ChatGPT Can Predict the Future when it Tells Stories Set in the Future About the Past
2404.07396
29
0
Abstract
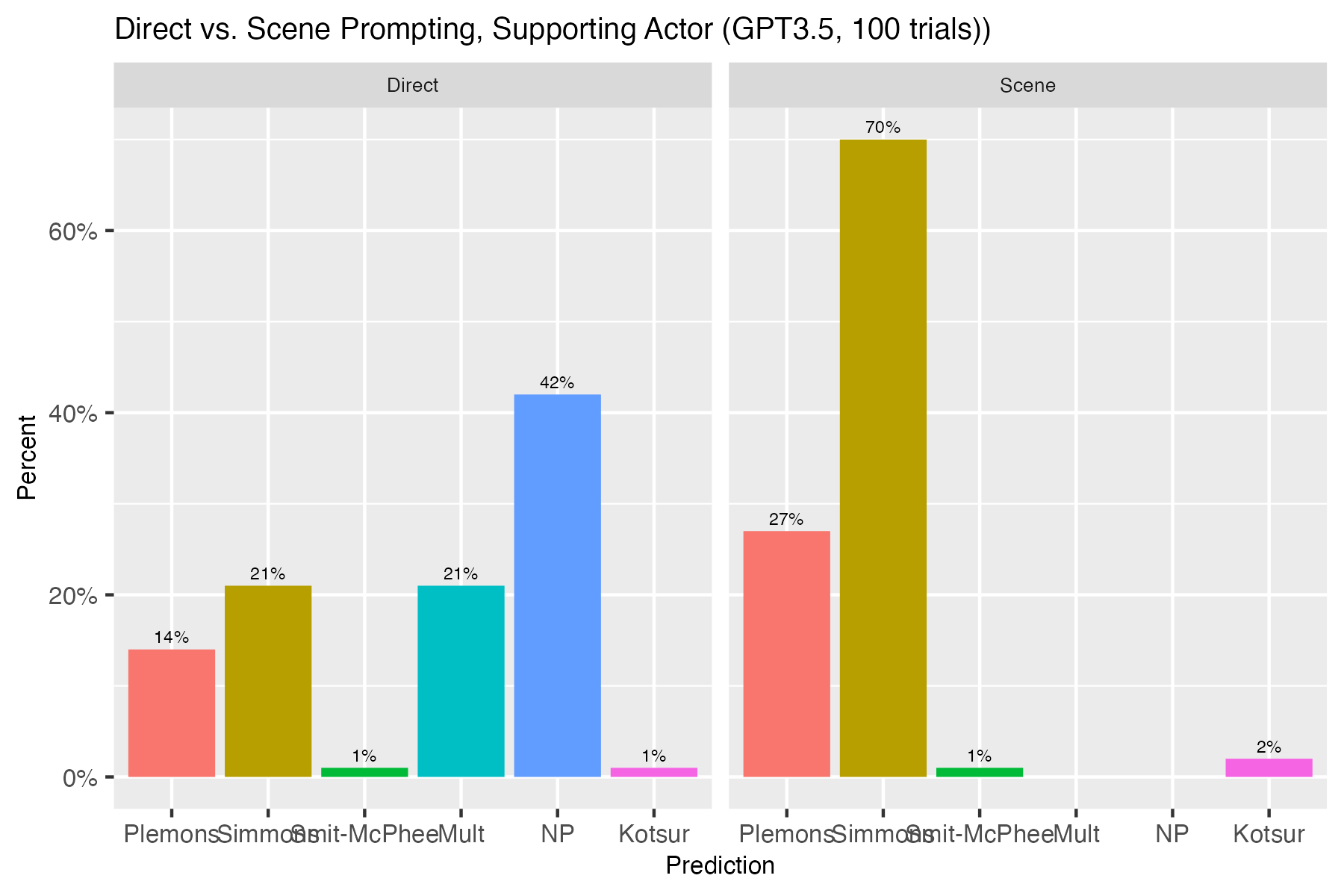
This study investigates whether OpenAI's ChatGPT-3.5 and ChatGPT-4 can accurately forecast future events using two distinct prompting strategies. To evaluate the accuracy of the predictions, we take advantage of the fact that the training data at the time of experiment stopped at September 2021, and ask about events that happened in 2022 using ChatGPT-3.5 and ChatGPT-4. We employed two prompting strategies: direct prediction and what we call future narratives which ask ChatGPT to tell fictional stories set in the future with characters that share events that have happened to them, but after ChatGPT's training data had been collected. Concentrating on events in 2022, we prompted ChatGPT to engage in storytelling, particularly within economic contexts. After analyzing 100 prompts, we discovered that future narrative prompts significantly enhanced ChatGPT-4's forecasting accuracy. This was especially evident in its predictions of major Academy Award winners as well as economic trends, the latter inferred from scenarios where the model impersonated public figures like the Federal Reserve Chair, Jerome Powell. These findings indicate that narrative prompts leverage the models' capacity for hallucinatory narrative construction, facilitating more effective data synthesis and extrapolation than straightforward predictions. Our research reveals new aspects of LLMs' predictive capabilities and suggests potential future applications in analytical contexts.
Create account to get full access
Overview
- The paper investigates how the language model ChatGPT can predict the future when telling stories set in the future about the past.
- It explores the differences between direct and narrative prediction approaches, and the prompting methodology and data collection process.
- The paper also provides a technical explanation of the research, a critical analysis, and a conclusion on the potential implications.
Plain English Explanation
The research paper examines how the AI language model ChatGPT can generate stories set in the future that make accurate predictions about the past. This is a surprising and counterintuitive finding, as one might expect an AI to struggle with predicting the past from the future.
The researchers compare two approaches to this task: direct prediction, where the AI is asked to make specific forecasts, and narrative prediction, where the AI is prompted to tell a story set in the future. Interestingly, the narrative approach appears to be more effective, allowing the AI to weave plausible details about the past into its future-set tales.
To investigate this phenomenon, the researchers developed a prompting methodology and collected data on the AI's performance. They found that ChatGPT was surprisingly adept at generating narratives that contained accurate historical information, even when the prompts asked it to imagine future scenarios.
Technical Explanation
The paper outlines a study that explores how the language model ChatGPT can generate stories set in the future that accurately predict aspects of the past. This counterintuitive finding is investigated through a comparison of two approaches: direct prediction, where the model is asked to make specific forecasts, and narrative prediction, where the model is prompted to tell a story set in the future.
The researchers developed a prompting methodology to elicit these future-set narratives from ChatGPT and collected data on the model's performance. They found that the narrative approach was more effective, allowing ChatGPT to weave plausible historical details into its future-oriented stories. This suggests that the model may be leveraging its broad knowledge of the world to construct coherent narratives, even when asked to imagine hypothetical future scenarios.
The paper provides a detailed technical explanation of the study design, data collection procedures, and key insights. It contributes to our understanding of the capabilities and limitations of large language models like ChatGPT and highlights the importance of examining their performance across different task domains.
Critical Analysis
The research presented in this paper offers a fascinating look at the unexpected predictive capabilities of language models like ChatGPT. However, it is important to consider several caveats and limitations.
First, the paper acknowledges that the narratives generated by ChatGPT may contain inaccuracies or inconsistencies, despite the model's apparent ability to weave in plausible historical details. This highlights the need for careful evaluation and validation of the model's outputs, especially when they are making claims about the past or the future.
Additionally, the study is based on a relatively small dataset and prompting methodology. It would be valuable to see the research expanded to a larger scale, with a more diverse range of prompts and evaluation criteria, to better understand the robustness and generalizability of the findings.
Finally, while the paper discusses the potential implications of this research, it does not delve deeply into the ethical considerations around the use of such predictive capabilities, particularly in the context of fake news generation and detection. As language models become more advanced, it will be crucial to address these concerns and ensure their responsible development and deployment.
Conclusion
The research presented in this paper offers a compelling look at the surprising predictive capabilities of the language model ChatGPT. By comparing direct and narrative approaches to forecasting the past from the future, the researchers have uncovered an intriguing phenomenon: ChatGPT is often able to generate plausible future-set stories that contain accurate historical details.
This finding contributes to our understanding of the strengths and limitations of large language models, and highlights the importance of examining their performance across a diverse range of tasks and applications. As these models continue to advance, it will be crucial to consider the ethical implications of their predictive abilities, particularly in the context of media bias and fake news. Overall, this research opens up new avenues for exploring the complex interplay between language, knowledge, and prediction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ChatGPT as Research Scientist: Probing GPT's Capabilities as a Research Librarian, Research Ethicist, Data Generator and Data Predictor
Steven A. Lehr, Aylin Caliskan, Suneragiri Liyanage, Mahzarin R. Banaji
0
0
How good a research scientist is ChatGPT? We systematically probed the capabilities of GPT-3.5 and GPT-4 across four central components of the scientific process: as a Research Librarian, Research Ethicist, Data Generator, and Novel Data Predictor, using psychological science as a testing field. In Study 1 (Research Librarian), unlike human researchers, GPT-3.5 and GPT-4 hallucinated, authoritatively generating fictional references 36.0% and 5.4% of the time, respectively, although GPT-4 exhibited an evolving capacity to acknowledge its fictions. In Study 2 (Research Ethicist), GPT-4 (though not GPT-3.5) proved capable of detecting violations like p-hacking in fictional research protocols, correcting 88.6% of blatantly presented issues, and 72.6% of subtly presented issues. In Study 3 (Data Generator), both models consistently replicated patterns of cultural bias previously discovered in large language corpora, indicating that ChatGPT can simulate known results, an antecedent to usefulness for both data generation and skills like hypothesis generation. Contrastingly, in Study 4 (Novel Data Predictor), neither model was successful at predicting new results absent in their training data, and neither appeared to leverage substantially new information when predicting more versus less novel outcomes. Together, these results suggest that GPT is a flawed but rapidly improving librarian, a decent research ethicist already, capable of data generation in simple domains with known characteristics but poor at predicting novel patterns of empirical data to aid future experimentation.
6/24/2024
RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm
Yabin Zhang, Wenhui Yu, Erhan Zhang, Xu Chen, Lantao Hu, Peng Jiang, Kun Gai
0
0
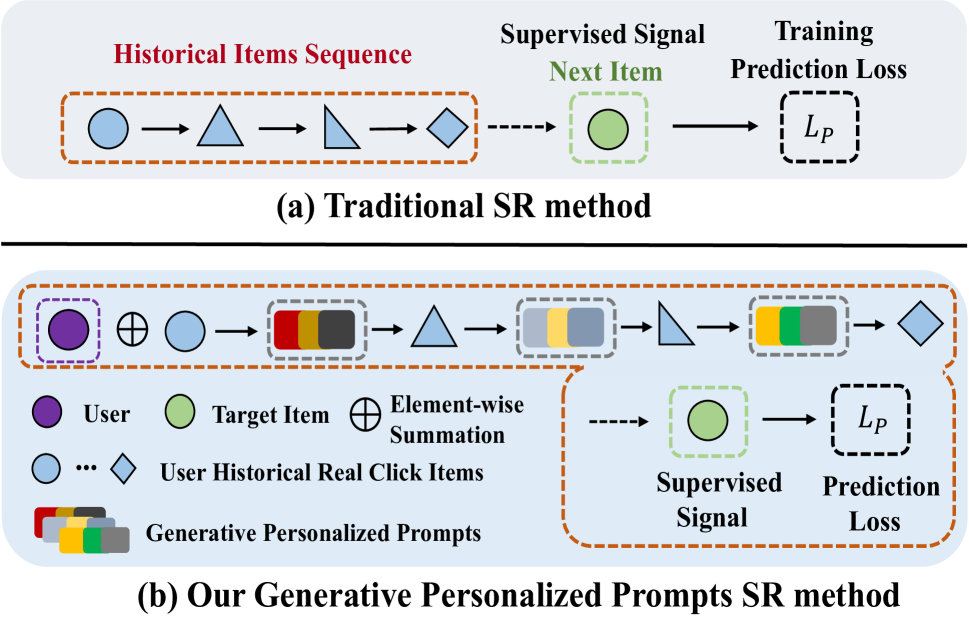
ChatGPT has achieved remarkable success in natural language understanding. Considering that recommendation is indeed a conversation between users and the system with items as words, which has similar underlying pattern with ChatGPT, we design a new chat framework in item index level for the recommendation task. Our novelty mainly contains three parts: model, training and inference. For the model part, we adopt Generative Pre-training Transformer (GPT) as the sequential recommendation model and design a user modular to capture personalized information. For the training part, we adopt the two-stage paradigm of ChatGPT, including pre-training and fine-tuning. In the pre-training stage, we train GPT model by auto-regression. In the fine-tuning stage, we train the model with prompts, which include both the newly-generated results from the model and the user's feedback. For the inference part, we predict several user interests as user representations in an autoregressive manner. For each interest vector, we recall several items with the highest similarity and merge the items recalled by all interest vectors into the final result. We conduct experiments with both offline public datasets and online A/B test to demonstrate the effectiveness of our proposed method.
4/16/2024
Future Language Modeling from Temporal Document History
Changmao Li, Jeffrey Flanigan
0
0
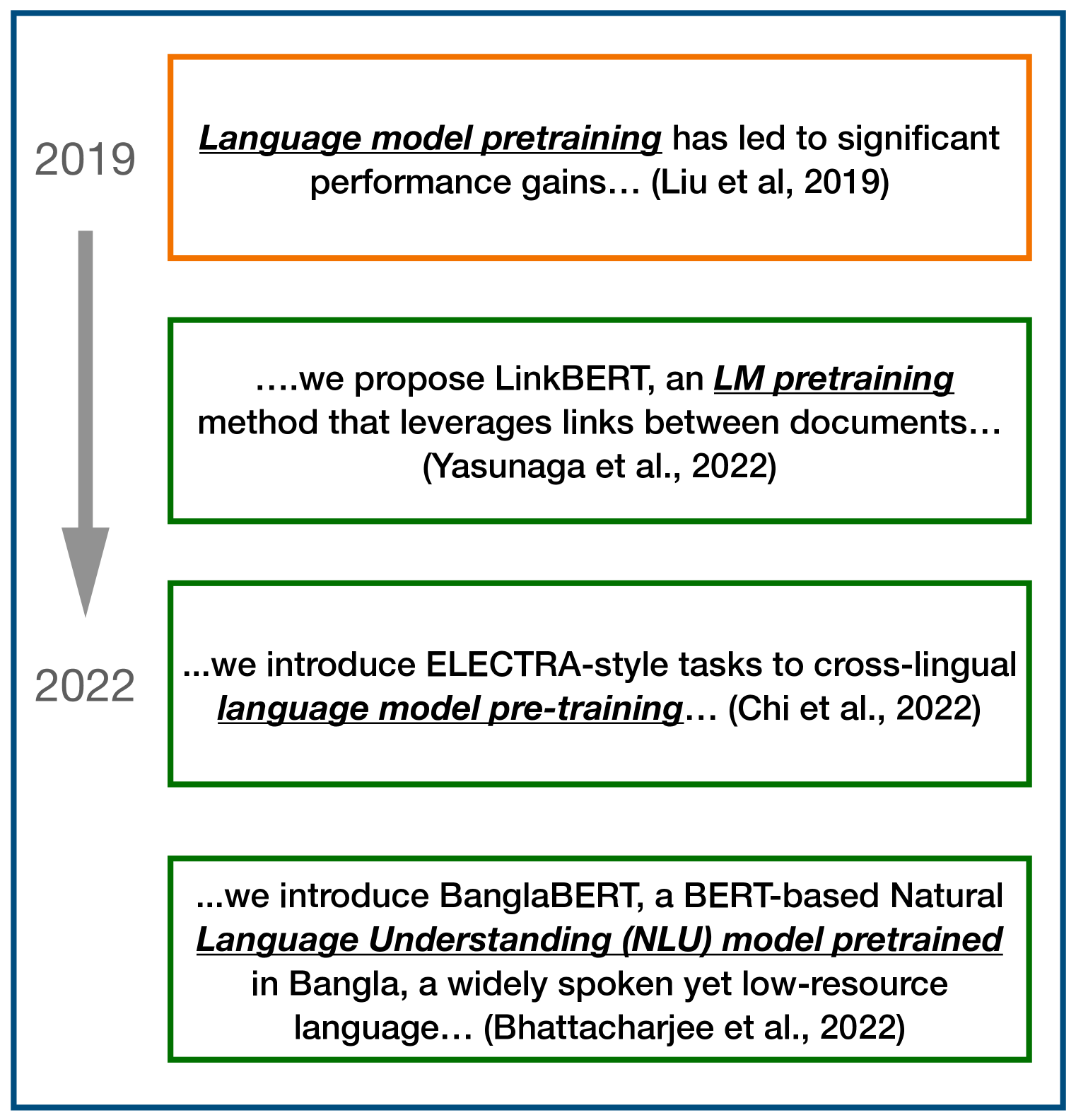
Predicting the future is of great interest across many aspects of human activity. Businesses are interested in future trends, traders are interested in future stock prices, and companies are highly interested in future technological breakthroughs. While there are many automated systems for predicting future numerical data, such as weather, stock prices, and demand for products, there is relatively little work in automatically predicting textual data. Humans are interested in textual data predictions because it is a natural format for our consumption, and experts routinely make predictions in a textual format (Christensen et al., 2004; Tetlock & Gardner, 2015; Frick, 2015). However, there has been relatively little formalization of this general problem in the machine learning or natural language processing communities. To address this gap, we introduce the task of future language modeling: probabilistic modeling of texts in the future based on a temporal history of texts. To our knowledge, our work is the first work to formalize the task of predicting the future in this way. We show that it is indeed possible to build future language models that improve upon strong non-temporal language model baselines, opening the door to working on this important, and widely applicable problem.
4/17/2024

(Chat)GPT v BERT: Dawn of Justice for Semantic Change Detection
Francesco Periti, Haim Dubossarsky, Nina Tahmasebi
0
0
In the universe of Natural Language Processing, Transformer-based language models like BERT and (Chat)GPT have emerged as lexical superheroes with great power to solve open research problems. In this paper, we specifically focus on the temporal problem of semantic change, and evaluate their ability to solve two diachronic extensions of the Word-in-Context (WiC) task: TempoWiC and HistoWiC. In particular, we investigate the potential of a novel, off-the-shelf technology like ChatGPT (and GPT) 3.5 compared to BERT, which represents a family of models that currently stand as the state-of-the-art for modeling semantic change. Our experiments represent the first attempt to assess the use of (Chat)GPT for studying semantic change. Our results indicate that ChatGPT performs significantly worse than the foundational GPT version. Furthermore, our results demonstrate that (Chat)GPT achieves slightly lower performance than BERT in detecting long-term changes but performs significantly worse in detecting short-term changes.
4/30/2024