ChatPCG: Large Language Model-Driven Reward Design for Procedural Content Generation

0

Sign in to get full access
Overview
- This paper introduces ChatPCG, a system that uses large language models to design rewards for procedural content generation in multiplayer, cooperative games.
- The key idea is to leverage the language understanding and generation capabilities of large language models to create engaging and meaningful game content automatically.
- The authors demonstrate the effectiveness of ChatPCG in generating levels for a cooperative game, showing how it can produce content that aligns with player preferences and promotes collaborative gameplay.
Plain English Explanation
The paper describes a new system called ChatPCG that uses powerful language models to help design rewards and content for procedural video game generation. The core innovation is that it taps into the remarkable text understanding and generation abilities of large language models to automatically create game levels and challenges that are tailored to what players will find fun and engaging.
Procedural content generation is a technique used in games to automatically create new game worlds, levels, or other elements, rather than having designers hand-craft everything. This can make games more replayable and reduce development time. However, the content generated can sometimes feel random or uninspired. ChatPCG: Large Language Model-Driven Reward Design for Procedural Content Generation aims to solve this by using advanced language models to imbue the generated content with meaning and align it with player preferences.
The key insight is that language models can understand the semantics and context of game content in a way that traditional procedural generation techniques cannot. By training the language model on examples of good game content, it can learn to generate new content that feels coherent, meaningful, and aligned with the desired player experience - things like cooperative gameplay, narrative themes, and environmental storytelling.
The authors demonstrate this approach in the context of a cooperative multiplayer game, where the language model is used to design rewards and challenges that encourage players to work together. This shows how large language models can be a powerful tool for injecting creativity, meaning, and human-centric design into the procedural generation of game content.
Technical Explanation
The paper introduces a novel system called ChatPCG that leverages large language models to guide the procedural generation of content for multiplayer, cooperative games. The core innovation is the use of language models to design rewards that steer the generated content towards promoting collaborative gameplay and meaningful experiences for players.
The authors first provide an overview of procedural content generation (PCG) in games, which is a technique for automatically creating new game elements like levels, challenges, and environments. While PCG can reduce development costs and increase replayability, the generated content can sometimes lack coherence and alignment with player preferences. To address this, the authors propose using large language models as a "creative engine" to imbue the generated content with semantic meaning and narrative context.
The key components of the ChatPCG system are:
-
Reward Modeling: The language model is trained on examples of high-quality game content to learn what types of content are engaging and meaningful for players. This learned knowledge is then used to design rewards that guide the PCG process towards generating content aligned with player preferences.
-
Prompt Engineering: The authors demonstrate how carefully crafted prompts can be used to direct the language model to generate content with specific gameplay and narrative properties, such as cooperative challenges and environmental storytelling.
-
Iterative Refinement: The generated content is evaluated and the rewards are iteratively updated based on feedback, allowing the language model to gradually improve the quality and coherence of the output.
Through experiments in a cooperative multiplayer game scenario, the authors show that ChatPCG can produce content that encourages collaborative gameplay and meaningful player experiences, outperforming traditional PCG techniques. This highlights the potential of large language models to act as powerful "creative engines" for procedural content generation in games.
Critical Analysis
The ChatPCG system represents an interesting and promising application of large language models to the problem of procedural content generation in games. By leveraging the semantic understanding and generation capabilities of these models, the authors demonstrate how game content can be imbued with meaning, narrative context, and alignment with player preferences - overcoming some of the limitations of traditional PCG approaches.
However, the paper also acknowledges several important caveats and limitations that warrant further research:
-
Scalability and Generalization: While the experiments show the effectiveness of ChatPCG in a specific game scenario, it's unclear how well the approach would scale to larger, more complex games or generalize to different game genres and mechanics. Exploring the boundaries of the system's applicability would be an important next step.
-
Evaluation Metrics: The paper relies on qualitative assessments of the generated content's quality and player engagement. Developing more robust, quantitative evaluation metrics would help better understand the system's strengths and weaknesses.
-
Explainability and Transparency: As with many large language model-based systems, the inner workings of ChatPCG can be opaque. Improving the explainability of the system's decision-making process could increase trust and adoption by game developers.
-
Ethical Considerations: The use of large language models in game design raises potential concerns around bias, safety, and alignment with human values. Carefully considering these issues and developing appropriate safeguards would be crucial for real-world deployment.
Overall, the ChatPCG system represents an exciting step towards more intelligent and human-centric procedural content generation in games. By harnessing the power of large language models, the authors have shown how the creative process can be augmented and guided in ways that improve the player experience. However, further research is needed to address the limitations and ensure the responsible development of such systems.
Conclusion
The ChatPCG system introduced in this paper demonstrates the potential of large language models to revolutionize the way procedural content is generated for games. By leveraging the semantic understanding and generation capabilities of these models, the authors have shown how game content can be imbued with meaning, narrative context, and alignment with player preferences - overcoming some of the limitations of traditional PCG approaches.
The key innovation of ChatPCG is its use of language models to design rewards that guide the procedural generation process towards creating content that promotes collaborative gameplay and meaningful player experiences. Through experiments in a cooperative multiplayer game scenario, the authors have shown the effectiveness of this approach, paving the way for more intelligent and human-centric procedural content generation in games.
While the paper acknowledges several important caveats and limitations that warrant further research, the ChatPCG system represents an exciting step towards the integration of large language models into the game development process. By harnessing the creative potential of these powerful AI systems, game designers and developers can unlock new possibilities for player engagement, replayability, and narrative immersion. As the field of AI-assisted game design continues to evolve, the insights and approaches presented in this paper will undoubtedly inspire future innovations and advancements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ChatPCG: Large Language Model-Driven Reward Design for Procedural Content Generation
In-Chang Baek, Tae-Hwa Park, Jin-Ha Noh, Cheong-Mok Bae, Kyung-Joong Kim
Driven by the rapid growth of machine learning, recent advances in game artificial intelligence (AI) have significantly impacted productivity across various gaming genres. Reward design plays a pivotal role in training game AI models, wherein researchers implement concepts of specific reward functions. However, despite the presence of AI, the reward design process predominantly remains in the domain of human experts, as it is heavily reliant on their creativity and engineering skills. Therefore, this paper proposes ChatPCG, a large language model (LLM)-driven reward design framework.It leverages human-level insights, coupled with game expertise, to generate rewards tailored to specific game features automatically. Moreover, ChatPCG is integrated with deep reinforcement learning, demonstrating its potential for multiplayer game content generation tasks. The results suggest that the proposed LLM exhibits the capability to comprehend game mechanics and content generation tasks, enabling tailored content generation for a specified game. This study not only highlights the potential for improving accessibility in content generation but also aims to streamline the game AI development process.
Read more6/19/2024

0
Grammar-based Game Description Generation using Large Language Models
Tsunehiko Tanaka, Edgar Simo-Serra
To lower the barriers to game design development, automated game design, which generates game designs through computational processes, has been explored. In automated game design, machine learning-based techniques such as evolutionary algorithms have achieved success. Benefiting from the remarkable advancements in deep learning, applications in computer vision and natural language processing have progressed in level generation. However, due to the limited amount of data in game design, the application of deep learning has been insufficient for tasks such as game description generation. To pioneer a new approach for handling limited data in automated game design, we focus on the in-context learning of large language models (LLMs). LLMs can capture the features of a task from a few demonstration examples and apply the capabilities acquired during pre-training. We introduce the grammar of game descriptions, which effectively structures the game design space, into the LLMs' reasoning process. Grammar helps LLMs capture the characteristics of the complex task of game description generation. Furthermore, we propose a decoding method that iteratively improves the generated output by leveraging the grammar. Our experiments demonstrate that this approach performs well in generating game descriptions.
Read more7/25/2024
💬
0
Learning Reward for Robot Skills Using Large Language Models via Self-Alignment
Yuwei Zeng, Yao Mu, Lin Shao
Learning reward functions remains the bottleneck to equip a robot with a broad repertoire of skills. Large Language Models (LLM) contain valuable task-related knowledge that can potentially aid in the learning of reward functions. However, the proposed reward function can be imprecise, thus ineffective which requires to be further grounded with environment information. We proposed a method to learn rewards more efficiently in the absence of humans. Our approach consists of two components: We first use the LLM to propose features and parameterization of the reward, then update the parameters through an iterative self-alignment process. In particular, the process minimizes the ranking inconsistency between the LLM and the learnt reward functions based on the execution feedback. The method was validated on 9 tasks across 2 simulation environments. It demonstrates a consistent improvement over training efficacy and efficiency, meanwhile consuming significantly fewer GPT tokens compared to the alternative mutation-based method.
Read more5/17/2024
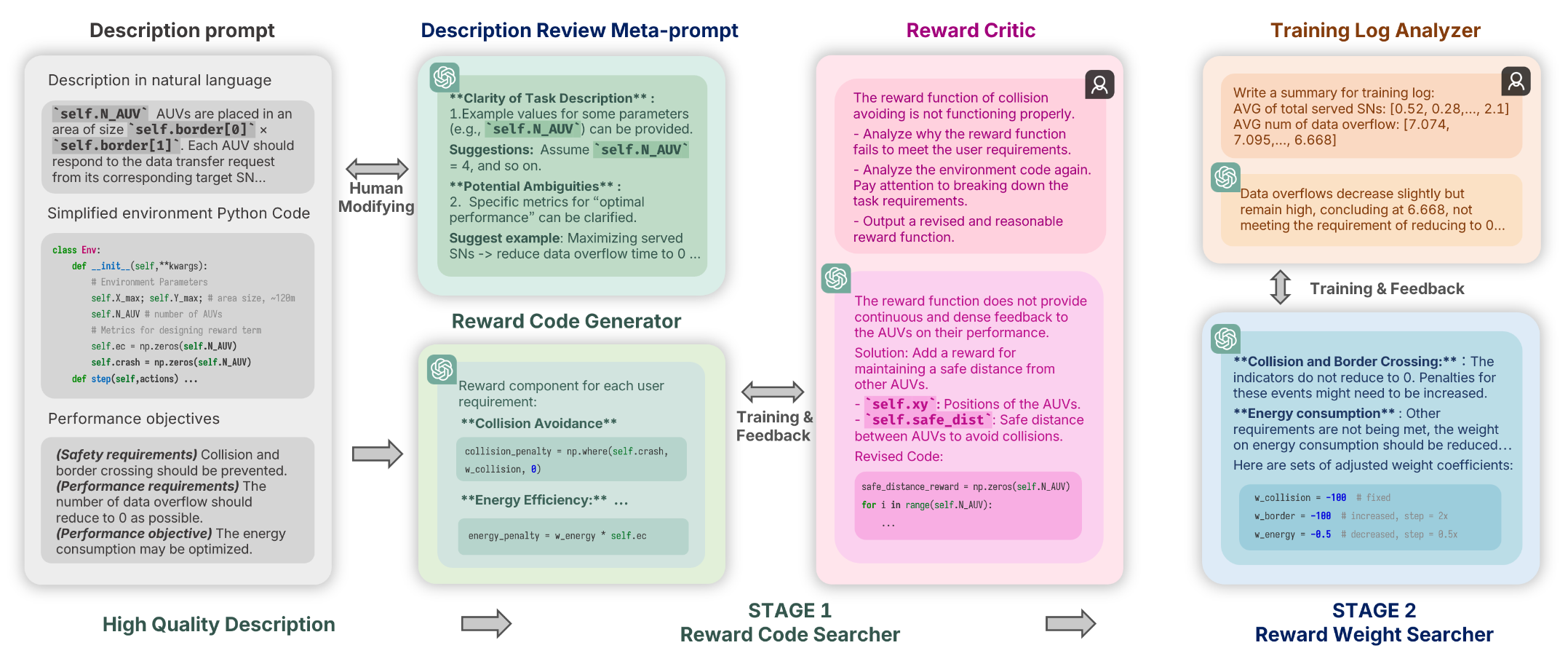
0
Large Language Models as Efficient Reward Function Searchers for Custom-Environment Multi-Objective Reinforcement Learning
Guanwen Xie, Jingzehua Xu, Yiyuan Yang, Shuai Zhang
Leveraging large language models (LLMs) for designing reward functions demonstrates significant potential. However, achieving effective design and improvement of reward functions in reinforcement learning (RL) tasks with complex custom environments and multiple requirements presents considerable challenges. In this paper, we enable LLMs to be effective white-box searchers, highlighting their advanced semantic understanding capabilities. Specifically, we generate reward components for each explicit user requirement and employ the reward critic to identify the correct code form. Then, LLMs assign weights to the reward components to balance their values and iteratively search and optimize these weights based on the context provided by the training log analyzer, while adaptively determining the search step size. We applied the framework to an underwater information collection RL task without direct human feedback or reward examples (zero-shot). The reward critic successfully correct the reward code with only one feedback for each requirement, effectively preventing irreparable errors that can occur when reward function feedback is provided in aggregate. The effective initialization of weights enables the acquisition of different reward functions within the Pareto solution set without weight search. Even in the case where a weight is 100 times off, fewer than four iterations are needed to obtain solutions that meet user requirements. The framework also works well with most prompts utilizing GPT-3.5 Turbo, since it does not require advanced numerical understanding or calculation.
Read more9/5/2024