CIC: A framework for Culturally-aware Image Captioning
2402.05374
0
0
🖼️
Abstract
Image Captioning generates descriptive sentences from images using Vision-Language Pre-trained models (VLPs) such as BLIP, which has improved greatly. However, current methods lack the generation of detailed descriptive captions for the cultural elements depicted in the images, such as the traditional clothing worn by people from Asian cultural groups. In this paper, we propose a new framework, textbf{Culturally-aware Image Captioning (CIC)}, that generates captions and describes cultural elements extracted from cultural visual elements in images representing cultures. Inspired by methods combining visual modality and Large Language Models (LLMs) through appropriate prompts, our framework (1) generates questions based on cultural categories from images, (2) extracts cultural visual elements from Visual Question Answering (VQA) using generated questions, and (3) generates culturally-aware captions using LLMs with the prompts. Our human evaluation conducted on 45 participants from 4 different cultural groups with a high understanding of the corresponding culture shows that our proposed framework generates more culturally descriptive captions when compared to the image captioning baseline based on VLPs. Our code and dataset will be made publicly available upon acceptance.
Create account to get full access
Overview
- This paper proposes a new framework called "Culturally-aware Image Captioning (CIC)" that generates detailed captions describing the cultural elements present in images.
- Current image captioning methods using Vision-Language Pre-trained models (VLPs) like BLIP lack the ability to describe cultural aspects in images, especially those representing diverse cultural groups.
- The CIC framework generates questions based on cultural categories, extracts cultural visual elements using Visual Question Answering (VQA), and then generates culturally-aware captions using Large Language Models (LLMs) with appropriate prompts.
- This approach is evaluated through a human study with 45 participants from 4 different cultural backgrounds, showing that CIC generates more culturally descriptive captions compared to a baseline image captioning method.
Plain English Explanation
The paper presents a new way to describe the cultural elements in images using a framework called "Culturally-aware Image Captioning (CIC)". Current image captioning systems, which use advanced AI models like VLPs, are good at generating general descriptions of images. However, they often miss or fail to properly describe the cultural aspects, such as traditional clothing or customs, especially when the images represent diverse cultures.
The CIC framework addresses this by taking a few key steps. First, it generates questions about the cultural categories present in the image. Then, it uses Visual Question Answering (VQA) to extract the specific cultural visual elements from the image. Finally, it generates detailed captions that describe these cultural elements using large language models (LLMs) and appropriate prompts.
The researchers evaluated this approach by having 45 people from 4 different cultural backgrounds review the captions. The results showed that the CIC framework produced captions that were more culturally descriptive compared to a baseline image captioning method.
Technical Explanation
The paper introduces a new framework called "Culturally-aware Image Captioning (CIC)" that aims to generate detailed captions describing the cultural elements present in images. This is an important advancement over existing image captioning methods based on Vision-Language Pre-trained models (VLPs), which often lack the ability to accurately describe cultural aspects, especially in images representing diverse cultural groups.
The CIC framework consists of three key steps:
-
Question Generation: The framework first generates questions based on cultural categories that may be present in the input image.
-
Cultural Visual Element Extraction: Using the generated questions, the framework then extracts the specific cultural visual elements from the image through Visual Question Answering (VQA).
-
Culturally-aware Caption Generation: Finally, the framework generates detailed captions that describe the extracted cultural visual elements using Large Language Models (LLMs) and appropriate prompts.
The authors evaluate their proposed CIC framework through a human study involving 45 participants from 4 different cultural backgrounds. The results show that the CIC framework generates more culturally descriptive captions compared to a baseline image captioning method based on VLPs.
Critical Analysis
The paper presents a novel and promising approach to generating more culturally-aware captions for images, which is an important step in making image captioning systems more inclusive and representative of diverse cultural contexts.
One potential limitation of the approach is that it relies on the accuracy and completeness of the cultural visual element extraction step, which is based on VQA. If the VQA model fails to correctly identify or extract all the relevant cultural elements, the quality of the final captions may be impacted. The authors could potentially explore ways to further improve the VQA component, perhaps by incorporating additional cultural knowledge or visual fact-checking techniques.
Additionally, the evaluation of the CIC framework was limited to a relatively small sample size of 45 participants from 4 cultural groups. While the results are promising, a larger-scale evaluation with more diverse cultural backgrounds would help validate the generalizability of the approach.
Overall, the CIC framework represents an important step forward in making image captioning systems more culturally-aware and inclusive. Further research to address the identified limitations and explore ways to make the approach more robust and scalable would be valuable contributions to the field.
Conclusion
This paper introduces a new framework called "Culturally-aware Image Captioning (CIC)" that generates detailed captions describing the cultural elements present in images. The CIC framework addresses a key limitation of existing image captioning methods based on Vision-Language Pre-trained models (VLPs), which often fail to properly capture and describe the cultural aspects of images, especially those representing diverse cultural groups.
The CIC framework generates questions based on cultural categories, extracts cultural visual elements using Visual Question Answering (VQA), and then generates culturally-aware captions using Large Language Models (LLMs) with appropriate prompts. The evaluation of the CIC framework through a human study with 45 participants from 4 different cultural backgrounds shows that it generates more culturally descriptive captions compared to a baseline image captioning method.
This research represents an important step towards making image captioning systems more inclusive and representative of diverse cultural contexts. Further improvements to the VQA component and larger-scale evaluations could help strengthen the CIC framework and pave the way for more culturally-aware image understanding and description systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

How Culturally Aware are Vision-Language Models?
Olena Burda-Lassen, Aman Chadha, Shashank Goswami, Vinija Jain
0
0
An image is often said to be worth a thousand words, and certain images can tell rich and insightful stories. Can these stories be told via image captioning? Images from folklore genres, such as mythology, folk dance, cultural signs, and symbols, are vital to every culture. Our research compares the performance of four popular vision-language models (GPT-4V, Gemini Pro Vision, LLaVA, and OpenFlamingo) in identifying culturally specific information in such images and creating accurate and culturally sensitive image captions. We also propose a new evaluation metric, Cultural Awareness Score (CAS), dedicated to measuring the degree of cultural awareness in image captions. We provide a dataset MOSAIC-1.5k, labeled with ground truth for images containing cultural background and context, as well as a labeled dataset with assigned Cultural Awareness Scores that can be used with unseen data. Creating culturally appropriate image captions is valuable for scientific research and can be beneficial for many practical applications. We envision that our work will promote a deeper integration of cultural sensitivity in AI applications worldwide. By making the dataset and Cultural Awareness Score available to the public, we aim to facilitate further research in this area, encouraging the development of more culturally aware AI systems that respect and celebrate global diversity.
5/29/2024

A Picture is Worth More Than 77 Text Tokens: Evaluating CLIP-Style Models on Dense Captions
Jack Urbanek, Florian Bordes, Pietro Astolfi, Mary Williamson, Vasu Sharma, Adriana Romero-Soriano
0
0
Curation methods for massive vision-language datasets trade off between dataset size and quality. However, even the highest quality of available curated captions are far too short to capture the rich visual detail in an image. To show the value of dense and highly-aligned image-text pairs, we collect the Densely Captioned Images (DCI) dataset, containing 7805 natural images human-annotated with mask-aligned descriptions averaging above 1000 words each. With precise and reliable captions associated with specific parts of an image, we can evaluate vision-language models' (VLMs) understanding of image content with a novel task that matches each caption with its corresponding subcrop. As current models are often limited to 77 text tokens, we also introduce a summarized version (sDCI) in which each caption length is limited. We show that modern techniques that make progress on standard benchmarks do not correspond with significant improvement on our sDCI based benchmark. Lastly, we finetune CLIP using sDCI and show significant improvements over the baseline despite a small training set. By releasing the first human annotated dense image captioning dataset, we hope to enable the development of new benchmarks or fine-tuning recipes for the next generation of VLMs to come.
6/18/2024
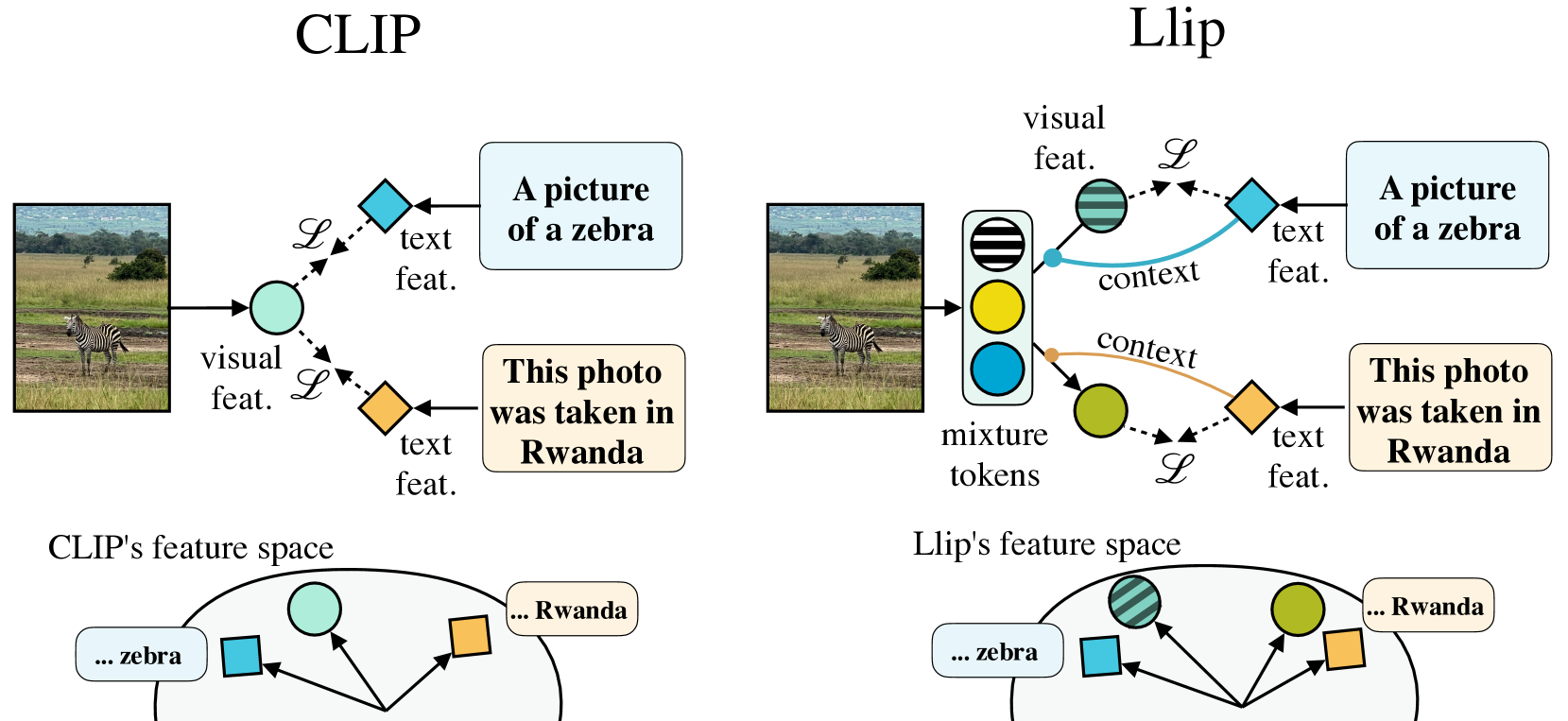
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024

Image Textualization: An Automatic Framework for Creating Accurate and Detailed Image Descriptions
Renjie Pi, Jianshu Zhang, Jipeng Zhang, Rui Pan, Zhekai Chen, Tong Zhang
0
0
Image description datasets play a crucial role in the advancement of various applications such as image understanding, text-to-image generation, and text-image retrieval. Currently, image description datasets primarily originate from two sources. One source is the scraping of image-text pairs from the web. Despite their abundance, these descriptions are often of low quality and noisy. Another is through human labeling. Datasets such as COCO are generally very short and lack details. Although detailed image descriptions can be annotated by humans, the high annotation cost limits the feasibility. These limitations underscore the need for more efficient and scalable methods to generate accurate and detailed image descriptions. In this paper, we propose an innovative framework termed Image Textualization (IT), which automatically produces high-quality image descriptions by leveraging existing multi-modal large language models (MLLMs) and multiple vision expert models in a collaborative manner, which maximally convert the visual information into text. To address the current lack of benchmarks for detailed descriptions, we propose several benchmarks for comprehensive evaluation, which verifies the quality of image descriptions created by our framework. Furthermore, we show that LLaVA-7B, benefiting from training on IT-curated descriptions, acquire improved capability to generate richer image descriptions, substantially increasing the length and detail of their output with less hallucination.
6/12/2024