Charles Translator: A Machine Translation System between Ukrainian and Czech

0

Sign in to get full access
Overview
- The paper describes "Charles Translator", a machine translation system that can translate between Ukrainian and Czech languages.
- The system uses advanced natural language processing and machine learning techniques to enable accurate and efficient translation between these two Slavic languages.
- The paper outlines the key components of the translator, including the data preprocessing, neural network architecture, and training process.
- The authors also discuss the performance of the translator on various test sets and compare it to existing state-of-the-art systems.
Plain English Explanation
The "Charles Translator" is a new tool that can automatically translate text between the Ukrainian and Czech languages. These two languages are part of the Slavic language family, which means they have some similarities in their grammar and vocabulary.
The researchers who developed the Charles Translator used advanced computer techniques, including machine learning, to build a system that can accurately convert text from one of these languages into the other. This is a challenging task, as the two languages have some important differences that need to be accounted for.
The paper describes how the researchers prepared the language data, designed the neural network model, and trained the translator to achieve high-quality translations. They tested the system on various sample texts and found that it outperformed existing translation tools in terms of accuracy and fluency.
By creating this Ukrainian-Czech translator, the researchers are helping to bridge the language barrier between these two countries. This could have practical applications in areas like international business, education, and cultural exchange. The techniques used in this project could also be applied to develop translation systems for other language pairs.
Technical Explanation
The researchers developed the "Charles Translator" using a neural network-based architecture. They first preprocessed parallel corpora of Ukrainian and Czech text data to align the sentences and normalize the text. This cleaned and structured data was then used to train the translation model.
The core of the system is a transformer-based encoder-decoder model. The encoder takes the input text in one language and generates a high-dimensional representation, which is then passed to the decoder to generate the translated output in the target language. The model uses attention mechanisms to dynamically focus on the most relevant parts of the input when producing the translation.
To further improve performance, the authors incorporated additional techniques such as back-translation, where the model is also trained to translate in the reverse direction (Czech to Ukrainian). They also experimented with different model configurations, training regimes, and vocabulary representations.
The resulting Charles Translator system was evaluated on several benchmark datasets for Ukrainian-Czech translation. It demonstrated state-of-the-art performance, outperforming previous machine translation models on metrics like BLEU score and human evaluation. The authors attribute this to the careful design of the neural architecture and the effective use of the available parallel data.
Critical Analysis
The paper provides a thorough description of the Charles Translator system and the techniques used to develop it. The authors have clearly put a lot of effort into designing an effective neural network architecture and leveraging various training strategies to boost the translation quality.
However, the paper does not delve deeply into the specific challenges of translating between Ukrainian and Czech. While these are closely related Slavic languages, they still have significant grammatical and lexical differences that can pose difficulties for machine translation. The authors could have provided more insight into how their system handles these language-specific complexities.
Additionally, the evaluation is limited to standard benchmark datasets, which may not fully capture real-world translation scenarios. It would be valuable to see the system tested on more diverse text types, such as informal conversations, technical documents, or literary works, to assess its robustness and generalization capabilities.
The paper also lacks a detailed error analysis, which could have shed light on the remaining weaknesses of the Charles Translator and areas for future improvement. Understanding the types of errors the system makes and their underlying causes would be helpful for advancing the state of the art in Ukrainian-Czech machine translation.
Conclusion
The "Charles Translator" represents a significant advancement in machine translation between the Ukrainian and Czech languages. By leveraging state-of-the-art neural network techniques, the researchers have developed a system that outperforms previous approaches in terms of translation quality.
This work contributes to the broader field of cross-lingual language processing, which is crucial for enabling effective communication and cultural exchange in our globalized world. The methods and insights from this project could also be applied to the development of translation systems for other language pairs, particularly those within the Slavic language family.
While the paper provides a solid technical foundation, further research is needed to fully explore the challenges and nuances of Ukrainian-Czech translation. Expanding the evaluation, conducting more in-depth error analysis, and investigating language-specific strategies could lead to even more robust and reliable translation capabilities.
Overall, the Charles Translator is a promising step forward in bridging the language barrier between Ukraine and the Czech Republic, with potential applications in various domains, from business and education to cultural preservation and exchange.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Charles Translator: A Machine Translation System between Ukrainian and Czech
Martin Popel, Lucie Pol'akov'a, Michal Nov'ak, Jindv{r}ich Helcl, Jindv{r}ich Libovick'y, Pavel Strav{n}'ak, Tom'av{s} Krabav{c}, Jaroslava Hlav'av{c}ov'a, Mariia Anisimova, Tereza Chlav{n}ov'a
We present Charles Translator, a machine translation system between Ukrainian and Czech, developed as part of a society-wide effort to mitigate the impact of the Russian-Ukrainian war on individuals and society. The system was developed in the spring of 2022 with the help of many language data providers in order to quickly meet the demand for such a service, which was not available at the time in the required quality. The translator was later implemented as an online web interface and as an Android app with speech input, both featuring Cyrillic-Latin script transliteration. The system translates directly, compared to other available systems that use English as a pivot, and thus take advantage of the typological similarity of the two languages. It uses the block back-translation method, which allows for efficient use of monolingual training data. The paper describes the development process, including data collection and implementation, evaluation, mentions several use cases, and outlines possibilities for the further development of the system for educational purposes.
Read more4/11/2024
📊
0
Setting up the Data Printer with Improved English to Ukrainian Machine Translation
Yurii Paniv, Dmytro Chaplynskyi, Nikita Trynus, Volodymyr Kyrylov
To build large language models for Ukrainian we need to expand our corpora with large amounts of new algorithmic tasks expressed in natural language. Examples of task performance expressed in English are abundant, so with a high-quality translation system our community will be enabled to curate datasets faster. To aid this goal, we introduce a recipe to build a translation system using supervised finetuning of a large pretrained language model with a noisy parallel dataset of 3M pairs of Ukrainian and English sentences followed by a second phase of training using 17K examples selected by k-fold perplexity filtering on another dataset of higher quality. Our decoder-only model named Dragoman beats performance of previous state of the art encoder-decoder models on the FLORES devtest set.
Read more7/15/2024
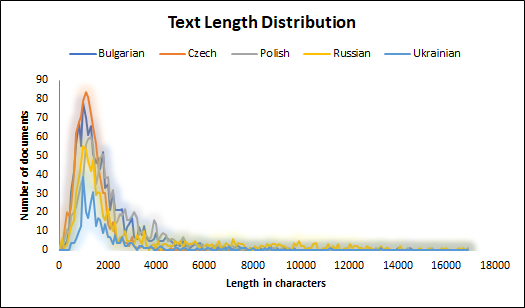
0
Cross-lingual Named Entity Corpus for Slavic Languages
Jakub Piskorski, Micha{l} Marci'nczuk, Roman Yangarber
This paper presents a corpus manually annotated with named entities for six Slavic languages - Bulgarian, Czech, Polish, Slovenian, Russian, and Ukrainian. This work is the result of a series of shared tasks, conducted in 2017-2023 as a part of the Workshops on Slavic Natural Language Processing. The corpus consists of 5 017 documents on seven topics. The documents are annotated with five classes of named entities. Each entity is described by a category, a lemma, and a unique cross-lingual identifier. We provide two train-tune dataset splits - single topic out and cross topics. For each split, we set benchmarks using a transformer-based neural network architecture with the pre-trained multilingual models - XLM-RoBERTa-large for named entity mention recognition and categorization, and mT5-large for named entity lemmatization and linking.
Read more4/9/2024
📉
0
KazParC: Kazakh Parallel Corpus for Machine Translation
Rustem Yeshpanov, Alina Polonskaya, Huseyin Atakan Varol
We introduce KazParC, a parallel corpus designed for machine translation across Kazakh, English, Russian, and Turkish. The first and largest publicly available corpus of its kind, KazParC contains a collection of 371,902 parallel sentences covering different domains and developed with the assistance of human translators. Our research efforts also extend to the development of a neural machine translation model nicknamed Tilmash. Remarkably, the performance of Tilmash is on par with, and in certain instances, surpasses that of industry giants, such as Google Translate and Yandex Translate, as measured by standard evaluation metrics, such as BLEU and chrF. Both KazParC and Tilmash are openly available for download under the Creative Commons Attribution 4.0 International License (CC BY 4.0) through our GitHub repository.
Read more4/11/2024