion.
The key idea is to represent each word-level adversarial operation as a combination of permutation and embedding transformation. The paper then develops novel smoothing theorems to derive robustness bounds in both the permutation and embedding space against these adversarial operations.
To further improve certified accuracy and radius, the authors consider the numerical relationships between discrete words and select proper noise distributions for the randomized smoothing process. Extensive experiments are conducted on multiple language models and datasets, showing that Text-CRS can significantly outperform prior work in certified accuracy, especially against the wider range of attacks it can handle.
Critical Analysis
The paper provides a solid theoretical framework and empirical evaluation of the Text-CRS approach for certified robustness in NLP. However, there are a few potential limitations and areas for further research:
-
The paper focuses on word-level adversarial attacks, but real-world attacks may involve more complex, semantics-preserving transformations at the sentence or paragraph level. Extending the certified robustness guarantees to these higher-level attacks remains an open challenge.
-
The experiments are conducted on standard text classification benchmarks, but the effectiveness of Text-CRS may vary for more complex NLP tasks like question answering or language generation. Further evaluation on a broader range of real-world NLP applications would be valuable.
-
The paper does not provide a comparison to certified adversarial robustness approaches developed for other domains like computer vision. Understanding the similarities and differences in the underlying techniques could lead to cross-pollination of ideas.
-
While the paper demonstrates significant improvements over prior work, the overall certified accuracy levels are still relatively low, especially for the more complex adversarial operations. Continued research is needed to further improve the tightness of the robustness bounds.
Overall, the Text-CRS framework represents an important step towards provable robustness in NLP, but there remain many interesting challenges and avenues for future work in this area.
Conclusion
This paper introduces Text-CRS, a novel certified robustness framework for natural language processing models. Unlike previous approaches that could only handle synonym substitution attacks, Text-CRS can provide provable guarantees against a wider range of adversarial operations, including word reordering, insertion, and deletion.
By representing these adversarial attacks as a combination of permutation and embedding transformations, and using randomized smoothing techniques, Text-CRS can derive robustness bounds that ensure the model's output will not change significantly under attack. The paper also explores ways to optimize the noise distributions used in the smoothing process to further improve the certified accuracy and radius.
Experimental results show that Text-CRS significantly outperforms prior work, especially on the broader set of adversarial attacks it can handle. This research represents an important step towards building more trustworthy and reliable NLP systems that can withstand malicious attempts to manipulate their behavior. While challenges remain, the techniques developed in this paper pave the way for continued advances in certified robustness for language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
0
Text-CRS: A Generalized Certified Robustness Framework against Textual Adversarial Attacks
Xinyu Zhang, Hanbin Hong, Yuan Hong, Peng Huang, Binghui Wang, Zhongjie Ba, Kui Ren
The language models, especially the basic text classification models, have been shown to be susceptible to textual adversarial attacks such as synonym substitution and word insertion attacks. To defend against such attacks, a growing body of research has been devoted to improving the model robustness. However, providing provable robustness guarantees instead of empirical robustness is still widely unexplored. In this paper, we propose Text-CRS, a generalized certified robustness framework for natural language processing (NLP) based on randomized smoothing. To our best knowledge, existing certified schemes for NLP can only certify the robustness against $ell_0$ perturbations in synonym substitution attacks. Representing each word-level adversarial operation (i.e., synonym substitution, word reordering, insertion, and deletion) as a combination of permutation and embedding transformation, we propose novel smoothing theorems to derive robustness bounds in both permutation and embedding space against such adversarial operations. To further improve certified accuracy and radius, we consider the numerical relationships between discrete words and select proper noise distributions for the randomized smoothing. Finally, we conduct substantial experiments on multiple language models and datasets. Text-CRS can address all four different word-level adversarial operations and achieve a significant accuracy improvement. We also provide the first benchmark on certified accuracy and radius of four word-level operations, besides outperforming the state-of-the-art certification against synonym substitution attacks.
Read more6/12/2024
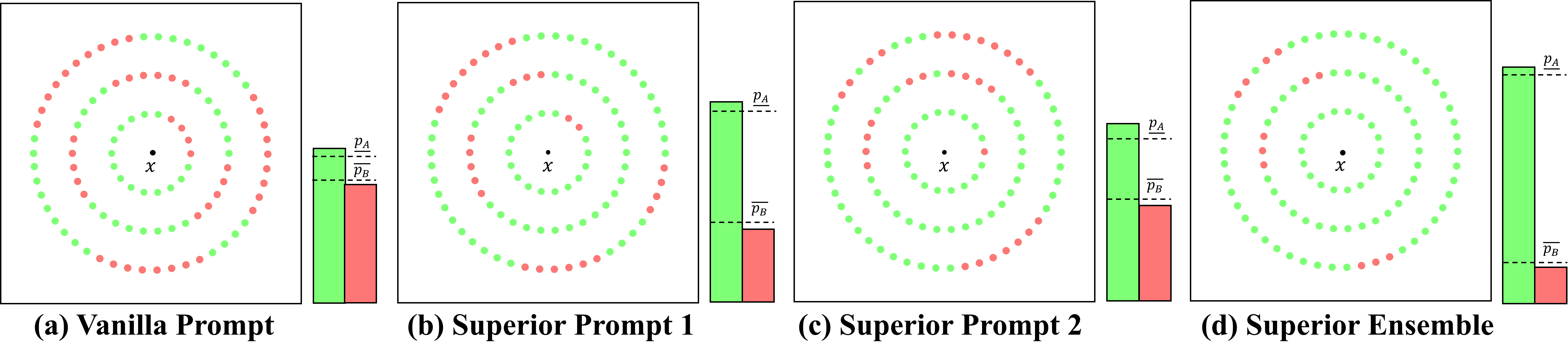
0
CR-UTP: Certified Robustness against Universal Text Perturbations
Qian Lou, Xin Liang, Jiaqi Xue, Yancheng Zhang, Rui Xie, Mengxin Zheng
It is imperative to ensure the stability of every prediction made by a language model; that is, a language's prediction should remain consistent despite minor input variations, like word substitutions. In this paper, we investigate the problem of certifying a language model's robustness against Universal Text Perturbations (UTPs), which have been widely used in universal adversarial attacks and backdoor attacks. Existing certified robustness based on random smoothing has shown considerable promise in certifying the input-specific text perturbations (ISTPs), operating under the assumption that any random alteration of a sample's clean or adversarial words would negate the impact of sample-wise perturbations. However, with UTPs, masking only the adversarial words can eliminate the attack. A naive method is to simply increase the masking ratio and the likelihood of masking attack tokens, but it leads to a significant reduction in both certified accuracy and the certified radius due to input corruption by extensive masking. To solve this challenge, we introduce a novel approach, the superior prompt search method, designed to identify a superior prompt that maintains higher certified accuracy under extensive masking. Additionally, we theoretically motivate why ensembles are a particularly suitable choice as base prompts for random smoothing. The method is denoted by superior prompt ensembling technique. We also empirically confirm this technique, obtaining state-of-the-art results in multiple settings. These methodologies, for the first time, enable high certified accuracy against both UTPs and ISTPs. The source code of CR-UTP is available at url {https://github.com/UCFML-Research/CR-UTP}.
Read more6/6/2024

0
CERT-ED: Certifiably Robust Text Classification for Edit Distance
Zhuoqun Huang, Neil G Marchant, Olga Ohrimenko, Benjamin I. P. Rubinstein
With the growing integration of AI in daily life, ensuring the robustness of systems to inference-time attacks is crucial. Among the approaches for certifying robustness to such adversarial examples, randomized smoothing has emerged as highly promising due to its nature as a wrapper around arbitrary black-box models. Previous work on randomized smoothing in natural language processing has primarily focused on specific subsets of edit distance operations, such as synonym substitution or word insertion, without exploring the certification of all edit operations. In this paper, we adapt Randomized Deletion (Huang et al., 2023) and propose, CERTified Edit Distance defense (CERT-ED) for natural language classification. Through comprehensive experiments, we demonstrate that CERT-ED outperforms the existing Hamming distance method RanMASK (Zeng et al., 2023) in 4 out of 5 datasets in terms of both accuracy and the cardinality of the certificate. By covering various threat models, including 5 direct and 5 transfer attacks, our method improves empirical robustness in 38 out of 50 settings.
Read more8/2/2024
🔮
0
Semantic Stealth: Adversarial Text Attacks on NLP Using Several Methods
Roopkatha Dey, Aivy Debnath, Sayak Kumar Dutta, Kaustav Ghosh, Arijit Mitra, Arghya Roy Chowdhury, Jaydip Sen
In various real-world applications such as machine translation, sentiment analysis, and question answering, a pivotal role is played by NLP models, facilitating efficient communication and decision-making processes in domains ranging from healthcare to finance. However, a significant challenge is posed to the robustness of these natural language processing models by text adversarial attacks. These attacks involve the deliberate manipulation of input text to mislead the predictions of the model while maintaining human interpretability. Despite the remarkable performance achieved by state-of-the-art models like BERT in various natural language processing tasks, they are found to remain vulnerable to adversarial perturbations in the input text. In addressing the vulnerability of text classifiers to adversarial attacks, three distinct attack mechanisms are explored in this paper using the victim model BERT: BERT-on-BERT attack, PWWS attack, and Fraud Bargain's Attack (FBA). Leveraging the IMDB, AG News, and SST2 datasets, a thorough comparative analysis is conducted to assess the effectiveness of these attacks on the BERT classifier model. It is revealed by the analysis that PWWS emerges as the most potent adversary, consistently outperforming other methods across multiple evaluation scenarios, thereby emphasizing its efficacy in generating adversarial examples for text classification. Through comprehensive experimentation, the performance of these attacks is assessed and the findings indicate that the PWWS attack outperforms others, demonstrating lower runtime, higher accuracy, and favorable semantic similarity scores. The key insight of this paper lies in the assessment of the relative performances of three prevalent state-of-the-art attack mechanisms.
Read more4/9/2024