CFBench: A Comprehensive Constraints-Following Benchmark for LLMs

0

Sign in to get full access
Overview
- Introduces CFBench, a comprehensive benchmark for evaluating large language models' (LLMs) ability to follow complex constraints.
- Evaluates LLM performance on tasks that require following multiple, potentially conflicting instructions.
- Aims to provide a more realistic and comprehensive assessment of LLM capabilities compared to existing benchmarks.
Plain English Explanation
The paper presents CFBench, a new benchmark for testing the abilities of large language models (LLMs) to follow complex instructions and constraints.
Unlike many existing benchmarks that focus on simple, isolated tasks, CFBench evaluates how well LLMs can handle more realistic scenarios where they need to balance multiple, potentially conflicting instructions. The researchers designed a wide range of tasks that require the models to follow a combination of textual, numerical, and logical constraints.
By using this more comprehensive approach, the authors hope to provide a better assessment of the true capabilities of LLMs, beyond just their performance on narrow, specialized tests. The goal is to identify areas where current models excel or struggle, and ultimately drive progress towards building AI systems that can reliably follow complex, real-world instructions.
Technical Explanation
The paper introduces CFBench, a new benchmark for evaluating large language models' (LLMs) ability to follow complex constraints. Unlike existing benchmarks that focus on simple, isolated tasks, CFBench assesses how well LLMs can handle more realistic scenarios that require balancing multiple, potentially conflicting instructions.
The CFBench dataset includes a wide range of tasks that involve following textual, numerical, and logical constraints simultaneously. For example, a task might require the model to generate a short story that includes specific character names, locations, and plot elements, while also adhering to length and sentiment constraints.
The researchers argue that this more comprehensive approach provides a better assessment of LLM capabilities compared to narrow, specialized tests. By identifying areas where current models excel or struggle, the benchmark aims to drive progress towards building AI systems that can reliably follow complex, real-world instructions.
Critical Analysis
The paper makes a compelling case for the need to move beyond simplistic benchmarks and towards more realistic and nuanced assessments of LLM capabilities. The authors acknowledge that CFBench is not a perfect representation of the full complexity of real-world instruction following, but it represents a significant step forward in this direction.
One potential limitation of the benchmark is the reliance on pre-defined constraints and task formulations. While this allows for a more controlled and standardized evaluation, it may not fully capture the open-ended nature of many real-world challenges. Additionally, the paper does not provide details on the diversity of the dataset in terms of topics, styles, and cultural contexts, which could impact the generalizability of the results.
Further research could explore ways to make the benchmark more dynamic and adaptable, perhaps by incorporating user feedback or other mechanisms for generating novel, context-sensitive tasks. Additionally, the authors could consider ways to better understand the specific capabilities and limitations of different LLM architectures and training approaches within the CFBench framework.
Conclusion
The CFBench benchmark represents an important step forward in the evaluation of large language models' real-world capabilities. By focusing on the ability to follow complex, multi-faceted instructions, the researchers aim to provide a more realistic assessment of LLM performance and drive progress towards more reliable and capable AI systems.
While the benchmark has room for further refinement and expansion, it serves as a valuable tool for researchers and developers working to advance the state of the art in language understanding and task completion. By identifying the strengths and weaknesses of current models, CFBench can help guide the development of more robust and versatile AI assistants that can navigate the nuances of complex, real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CFBench: A Comprehensive Constraints-Following Benchmark for LLMs
Tao Zhang, Yanjun Shen, Wenjing Luo, Yan Zhang, Hao Liang, Tao Zhang, Fan Yang, Mingan Lin, Yujing Qiao, Weipeng Chen, Bin Cui, Wentao Zhang, Zenan Zhou
The adeptness of Large Language Models (LLMs) in comprehending and following natural language instructions is critical for their deployment in sophisticated real-world applications. Existing evaluations mainly focus on fragmented constraints or narrow scenarios, but they overlook the comprehensiveness and authenticity of constraints from the user's perspective. To bridge this gap, we propose CFBench, a large-scale Comprehensive Constraints Following Benchmark for LLMs, featuring 1,000 curated samples that cover more than 200 real-life scenarios and over 50 NLP tasks. CFBench meticulously compiles constraints from real-world instructions and constructs an innovative systematic framework for constraint types, which includes 10 primary categories and over 25 subcategories, and ensures each constraint is seamlessly integrated within the instructions. To make certain that the evaluation of LLM outputs aligns with user perceptions, we propose an advanced methodology that integrates multi-dimensional assessment criteria with requirement prioritization, covering various perspectives of constraints, instructions, and requirement fulfillment. Evaluating current leading LLMs on CFBench reveals substantial room for improvement in constraints following, and we further investigate influencing factors and enhancement strategies. The data and code are publicly available at https://github.com/PKU-Baichuan-MLSystemLab/CFBench
Read more8/6/2024
💬
0
FollowBench: A Multi-level Fine-grained Constraints Following Benchmark for Large Language Models
Yuxin Jiang, Yufei Wang, Xingshan Zeng, Wanjun Zhong, Liangyou Li, Fei Mi, Lifeng Shang, Xin Jiang, Qun Liu, Wei Wang
The ability to follow instructions is crucial for Large Language Models (LLMs) to handle various real-world applications. Existing benchmarks primarily focus on evaluating pure response quality, rather than assessing whether the response follows constraints stated in the instruction. To fill this research gap, in this paper, we propose FollowBench, a Multi-level Fine-grained Constraints Following Benchmark for LLMs. FollowBench comprehensively includes five different types (i.e., Content, Situation, Style, Format, and Example) of fine-grained constraints. To enable a precise constraint following estimation on diverse difficulties, we introduce a Multi-level mechanism that incrementally adds a single constraint to the initial instruction at each increased level. To assess whether LLMs' outputs have satisfied every individual constraint, we propose to prompt strong LLMs with constraint-evolution paths to handle challenging open-ended instructions. By evaluating 13 closed-source and open-source popular LLMs on FollowBench, we highlight the weaknesses of LLMs in instruction following and point towards potential avenues for future work. The data and code are publicly available at https://github.com/YJiangcm/FollowBench.
Read more6/6/2024
0
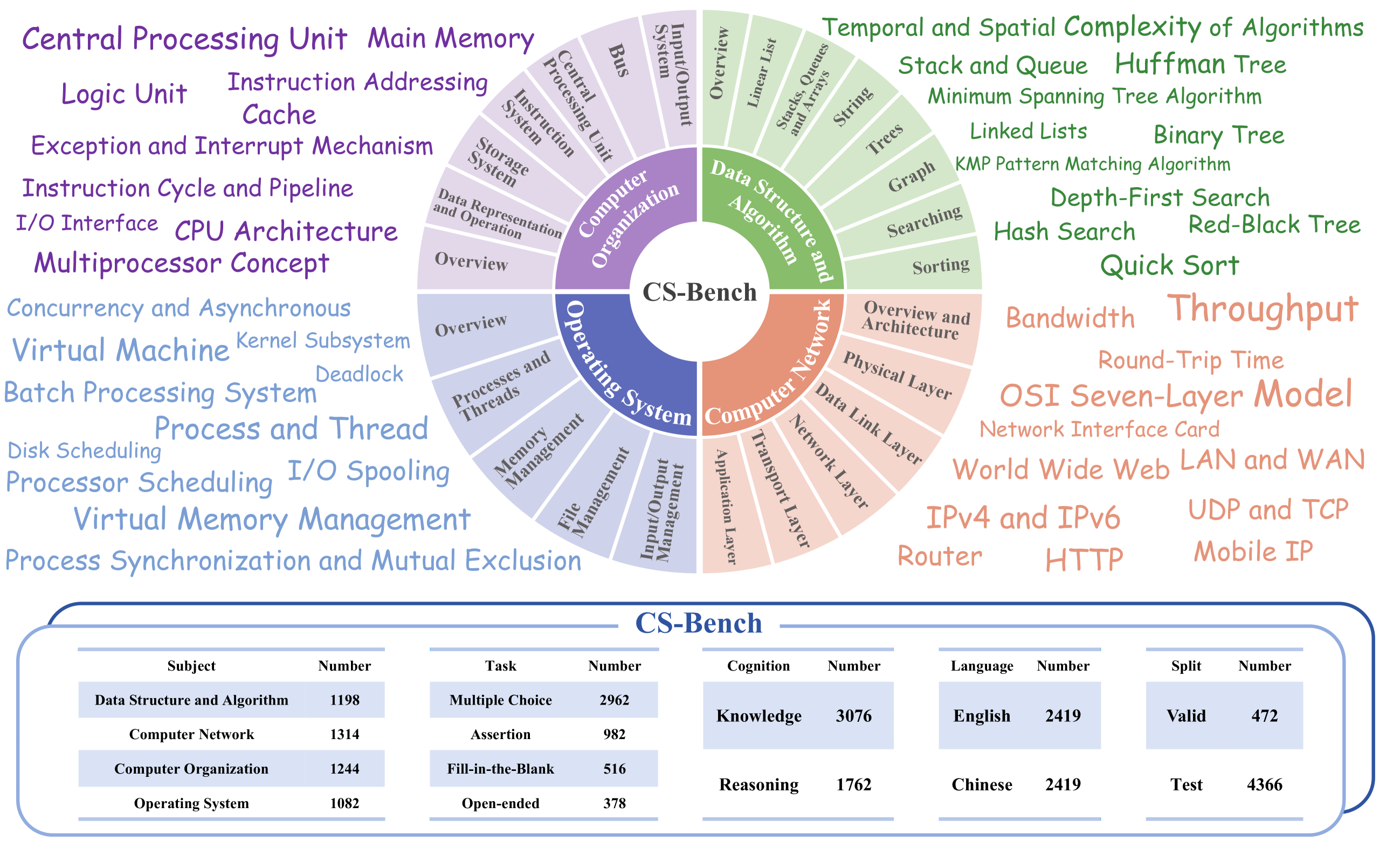
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
Read more6/14/2024

0
Benchmarking Complex Instruction-Following with Multiple Constraints Composition
Bosi Wen, Pei Ke, Xiaotao Gu, Lindong Wu, Hao Huang, Jinfeng Zhou, Wenchuang Li, Binxin Hu, Wendy Gao, Jiaxin Xu, Yiming Liu, Jie Tang, Hongning Wang, Minlie Huang
Instruction following is one of the fundamental capabilities of large language models (LLMs). As the ability of LLMs is constantly improving, they have been increasingly applied to deal with complex human instructions in real-world scenarios. Therefore, how to evaluate the ability of complex instruction-following of LLMs has become a critical research problem. Existing benchmarks mainly focus on modeling different types of constraints in human instructions while neglecting the composition of different constraints, which is an indispensable constituent in complex instructions. To this end, we propose ComplexBench, a benchmark for comprehensively evaluating the ability of LLMs to follow complex instructions composed of multiple constraints. We propose a hierarchical taxonomy for complex instructions, including 4 constraint types, 19 constraint dimensions, and 4 composition types, and manually collect a high-quality dataset accordingly. To make the evaluation reliable, we augment LLM-based evaluators with rules to effectively verify whether generated texts can satisfy each constraint and composition. Furthermore, we obtain the final evaluation score based on the dependency structure determined by different composition types. ComplexBench identifies significant deficiencies in existing LLMs when dealing with complex instructions with multiple constraints composition.
Read more7/12/2024