Chat-Edit-3D: Interactive 3D Scene Editing via Text Prompts

0

Sign in to get full access
Overview
• This paper presents Chat-Edit-3D, a novel system that allows users to interactively edit 3D scenes using natural language prompts.
• The system integrates large language models and vision-language models to enable users to describe desired changes to a 3D scene, which the system then implements.
• This approach allows for more intuitive and flexible 3D scene editing compared to traditional methods that rely on manual manipulation of 3D objects and parameters.
Plain English Explanation
The researchers have developed a new system called Chat-Edit-3D that lets people edit and change 3D scenes using regular text prompts, similar to how you might chat with someone. Instead of having to directly manipulate 3D objects and settings, you can simply describe the changes you want to make, and the system will automatically implement those changes.
This is made possible by combining two powerful AI technologies - large language models and vision-language models. The language model allows the system to understand the natural language instructions provided by the user, while the vision-language model can translate those instructions into the appropriate changes to the 3D scene.
For example, you could say "Add a red chair in the corner of the room" and the system would place a new red chair in the specified location. Or you could say "Make the table a bit bigger and move it closer to the window" and the system would adjust the table's size and position accordingly.
This approach makes 3D scene editing much more intuitive and accessible, as it doesn't require specialized 3D modeling skills or knowledge. Users can focus on expressing their creative vision in natural language, and let the AI handle the technical details of implementing those changes in the 3D environment.
Technical Explanation
The Chat-Edit-3D system consists of three main components:
-
Language Model: A large pretrained language model that can understand and parse the natural language instructions provided by the user.
-
Vision-Language Model: A model that can translate the user's text prompts into the appropriate changes to be made to the 3D scene, by learning the relationship between language and 3D visual representations.
-
3D Scene Rendering and Editing: A 3D rendering and scene editing engine that can take the instructions from the vision-language model and apply the desired changes to the 3D environment.
The researchers trained and fine-tuned these models on large datasets of 3D scenes and associated text descriptions, in order to enable the system to robustly interpret and execute a wide variety of text-based editing commands.
Through experiments, the authors demonstrate that Chat-Edit-3D outperforms previous state-of-the-art text-to-3D generation and editing approaches, both in terms of the quality of the edited 3D scenes and the ease of use for the end users.
Critical Analysis
The authors acknowledge several limitations of the current Chat-Edit-3D system:
-
The system is limited to editing existing 3D scenes, and cannot generate completely new scenes from scratch based on text prompts. [See: MATE3D: Mask-Guided Text-Based 3D Scene Editing]
-
The range of editable scene elements is still constrained compared to the full flexibility of manual 3D modeling. More advanced text-to-3D editing capabilities are an area for further research. [See: Instant3D: Instant Text-to-3D Generation with Neural Radiance Fields]
-
The system currently requires a full 3D scene as input, and does not yet support more freeform text-to-3D generation from just a language prompt. [See: TIP-Editor: Accurate 3D Editor Following Both Local and Global Constraints]
-
Evaluating the usability and real-world practicality of the system with end users is an important next step. [See: IDEA^2: 3D Collaborative LMM Agents Enable Fast and Coherent 3D Editing]
Overall, the Chat-Edit-3D system represents a promising step towards more natural and intuitive 3D scene editing experiences powered by advanced language and vision AI models. With continued research and development, these kinds of text-driven 3D editing tools could become invaluable for a wide range of applications, from architectural design to video game development and beyond.
Conclusion
The Chat-Edit-3D system presented in this paper demonstrates how the combination of large language models and vision-language models can enable a new paradigm of 3D scene editing. By allowing users to describe their desired changes in natural language, the system removes many of the technical barriers associated with traditional 3D modeling and manipulation.
This research paves the way for more accessible and flexible 3D content creation tools, which could have significant implications for fields like architecture, urban planning, product design, entertainment, and others that rely heavily on 3D visualization and modeling. As language AI and multimodal learning continue to advance, the potential for text-driven 3D editing and generation will only grow, transforming how we interact with and create virtual environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Chat-Edit-3D: Interactive 3D Scene Editing via Text Prompts
Shuangkang Fang, Yufeng Wang, Yi-Hsuan Tsai, Yi Yang, Wenrui Ding, Shuchang Zhou, Ming-Hsuan Yang
Recent work on image content manipulation based on vision-language pre-training models has been effectively extended to text-driven 3D scene editing. However, existing schemes for 3D scene editing still exhibit certain shortcomings, hindering their further interactive design. Such schemes typically adhere to fixed input patterns, limiting users' flexibility in text input. Moreover, their editing capabilities are constrained by a single or a few 2D visual models and require intricate pipeline design to integrate these models into 3D reconstruction processes. To address the aforementioned issues, we propose a dialogue-based 3D scene editing approach, termed CE3D, which is centered around a large language model that allows for arbitrary textual input from users and interprets their intentions, subsequently facilitating the autonomous invocation of the corresponding visual expert models. Furthermore, we design a scheme utilizing Hash-Atlas to represent 3D scene views, which transfers the editing of 3D scenes onto 2D atlas images. This design achieves complete decoupling between the 2D editing and 3D reconstruction processes, enabling CE3D to flexibly integrate a wide range of existing 2D or 3D visual models without necessitating intricate fusion designs. Experimental results demonstrate that CE3D effectively integrates multiple visual models to achieve diverse editing visual effects, possessing strong scene comprehension and multi-round dialog capabilities. The code is available at https://sk-fun.fun/CE3D.
Read more7/11/2024

0
Free-Editor: Zero-shot Text-driven 3D Scene Editing
Nazmul Karim, Hasan Iqbal, Umar Khalid, Jing Hua, Chen Chen
Text-to-Image (T2I) diffusion models have recently gained traction for their versatility and user-friendliness in 2D content generation and editing. However, training a diffusion model specifically for 3D scene editing is challenging due to the scarcity of large-scale datasets. Currently, editing 3D scenes necessitates either retraining the model to accommodate various 3D edits or developing specific methods tailored to each unique editing type. Moreover, state-of-the-art (SOTA) techniques require multiple synchronized edited images from the same scene to enable effective scene editing. Given the current limitations of T2I models, achieving consistent editing effects across multiple images remains difficult, leading to multi-view inconsistency in editing. This inconsistency undermines the performance of 3D scene editing when these images are utilized. In this study, we introduce a novel, training-free 3D scene editing technique called textsc{Free-Editor}, which enables users to edit 3D scenes without the need for model retraining during the testing phase. Our method effectively addresses the issue of multi-view style inconsistency found in state-of-the-art (SOTA) methods through the implementation of a single-view editing scheme. Specifically, we demonstrate that editing a particular 3D scene can be achieved by modifying only a single view. To facilitate this, we present an Edit Transformer that ensures intra-view consistency and inter-view style transfer using self-view and cross-view attention mechanisms, respectively. By eliminating the need for model retraining and multi-view editing, our approach significantly reduces editing time and memory resource requirements, achieving runtimes approximately 20 times faster than SOTA methods. We have performed extensive experiments on various benchmark datasets, showcasing the diverse editing capabilities of our proposed technique.
Read more7/16/2024

0
SceneTeller: Language-to-3D Scene Generation
Bac{s}ak Melis Ocal, Maxim Tatarchenko, Sezer Karaoglu, Theo Gevers
Designing high-quality indoor 3D scenes is important in many practical applications, such as room planning or game development. Conventionally, this has been a time-consuming process which requires both artistic skill and familiarity with professional software, making it hardly accessible for layman users. However, recent advances in generative AI have established solid foundation for democratizing 3D design. In this paper, we propose a pioneering approach for text-based 3D room design. Given a prompt in natural language describing the object placement in the room, our method produces a high-quality 3D scene corresponding to it. With an additional text prompt the users can change the appearance of the entire scene or of individual objects in it. Built using in-context learning, CAD model retrieval and 3D-Gaussian-Splatting-based stylization, our turnkey pipeline produces state-of-the-art 3D scenes, while being easy to use even for novices. Our project page is available at https://sceneteller.github.io/.
Read more7/31/2024
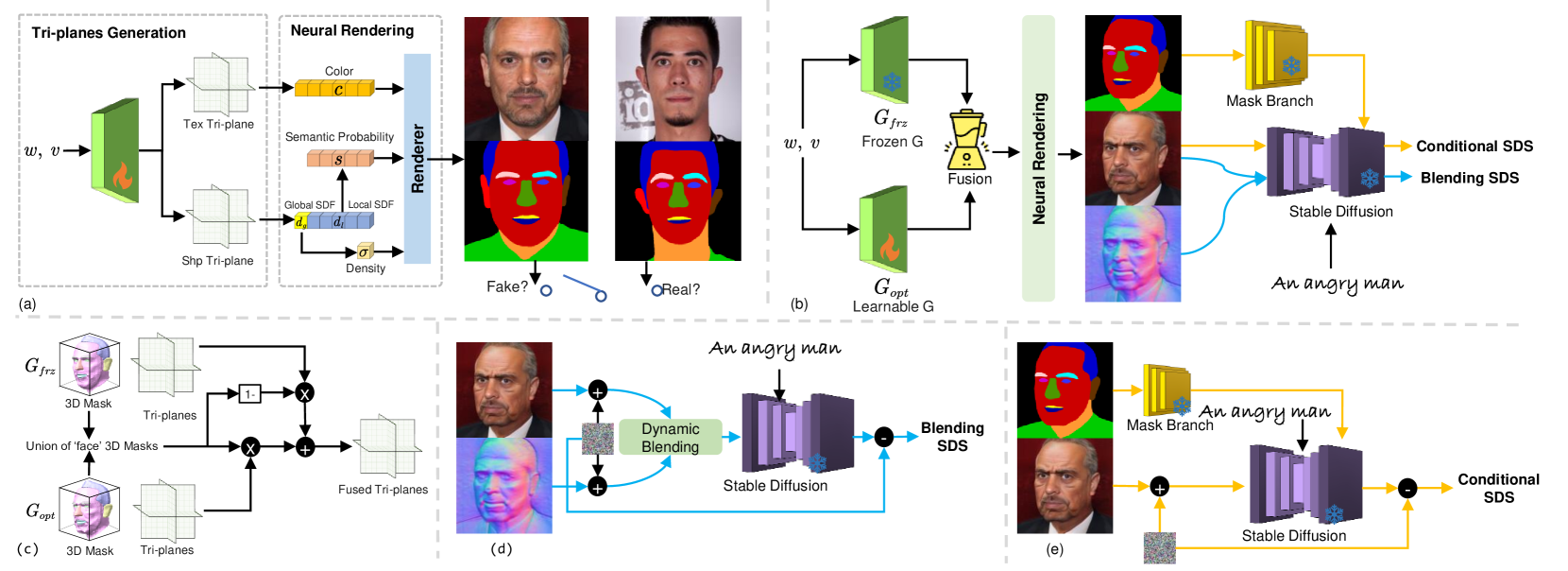
0
MaTe3D: Mask-guided Text-based 3D-aware Portrait Editing
Kangneng Zhou, Daiheng Gao, Xuan Wang, Jie Zhang, Peng Zhang, Xusen Sun, Longhao Zhang, Shiqi Yang, Bang Zhang, Liefeng Bo, Yaxing Wang, Ming-Ming Cheng
3D-aware portrait editing has a wide range of applications in multiple fields. However, current approaches are limited due that they can only perform mask-guided or text-based editing. Even by fusing the two procedures into a model, the editing quality and stability cannot be ensured. To address this limitation, we propose textbf{MaTe3D}: mask-guided text-based 3D-aware portrait editing. In this framework, first, we introduce a new SDF-based 3D generator which learns local and global representations with proposed SDF and density consistency losses. This enhances masked-based editing in local areas; second, we present a novel distillation strategy: Conditional Distillation on Geometry and Texture (CDGT). Compared to exiting distillation strategies, it mitigates visual ambiguity and avoids mismatch between texture and geometry, thereby producing stable texture and convincing geometry while editing. Additionally, we create the CatMask-HQ dataset, a large-scale high-resolution cat face annotation for exploration of model generalization and expansion. We perform expensive experiments on both the FFHQ and CatMask-HQ datasets to demonstrate the editing quality and stability of the proposed method. Our method faithfully generates a 3D-aware edited face image based on a modified mask and a text prompt. Our code and models will be publicly released.
Read more7/8/2024