CherryRec: Enhancing News Recommendation Quality via LLM-driven Framework

0

Sign in to get full access
Overview
- Proposes a framework called CherryRec to enhance news recommendation quality using large language models (LLMs)
- Aims to improve news recommendation by integrating LLMs with collaborative filtering techniques
- Focuses on efficiently fine-tuning LLMs for personalized news recommendation
Plain English Explanation
CherryRec is a framework that uses powerful large language models to improve the quality of news recommendations. The researchers wanted to find a way to combine the strengths of language models with collaborative filtering, which is a common technique for making personalized recommendations.
The key idea is to fine-tune the language model on a news recommendation task, which means adapting it to work well with that specific problem. This allows the model to understand the content and context of news articles better, and make more relevant recommendations for each user. The researchers explored ways to do this efficiently, so the model doesn't require a lot of time or computing power to train.
By leveraging the powerful natural language understanding of LLMs and combining it with collaborative filtering, CherryRec aims to provide users with news recommendations that are more personalized and accurate than what current systems can do. This could help people discover relevant news content more easily and stay informed on topics they care about.
Technical Explanation
The CherryRec framework integrates large language models with collaborative filtering to enhance news recommendation quality. The researchers propose an efficient fine-tuning approach that adapts the LLM to the news recommendation task, rather than training the language model from scratch.
The key components of CherryRec include:
- News Corpus Encoder: This module uses the LLM to encode news articles into contextual representations, capturing the semantic and topical information.
- User-Item Interaction Encoder: This encodes the user-news interaction history using a collaborative filtering module, modeling user preferences.
- Recommendation Module: This combines the article and user representations to generate personalized news recommendations for each user.
The researchers explore different fine-tuning strategies to efficiently adapt the LLM to the news recommendation task, including prompt-based tuning and end-to-end fine-tuning. This allows the model to leverage the rich language understanding of the LLM while maintaining high recommendation performance.
Experiments on real-world news datasets demonstrate that CherryRec outperforms state-of-the-art news recommendation methods, highlighting the benefits of integrating LLMs with collaborative filtering techniques.
Critical Analysis
The CherryRec framework presents a novel approach to news recommendation by effectively combining the strengths of large language models and collaborative filtering. The researchers have carefully designed the system to enable efficient fine-tuning of the LLM, which is crucial for practical deployment.
One potential limitation is the reliance on user-news interaction data, which may be sparse or biased in some real-world scenarios. The researchers acknowledge this and suggest exploring ways to incorporate additional signals, such as news category descriptions, to enrich the user and item representations.
Additionally, the paper does not delve into the interpretability or explainability of the recommendations generated by CherryRec. As language models can sometimes be opaque, it would be valuable to investigate methods to provide users with more transparency into the reasoning behind the recommended news articles.
Overall, the CherryRec framework represents a promising step towards enhancing personalized recommendation via large language models. The innovative integration of LLMs and collaborative filtering, along with the efficient fine-tuning approach, could inspire further research in this direction and lead to more engaging and informative news recommendation experiences for users.
Conclusion
The CherryRec framework demonstrates how large language models can be effectively leveraged to improve news recommendation quality. By integrating LLMs with collaborative filtering techniques, the system is able to generate personalized and accurate news recommendations for users. The efficient fine-tuning approach ensures that the model can be deployed in practical settings without requiring excessive computational resources.
This work showcases the potential of combining the rich language understanding of LLMs with the user-item interaction modeling of collaborative filtering. As news consumption and information discovery become increasingly important in our digital world, frameworks like CherryRec could play a crucial role in helping people stay informed and engaged with relevant and meaningful content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CherryRec: Enhancing News Recommendation Quality via LLM-driven Framework
Shaohuang Wang, Lun Wang, Yunhan Bu, Tianwei Huang
Large Language Models (LLMs) have achieved remarkable progress in language understanding and generation. Custom LLMs leveraging textual features have been applied to recommendation systems, demonstrating improvements across various recommendation scenarios. However, most existing methods perform untrained recommendation based on pre-trained knowledge (e.g., movie recommendation), and the auto-regressive generation of LLMs leads to slow inference speeds, making them less effective in real-time recommendations.To address this, we propose a framework for news recommendation using LLMs, named textit{CherryRec}, which ensures the quality of recommendations while accelerating the recommendation process. Specifically, we employ a Knowledge-aware News Rapid Selector to retrieve candidate options based on the user's interaction history. The history and retrieved items are then input as text into a fine-tuned LLM, the Content-aware News Llm Evaluator, designed to enhance news recommendation capabilities. Finally, the Value-aware News Scorer integrates the scores to compute the CherryRec Score, which serves as the basis for the final recommendation.We validate the effectiveness of the proposed framework by comparing it with state-of-the-art baseline methods on benchmark datasets. Our experimental results consistently show that CherryRec outperforms the baselines in both recommendation performance and efficiency.The project resource can be accessed at: url{https://github.com/xxxxxx}
Read more6/19/2024
0
Large Language Model Driven Recommendation
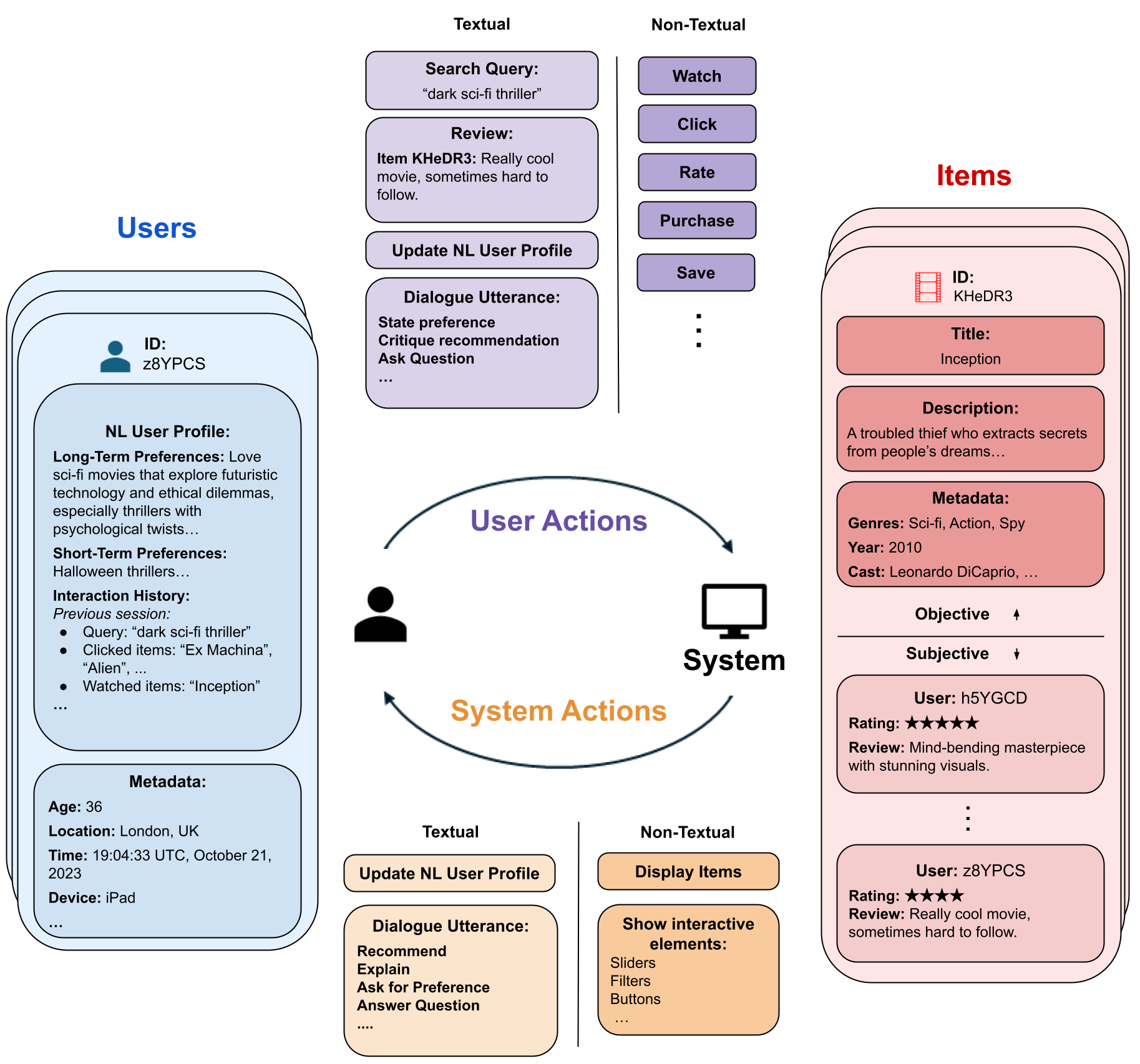
Anton Korikov, Scott Sanner, Yashar Deldjoo, Zhankui He, Julian McAuley, Arnau Ramisa, Rene Vidal, Mahesh Sathiamoorthy, Atoosa Kasrizadeh, Silvia Milano, Francesco Ricci
While previous chapters focused on recommendation systems (RSs) based on standardized, non-verbal user feedback such as purchases, views, and clicks -- the advent of LLMs has unlocked the use of natural language (NL) interactions for recommendation. This chapter discusses how LLMs' abilities for general NL reasoning present novel opportunities to build highly personalized RSs -- which can effectively connect nuanced and diverse user preferences to items, potentially via interactive dialogues. To begin this discussion, we first present a taxonomy of the key data sources for language-driven recommendation, covering item descriptions, user-system interactions, and user profiles. We then proceed to fundamental techniques for LLM recommendation, reviewing the use of encoder-only and autoregressive LLM recommendation in both tuned and untuned settings. Afterwards, we move to multi-module recommendation architectures in which LLMs interact with components such as retrievers and RSs in multi-stage pipelines. This brings us to architectures for conversational recommender systems (CRSs), in which LLMs facilitate multi-turn dialogues where each turn presents an opportunity not only to make recommendations, but also to engage with the user in interactive preference elicitation, critiquing, and question-answering.
Read more8/21/2024
💬
1
A Survey on Large Language Models for Recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong Chen
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
Read more6/19/2024
💬
0
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
Read more4/3/2024