Chinese MentalBERT: Domain-Adaptive Pre-training on Social Media for Chinese Mental Health Text Analysis

0
👨🏫
Sign in to get full access
Overview
- This research paper focuses on developing a specialized language model for psychological text analysis by leveraging a large dataset from Chinese social media platforms.
- The researchers aim to address the lack of pre-trained models tailored for specialized domains like psychology, which is essential for efficient analysis of the vast amounts of psychological data generated daily, particularly on social media.
- The key aspects of the research include:
- Creating a comprehensive dataset of 3.36 million text entries from Chinese social media platforms, enriched with publicly available datasets.
- Integrating psychological lexicons into the pre-training masking mechanism to enhance the model's applicability to psychological text analysis.
- Adapting an existing Chinese language model through further training to develop a specialized model for the psychological domain.
- Evaluating the model's performance on various public datasets and conducting qualitative comparisons.
Plain English Explanation
Psychological issues are becoming increasingly prevalent, with social media serving as a key outlet for people to share their feelings. This generates a vast amount of data on a daily basis, and there is a recognized need for efficient analysis models. While pre-trained language models have proven effective in various domains, there is a lack of specialized models for psychology.
To address this, the researchers have created a large dataset of over 3 million text entries from Chinese social media platforms, enriched with publicly available datasets. They then integrated psychological lexicons, or dictionaries of psychological terms, into the pre-training process of the language model. This helps the model better understand and analyze psychological text.
Building on an existing Chinese language model, the researchers further trained the model to specialize in the psychological domain. They then evaluated the model's performance on various public datasets and found that it outperformed other models. In a qualitative comparison, the model also provided psychologically relevant predictions when presented with masked sentences.
While the dataset will not be made publicly available due to privacy concerns, the researchers have made the pre-trained models and code accessible to the community.
Technical Explanation
The researchers started by collecting a massive dataset of 3.36 million text entries from Chinese social media platforms and enriching it with publicly available datasets. This comprehensive dataset was aimed at addressing the lack of pre-trained models tailored for specialized domains like psychology.
To enhance the model's applicability to psychological text analysis, the researchers integrated psychological lexicons into the pre-training masking mechanism. This means they incorporated dictionaries of psychological terms and concepts into the process of randomly masking and predicting words during the pre-training of the language model.
Building on an existing Chinese language model, the researchers then performed adaptive training to develop a specialized model for the psychological domain. This involves further training the base model on the psychological dataset to fine-tune its performance for this specific task.
The researchers evaluated their model's performance across six public datasets, including mental health prediction tasks and large language model benchmarks. Their model demonstrated improvements compared to eight other models, showcasing its superior capabilities in psychological text analysis.
Additionally, in a qualitative comparison experiment, the researchers found that their model provided psychologically relevant predictions when presented with masked sentences, further highlighting its suitability for this specialized domain.
Critical Analysis
While the researchers have made significant strides in developing a specialized language model for psychological text analysis, there are a few potential limitations and areas for further research:
-
Dataset privacy: The researchers have not made the dataset publicly available due to concerns over data privacy. This may limit the ability of other researchers to validate or build upon the findings.
-
Cross-cultural applicability: The dataset and model were primarily focused on the Chinese context. It would be valuable to explore the model's performance and applicability in other cultural and linguistic contexts, such as adapting it for other languages.
-
Ethical considerations: When working with sensitive data related to mental health and psychological well-being, it is crucial to address potential ethical concerns, such as the responsible use of the model and the protection of individual privacy.
-
Generalizability: While the model demonstrated promising results on the evaluated datasets, it would be beneficial to assess its performance on a wider range of psychological text analysis tasks to ensure its generalizability and robustness.
Conclusion
This research paper presents a significant step towards addressing the lack of specialized language models for psychological text analysis. By creating a large, comprehensive dataset and integrating psychological lexicons into the pre-training process, the researchers have developed a model that outperforms other approaches in this specialized domain.
The potential implications of this work are far-reaching, as it could enable more efficient and accurate analysis of the vast amounts of psychological data generated on social media platforms. This could ultimately lead to better understanding of mental health trends, earlier identification of crisis situations, and more targeted interventions.
While the dataset privacy limitations and the need for further cross-cultural evaluations present ongoing challenges, the researchers have made their pre-trained models and code publicly available, allowing the community to build upon their work and explore new applications in the field of mental health prediction and analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Chinese MentalBERT: Domain-Adaptive Pre-training on Social Media for Chinese Mental Health Text Analysis
Wei Zhai, Hongzhi Qi, Qing Zhao, Jianqiang Li, Ziqi Wang, Han Wang, Bing Xiang Yang, Guanghui Fu
In the current environment, psychological issues are prevalent and widespread, with social media serving as a key outlet for individuals to share their feelings. This results in the generation of vast quantities of data daily, where negative emotions have the potential to precipitate crisis situations. There is a recognized need for models capable of efficient analysis. While pre-trained language models have demonstrated their effectiveness broadly, there's a noticeable gap in pre-trained models tailored for specialized domains like psychology. To address this, we have collected a huge dataset from Chinese social media platforms and enriched it with publicly available datasets to create a comprehensive database encompassing 3.36 million text entries. To enhance the model's applicability to psychological text analysis, we integrated psychological lexicons into the pre-training masking mechanism. Building on an existing Chinese language model, we performed adaptive training to develop a model specialized for the psychological domain. We evaluated our model's performance across six public datasets, where it demonstrated improvements compared to eight other models. Additionally, in the qualitative comparison experiment, our model provided psychologically relevant predictions given the masked sentences. Due to concerns regarding data privacy, the dataset will not be made publicly available. However, we have made the pre-trained models and codes publicly accessible to the community via: https://github.com/zwzzzQAQ/Chinese-MentalBERT.
Read more6/13/2024

0
CASE: Curricular Data Pre-training for Building Generative and Discriminative Assistive Psychology Expert Models
Sarthak Harne, Monjoy Narayan Choudhury, Madhav Rao, TK Srikanth, Seema Mehrotra, Apoorva Vashisht, Aarushi Basu, Manjit Sodhi
The limited availability of psychologists necessitates efficient identification of individuals requiring urgent mental healthcare. This study explores the use of Natural Language Processing (NLP) pipelines to analyze text data from online mental health forums used for consultations. By analyzing forum posts, these pipelines can flag users who may require immediate professional attention. A crucial challenge in this domain is data privacy and scarcity. To address this, we propose utilizing readily available curricular texts used in institutes specializing in mental health for pre-training the NLP pipelines. This helps us mimic the training process of a psychologist. Our work presents CASE-BERT that flags potential mental health disorders based on forum text. CASE-BERT demonstrates superior performance compared to existing methods, achieving an f1 score of 0.91 for Depression and 0.88 for Anxiety, two of the most commonly reported mental health disorders. Our code is publicly available.
Read more6/18/2024
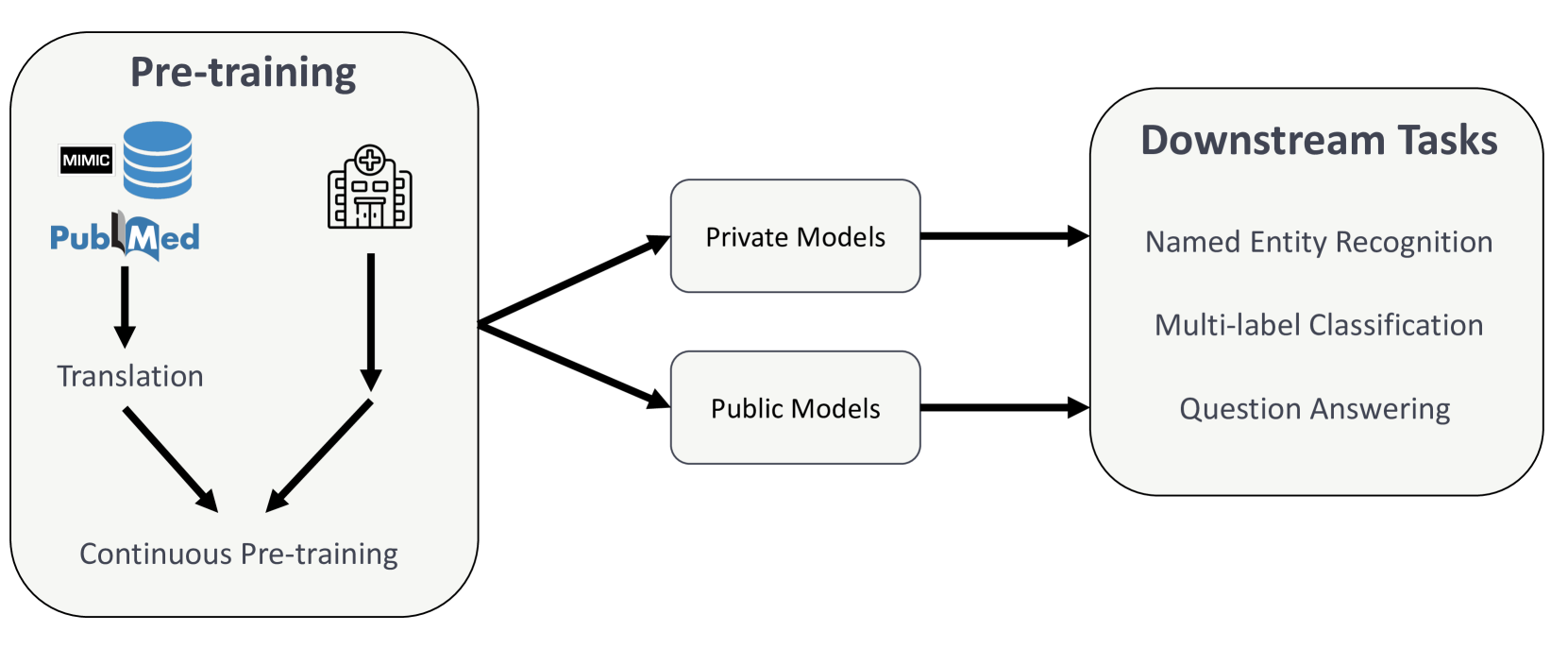
0
Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
Ahmad Idrissi-Yaghir, Amin Dada, Henning Schafer, Kamyar Arzideh, Giulia Baldini, Jan Trienes, Max Hasin, Jeanette Bewersdorff, Cynthia S. Schmidt, Marie Bauer, Kaleb E. Smith, Jiang Bian, Yonghui Wu, Jorg Schlotterer, Torsten Zesch, Peter A. Horn, Christin Seifert, Felix Nensa, Jens Kleesiek, Christoph M. Friedrich
Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
Read more5/9/2024

0
Domain-Specific Pretraining of Language Models: A Comparative Study in the Medical Field
Tobias Kerner
There are many cases where LLMs are used for specific tasks in a single domain. These usually require less general, but more domain-specific knowledge. Highly capable, general-purpose state-of-the-art language models like GPT-4 or Claude-3-opus can often be used for such tasks, but they are very large and cannot be run locally, even if they were not proprietary. This can be a problem when working with sensitive data. This paper focuses on domain-specific and mixed-domain pretraining as potentially more efficient methods than general pretraining for specialized language models. We will take a look at work related to domain-specific pretraining, specifically in the medical area, and compare benchmark results of specialized language models to general-purpose language models.
Read more7/30/2024