Instant3D: Instant Text-to-3D Generation
2311.08403
0
0
🛸
Abstract
Text-to-3D generation has attracted much attention from the computer vision community. Existing methods mainly optimize a neural field from scratch for each text prompt, relying on heavy and repetitive training cost which impedes their practical deployment. In this paper, we propose a novel framework for fast text-to-3D generation, dubbed Instant3D. Once trained, Instant3D is able to create a 3D object for an unseen text prompt in less than one second with a single run of a feedforward network. We achieve this remarkable speed by devising a new network that directly constructs a 3D triplane from a text prompt. The core innovation of our Instant3D lies in our exploration of strategies to effectively inject text conditions into the network. In particular, we propose to combine three key mechanisms: cross-attention, style injection, and token-to-plane transformation, which collectively ensure precise alignment of the output with the input text. Furthermore, we propose a simple yet effective activation function, the scaled-sigmoid, to replace the original sigmoid function, which speeds up the training convergence by more than ten times. Finally, to address the Janus (multi-head) problem in 3D generation, we propose an adaptive Perp-Neg algorithm that can dynamically adjust its concept negation scales according to the severity of the Janus problem during training, effectively reducing the multi-head effect. Extensive experiments on a wide variety of benchmark datasets demonstrate that the proposed algorithm performs favorably against the state-of-the-art methods both qualitatively and quantitatively, while achieving significantly better efficiency. The code, data, and models are available at https://github.com/ming1993li/Instant3DCodes.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Existing text-to-3D generation methods are slow and require heavy training, limiting practical deployment
- This paper proposes a novel framework called Instant3D that can generate 3D objects from text in less than a second
- Key innovations include effective text condition injection, a new activation function, and an adaptive algorithm to address the Janus (multi-head) problem in 3D generation
Plain English Explanation
Creating 3D objects from text descriptions has been a challenging task in computer vision. Existing methods typically require a lot of computing power and time to train a neural network from scratch for each new text prompt. This makes it difficult to use these methods in practical applications.
The researchers in this paper have developed a new system called Instant3D that can generate 3D objects from text much faster. After an initial training phase, Instant3D can create a 3D object for an entirely new text prompt in less than a second, using a single pass of a neural network.
The key innovations that enable this speed are:
- Text Condition Injection: Instant3D uses a combination of cross-attention, style injection, and token-to-plane transformation to tightly align the 3D output with the input text.
- Scaled-sigmoid Activation: The researchers developed a new activation function that speeds up the training process by more than 10 times compared to the standard sigmoid function.
- Adaptive Perp-Neg Algorithm: This algorithm dynamically adjusts the concept negation scales during training to address the Janus (multi-head) problem in 3D generation, reducing undesirable effects.
These advances allow Instant3D to outperform state-of-the-art text-to-3D generation methods both in terms of quality and efficiency, as demonstrated across a variety of benchmark datasets.
Technical Explanation
The Instant3D framework works by directly constructing a 3D triplane representation from a given text prompt, without the need for heavy and repetitive training like previous approaches.
The key innovation lies in the researchers' exploration of effective strategies to inject text conditions into the neural network. They propose three main mechanisms:
- Cross-attention: This allows the network to attend to relevant parts of the text when generating different regions of the 3D output.
- Style Injection: The text features are injected into the network's style parameters, enabling fine-grained control over the 3D generation.
- Token-to-plane Transformation: This maps the text tokens directly to the 3D triplane, ensuring precise alignment between the input and output.
Additionally, the researchers introduce a new activation function called "scaled-sigmoid" that speeds up training convergence by more than 10 times compared to the standard sigmoid.
To address the Janus (multi-head) problem in 3D generation, where the network produces multiple unrelated objects, the researchers propose an Adaptive Perp-Neg algorithm. This dynamically adjusts the concept negation scales during training based on the severity of the Janus problem, effectively reducing the multi-head effect.
Extensive experiments on a variety of benchmark datasets show that Instant3D performs favorably against state-of-the-art methods in both qualitative and quantitative evaluations, while achieving significantly better efficiency.
Critical Analysis
The researchers have made impressive strides in improving the speed and performance of text-to-3D generation, as evidenced by the Instant3D framework. The ability to generate 3D objects from text in less than a second is a remarkable achievement that could have significant practical applications, such as in interactive 3D design or text-guided 3D portrait generation.
That said, the paper does not delve into the potential limitations or caveats of the Instant3D approach. For example, it's unclear how the system would handle more complex or abstract text prompts, or whether there are any restrictions on the types of 3D objects that can be generated.
Additionally, the researchers' claim of "significantly better efficiency" could be further substantiated by providing more detailed performance metrics and comparisons to other state-of-the-art methods, beyond just the qualitative and high-level quantitative evaluations.
It would also be interesting to see how Instant3D's performance compares to other emerging text-to-3D generation techniques, such as those using Gaussian splatting or diffusion models. Exploring the trade-offs between speed, quality, and flexibility could help researchers and practitioners make more informed decisions when choosing the appropriate text-to-3D generation approach for their needs.
Conclusion
The Instant3D framework proposed in this paper represents a significant advancement in the field of text-to-3D generation. By devising innovative techniques to effectively inject text conditions into the network and addressing key challenges like the Janus problem, the researchers have developed a system that can generate 3D objects from text in under a second, while maintaining high quality.
This level of speed and efficiency could unlock new possibilities for interactive 3D design, virtual prototyping, and other applications that require real-time 3D content creation from textual descriptions. As the researchers continue to refine and expand the capabilities of Instant3D, it will be exciting to see how this technology evolves and shapes the future of 3D generation and interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
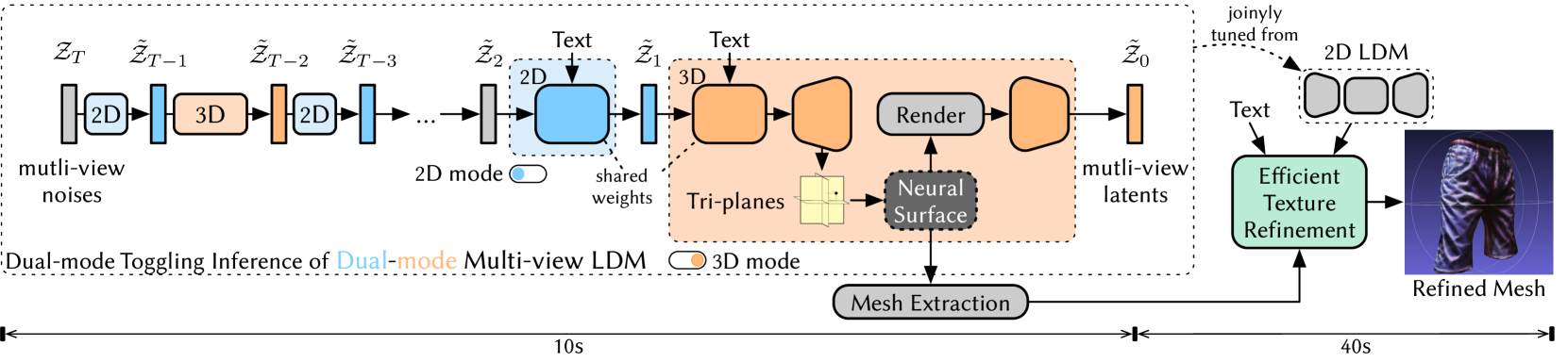
New!Dual3D: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion
Xinyang Li, Zhangyu Lai, Linning Xu, Jianfei Guo, Liujuan Cao, Shengchuan Zhang, Bo Dai, Rongrong Ji
0
0
We present Dual3D, a novel text-to-3D generation framework that generates high-quality 3D assets from texts in only $1$ minute.The key component is a dual-mode multi-view latent diffusion model. Given the noisy multi-view latents, the 2D mode can efficiently denoise them with a single latent denoising network, while the 3D mode can generate a tri-plane neural surface for consistent rendering-based denoising. Most modules for both modes are tuned from a pre-trained text-to-image latent diffusion model to circumvent the expensive cost of training from scratch. To overcome the high rendering cost during inference, we propose the dual-mode toggling inference strategy to use only $1/10$ denoising steps with 3D mode, successfully generating a 3D asset in just $10$ seconds without sacrificing quality. The texture of the 3D asset can be further enhanced by our efficient texture refinement process in a short time. Extensive experiments demonstrate that our method delivers state-of-the-art performance while significantly reducing generation time. Our project page is available at https://dual3d.github.io
5/17/2024

PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion
Ying-Tian Liu, Yuan-Chen Guo, Guan Luo, Heyi Sun, Wei Yin, Song-Hai Zhang
0
0
Diffusion models trained on large-scale text-image datasets have demonstrated a strong capability of controllable high-quality image generation from arbitrary text prompts. However, the generation quality and generalization ability of 3D diffusion models is hindered by the scarcity of high-quality and large-scale 3D datasets. In this paper, we present PI3D, a framework that fully leverages the pre-trained text-to-image diffusion models' ability to generate high-quality 3D shapes from text prompts in minutes. The core idea is to connect the 2D and 3D domains by representing a 3D shape as a set of Pseudo RGB Images. We fine-tune an existing text-to-image diffusion model to produce such pseudo-images using a small number of text-3D pairs. Surprisingly, we find that it can already generate meaningful and consistent 3D shapes given complex text descriptions. We further take the generated shapes as the starting point for a lightweight iterative refinement using score distillation sampling to achieve high-quality generation under a low budget. PI3D generates a single 3D shape from text in only 3 minutes and the quality is validated to outperform existing 3D generative models by a large margin.
4/23/2024
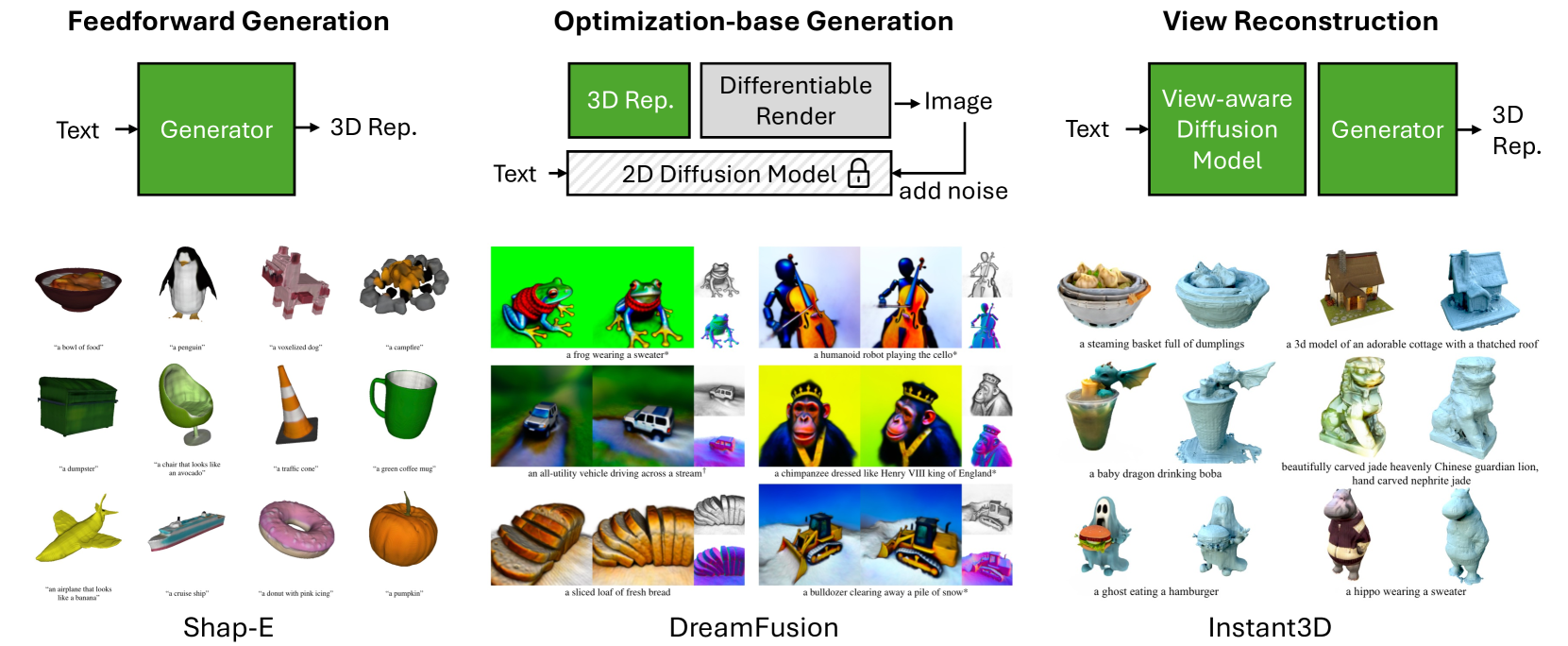
A Survey On Text-to-3D Contents Generation In The Wild
Chenhan Jiang
0
0
3D content creation plays a vital role in various applications, such as gaming, robotics simulation, and virtual reality. However, the process is labor-intensive and time-consuming, requiring skilled designers to invest considerable effort in creating a single 3D asset. To address this challenge, text-to-3D generation technologies have emerged as a promising solution for automating 3D creation. Leveraging the success of large vision language models, these techniques aim to generate 3D content based on textual descriptions. Despite recent advancements in this area, existing solutions still face significant limitations in terms of generation quality and efficiency. In this survey, we conduct an in-depth investigation of the latest text-to-3D creation methods. We provide a comprehensive background on text-to-3D creation, including discussions on datasets employed in training and evaluation metrics used to assess the quality of generated 3D models. Then, we delve into the various 3D representations that serve as the foundation for the 3D generation process. Furthermore, we present a thorough comparison of the rapidly growing literature on generative pipelines, categorizing them into feedforward generators, optimization-based generation, and view reconstruction approaches. By examining the strengths and weaknesses of these methods, we aim to shed light on their respective capabilities and limitations. Lastly, we point out several promising avenues for future research. With this survey, we hope to inspire researchers further to explore the potential of open-vocabulary text-conditioned 3D content creation.
5/16/2024

Interactive3D: Create What You Want by Interactive 3D Generation
Shaocong Dong, Lihe Ding, Zhanpeng Huang, Zibin Wang, Tianfan Xue, Dan Xu
0
0
3D object generation has undergone significant advancements, yielding high-quality results. However, fall short of achieving precise user control, often yielding results that do not align with user expectations, thus limiting their applicability. User-envisioning 3D object generation faces significant challenges in realizing its concepts using current generative models due to limited interaction capabilities. Existing methods mainly offer two approaches: (i) interpreting textual instructions with constrained controllability, or (ii) reconstructing 3D objects from 2D images. Both of them limit customization to the confines of the 2D reference and potentially introduce undesirable artifacts during the 3D lifting process, restricting the scope for direct and versatile 3D modifications. In this work, we introduce Interactive3D, an innovative framework for interactive 3D generation that grants users precise control over the generative process through extensive 3D interaction capabilities. Interactive3D is constructed in two cascading stages, utilizing distinct 3D representations. The first stage employs Gaussian Splatting for direct user interaction, allowing modifications and guidance of the generative direction at any intermediate step through (i) Adding and Removing components, (ii) Deformable and Rigid Dragging, (iii) Geometric Transformations, and (iv) Semantic Editing. Subsequently, the Gaussian splats are transformed into InstantNGP. We introduce a novel (v) Interactive Hash Refinement module to further add details and extract the geometry in the second stage. Our experiments demonstrate that Interactive3D markedly improves the controllability and quality of 3D generation. Our project webpage is available at url{https://interactive-3d.github.io/}.
4/26/2024