CHG Shapley: Efficient Data Valuation and Selection towards Trustworthy Machine Learning

0

Sign in to get full access
Overview
- This paper proposes a new method called CHG Shapley for efficient data valuation and selection towards trustworthy machine learning.
- CHG Shapley builds on the Shapley value framework, a well-established concept in cooperative game theory, to quantify the importance of each data point in a dataset.
- The method aims to address the limitations of existing data valuation approaches, such as Rethinking Data Shapley for Data Selection Tasks and Data Valuation by Leveraging Global and Local Statistical Information, which can be computationally expensive or make simplifying assumptions.
Plain English Explanation
The paper introduces a new way to determine the value of individual data points in a dataset, which can be useful for tasks like selecting the most important data to train a machine learning model.
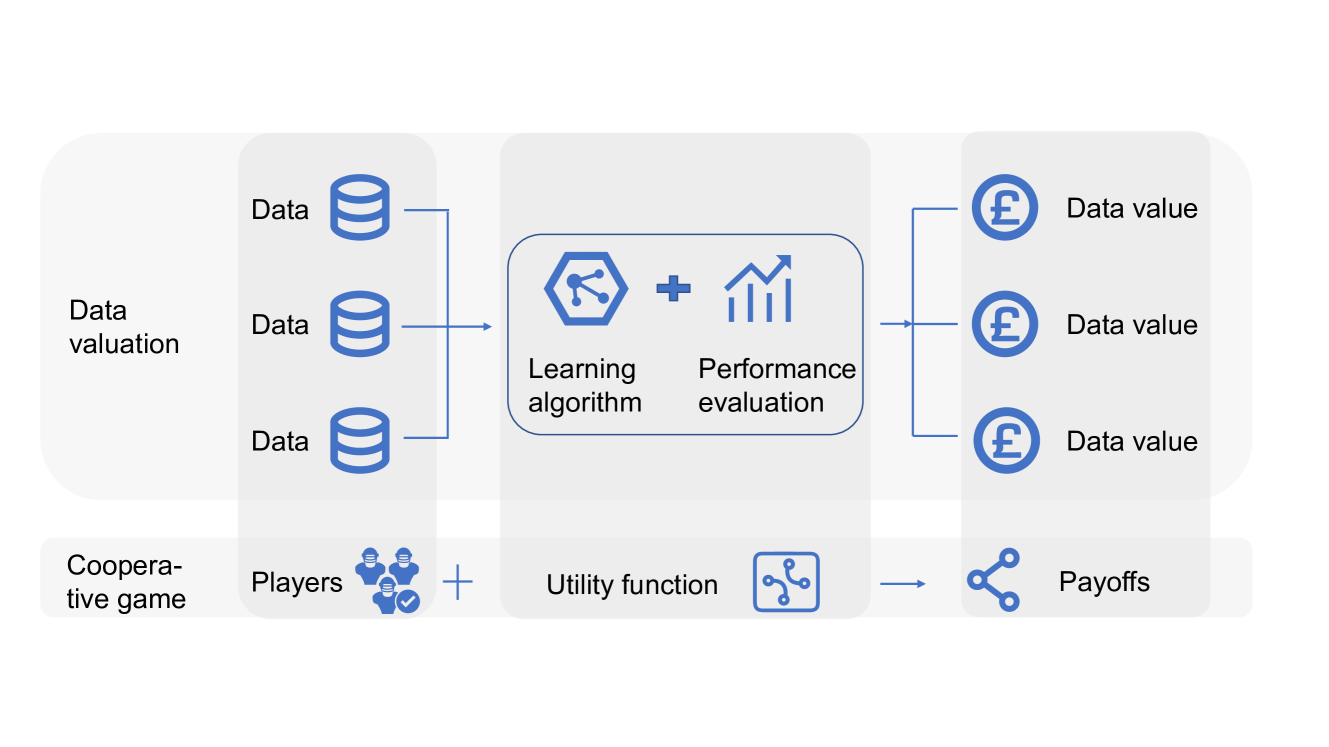
The key idea is to use a concept called the Shapley value, which was originally developed in the field of game theory. The Shapley value quantifies how much each "player" (in this case, a data point) contributes to the overall "game" (the performance of the machine learning model).
By efficiently computing the Shapley values for each data point, the CHG Shapley method can identify the most valuable data points without having to test every possible combination, which would be computationally prohibitive. This makes the data valuation process more practical and scalable compared to some previous approaches.
The authors show that CHG Shapley outperforms other data valuation methods in terms of accuracy and computational efficiency, and demonstrate its usefulness for tasks like selecting a subset of data to train a model or identifying which data points are most important for the model's performance.
Technical Explanation
The CHG Shapley method builds on the concept of Shapley values, which were originally developed in cooperative game theory to quantify the contribution of each player to the overall outcome of the game.
To apply this to machine learning, the authors treat each data point as a "player" and the overall performance of the machine learning model as the "game". The Shapley value of a data point then represents its importance or contribution to the model's performance.
Calculating the exact Shapley values can be computationally expensive, so the authors propose an efficient approximation algorithm called CHG Shapley. This algorithm leverages fast Shapley value estimation and energy-based model techniques to provide accurate data valuations while significantly reducing the computational cost.
The paper demonstrates the effectiveness of CHG Shapley through experiments on several real-world datasets and machine learning tasks, including image classification, text classification, and anomaly detection. The results show that CHG Shapley outperforms other data valuation methods in terms of accuracy and efficiency, and can be useful for tasks like instance-level algorithmic fairness.
Critical Analysis
The paper introduces a novel and efficient approach to data valuation, which is an important problem in machine learning with applications in areas like dataset curation, model interpretability, and fairness. The authors have carefully designed the CHG Shapley method to address the limitations of previous approaches, and the experimental results demonstrate its advantages.
However, the paper does not discuss certain potential limitations or caveats of the proposed method. For example, the authors do not explore how CHG Shapley might perform in settings with highly correlated or noisy data, or how sensitive the results are to the choice of hyperparameters.
Additionally, while the paper highlights the computational efficiency of CHG Shapley, it would be useful to have a more detailed analysis of the scalability of the method, especially as the size of the dataset or the complexity of the machine learning model increases.
Further research could also investigate the interpretability and explainability of the data valuations produced by CHG Shapley, and explore its potential applications in areas like model debugging, interactive machine learning, and data-centric AI development.
Conclusion
The CHG Shapley method proposed in this paper offers a promising approach to efficient data valuation and selection for machine learning. By leveraging the Shapley value framework and various algorithmic techniques, the authors have developed a scalable and accurate method that can help identify the most valuable data points in a dataset.
The potential applications of CHG Shapley are wide-ranging, from dataset curation and model interpretability to instance-level algorithmic fairness. As machine learning systems become more complex and data-hungry, tools like CHG Shapley will be increasingly important for ensuring the trustworthiness and robustness of these systems.
Overall, this paper makes a valuable contribution to the field of machine learning by advancing the state of the art in data valuation and selection, and opens up new avenues for future research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CHG Shapley: Efficient Data Valuation and Selection towards Trustworthy Machine Learning
Huaiguang Cai
Understanding the decision-making process of machine learning models is crucial for ensuring trustworthy machine learning. Data Shapley, a landmark study on data valuation, advances this understanding by assessing the contribution of each datum to model accuracy. However, the resource-intensive and time-consuming nature of multiple model retraining poses challenges for applying Data Shapley to large datasets. To address this, we propose the CHG (Conduct of Hardness and Gradient) score, which approximates the utility of each data subset on model accuracy during a single model training. By deriving the closed-form expression of the Shapley value for each data point under the CHG score utility function, we reduce the computational complexity to the equivalent of a single model retraining, an exponential improvement over existing methods. Additionally, we employ CHG Shapley for real-time data selection, demonstrating its effectiveness in identifying high-value and noisy data. CHG Shapley facilitates trustworthy model training through efficient data valuation, introducing a novel data-centric perspective on trustworthy machine learning.
Read more6/19/2024
📊
0
Rethinking Data Shapley for Data Selection Tasks: Misleads and Merits
Jiachen T. Wang, Tianji Yang, James Zou, Yongchan Kwon, Ruoxi Jia
Data Shapley provides a principled approach to data valuation and plays a crucial role in data-centric machine learning (ML) research. Data selection is considered a standard application of Data Shapley. However, its data selection performance has shown to be inconsistent across settings in the literature. This study aims to deepen our understanding of this phenomenon. We introduce a hypothesis testing framework and show that Data Shapley's performance can be no better than random selection without specific constraints on utility functions. We identify a class of utility functions, monotonically transformed modular functions, within which Data Shapley optimally selects data. Based on this insight, we propose a heuristic for predicting Data Shapley's effectiveness in data selection tasks. Our experiments corroborate these findings, adding new insights into when Data Shapley may or may not succeed.
Read more5/8/2024
🏷️
0
DU-Shapley: A Shapley Value Proxy for Efficient Dataset Valuation
Felipe Garrido-Lucero, Benjamin Heymann, Maxime Vono, Patrick Loiseau, Vianney Perchet
We consider the dataset valuation problem, that is, the problem of quantifying the incremental gain, to some relevant pre-defined utility of a machine learning task, of aggregating an individual dataset to others. The Shapley value is a natural tool to perform dataset valuation due to its formal axiomatic justification, which can be combined with Monte Carlo integration to overcome the computational tractability challenges. Such generic approximation methods, however, remain expensive in some cases. In this paper, we exploit the knowledge about the structure of the dataset valuation problem to devise more efficient Shapley value estimators. We propose a novel approximation, referred to as discrete uniform Shapley, which is expressed as an expectation under a discrete uniform distribution with support of reasonable size. We justify the relevancy of the proposed framework via asymptotic and non-asymptotic theoretical guarantees and illustrate its benefits via an extensive set of numerical experiments.
Read more6/19/2024
0
Uncertainty Quantification of Data Shapley via Statistical Inference
Mengmeng Wu, Zhihong Liu, Xiang Li, Ruoxi Jia, Xiangyu Chang
As data plays an increasingly pivotal role in decision-making, the emergence of data markets underscores the growing importance of data valuation. Within the machine learning landscape, Data Shapley stands out as a widely embraced method for data valuation. However, a limitation of Data Shapley is its assumption of a fixed dataset, contrasting with the dynamic nature of real-world applications where data constantly evolves and expands. This paper establishes the relationship between Data Shapley and infinite-order U-statistics and addresses this limitation by quantifying the uncertainty of Data Shapley with changes in data distribution from the perspective of U-statistics. We make statistical inferences on data valuation to obtain confidence intervals for the estimations. We construct two different algorithms to estimate this uncertainty and provide recommendations for their applicable situations. We also conduct a series of experiments on various datasets to verify asymptotic normality and propose a practical trading scenario enabled by this method.
Read more7/30/2024