Enhancing Visual Question Answering through Question-Driven Image Captions as Prompts
2404.08589
0
0

Abstract
Visual question answering (VQA) is known as an AI-complete task as it requires understanding, reasoning, and inferring about the vision and the language content. Over the past few years, numerous neural architectures have been suggested for the VQA problem. However, achieving success in zero-shot VQA remains a challenge due to its requirement for advanced generalization and reasoning skills. This study explores the impact of incorporating image captioning as an intermediary process within the VQA pipeline. Specifically, we explore the efficacy of utilizing image captions instead of images and leveraging large language models (LLMs) to establish a zero-shot setting. Since image captioning is the most crucial step in this process, we compare the impact of state-of-the-art image captioning models on VQA performance across various question types in terms of structure and semantics. We propose a straightforward and efficient question-driven image captioning approach within this pipeline to transfer contextual information into the question-answering (QA) model. This method involves extracting keywords from the question, generating a caption for each image-question pair using the keywords, and incorporating the question-driven caption into the LLM prompt. We evaluate the efficacy of using general-purpose and question-driven image captions in the VQA pipeline. Our study highlights the potential of employing image captions and harnessing the capabilities of LLMs to achieve competitive performance on GQA under the zero-shot setting. Our code is available at url{https://github.com/ovguyo/captions-in-VQA}.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores a novel approach to enhancing visual question answering (VQA) through the use of question-driven image captions as prompts.
- The researchers propose a framework that generates image captions based on the given question, which are then used to augment the VQA model's input, leading to improved performance.
- The paper also investigates the impact of different caption generation strategies and their integration with the VQA model.
Plain English Explanation
Visual question answering (VQA) is a task where a computer system is shown an image and asked a question about it, and the system has to provide the correct answer. This paper presents a new way to improve the performance of VQA systems.
The key idea is to use the question being asked about the image to generate a relevant caption for that image. For example, if the question is "What color is the car in the image?", the system would generate a caption like "There is a red car parked on the street." This caption, which is tailored to the specific question, is then used to supplement the information the VQA system has about the image, helping it answer the question more accurately.
The researchers explore different techniques for generating these question-driven captions and integrating them with the VQA model. Their results show that this approach leads to significant improvements in the VQA system's performance, compared to using standard image captions or no captions at all.
This work is significant because it demonstrates a novel way to leverage additional information, in the form of question-specific image captions, to enhance the capabilities of VQA systems. The approach could potentially be applied to other tasks that involve understanding images and answering questions about them, such as Design as Desired: Utilizing Visual Question Answering, Image Captioning in News Report Scenario, or EVCAP: Retrieval-Augmented Image Captioning with External Visual Concepts.
Technical Explanation
The researchers propose a framework that generates question-driven image captions and integrates them with a VQA model to improve its performance. The framework consists of two main components:
-
Caption Generator: This module takes the question about an image as input and generates a relevant caption for that image. The researchers experiment with different caption generation strategies, including a retrieval-based approach that selects the most relevant caption from a pre-existing caption dataset, and a generative approach that uses a language model to generate a new caption.
-
VQA Model: This is the core VQA model, which takes the image and the question as input and produces an answer. The researchers integrate the question-driven captions generated by the first module into the VQA model's input, either by concatenating the caption with the image features or by using the caption to guide the attention mechanism within the VQA model.
The researchers evaluate their approach on standard VQA datasets and compare it to various baselines, including VQA models that use standard image captions or no captions at all. Their results show that the question-driven captions significantly improve the VQA model's performance, outperforming the baselines by a substantial margin.
The researchers also conduct ablation studies to understand the impact of different caption generation strategies and integration methods with the VQA model. They find that the generative approach to caption generation, combined with a caption-guided attention mechanism in the VQA model, yields the best results.
Critical Analysis
The paper presents a well-designed and thorough investigation of the proposed approach. The researchers have carefully considered various design choices and their impact on the VQA performance, providing valuable insights.
One potential limitation of the work is that it relies on the availability of a large dataset of question-image pairs and corresponding captions. In real-world scenarios, such a comprehensive dataset may not always be available, and the approach may not be as effective. The researchers could have explored ways to mitigate this, such as investigating few-shot or zero-shot Zero-Shot Referring Expression Comprehension via Structural Matching techniques for caption generation.
Additionally, the paper does not delve into the potential biases or limitations of the underlying language models used for caption generation. As language models can sometimes exhibit biases or make factual mistakes, it would be valuable to understand how these issues might impact the VQA performance when using question-driven captions.
Overall, the paper presents a promising approach to enhancing VQA systems and could inspire further research in this direction, such as exploring the use of Semantically Prompted Language Models to Improve Visual Descriptions or other novel techniques for integrating question-driven information with VQA models.
Conclusion
This paper introduces a novel approach to improving visual question answering (VQA) by generating question-driven image captions and using them to augment the VQA model's input. The researchers demonstrate that this approach leads to significant performance improvements compared to using standard image captions or no captions at all.
The work is significant as it showcases a novel way to leverage additional information, in the form of question-specific image captions, to enhance the capabilities of VQA systems. The techniques explored in this paper could potentially be applied to other tasks that involve understanding images and answering questions about them, opening up new avenues for further research and development in the field of multimodal AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploring Diverse Methods in Visual Question Answering
Panfeng Li, Qikai Yang, Xieming Geng, Wenjing Zhou, Zhicheng Ding, Yi Nian
0
0
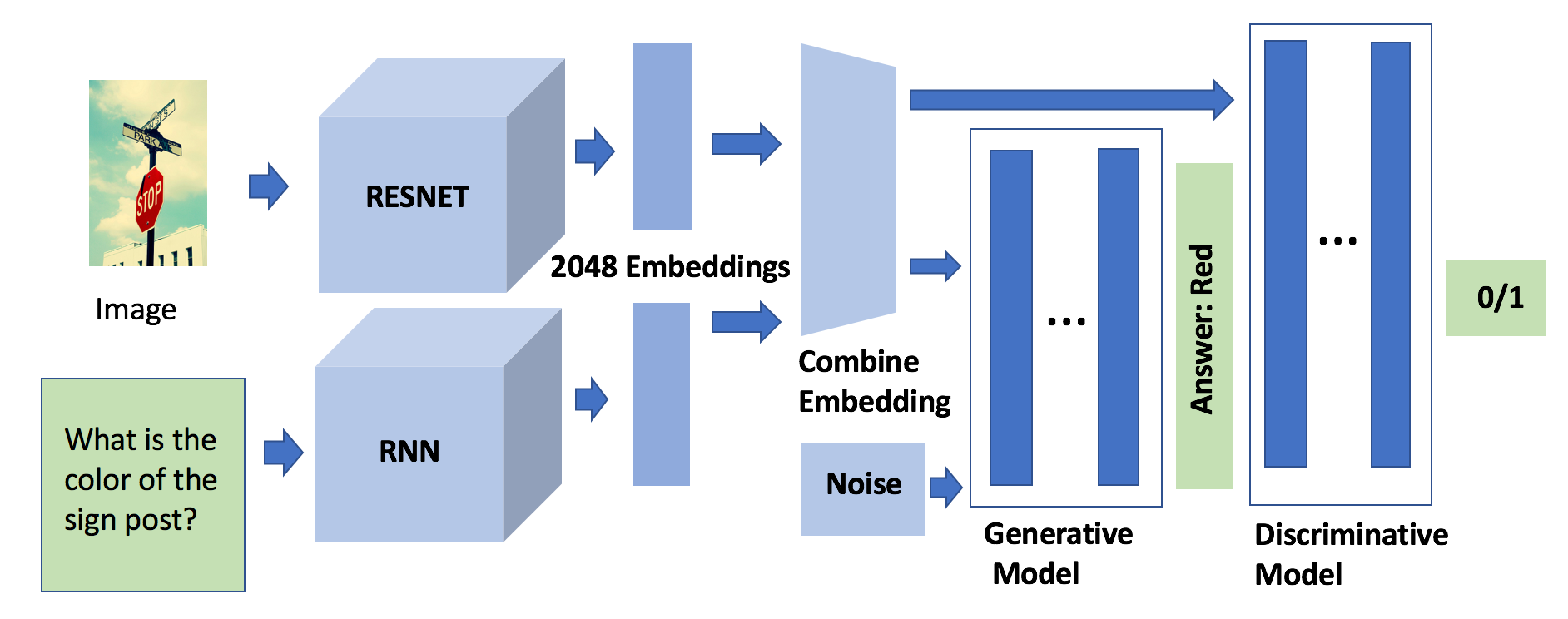
This study explores innovative methods for improving Visual Question Answering (VQA) using Generative Adversarial Networks (GANs), autoencoders, and attention mechanisms. Leveraging a balanced VQA dataset, we investigate three distinct strategies. Firstly, GAN-based approaches aim to generate answer embeddings conditioned on image and question inputs, showing potential but struggling with more complex tasks. Secondly, autoencoder-based techniques focus on learning optimal embeddings for questions and images, achieving comparable results with GAN due to better ability on complex questions. Lastly, attention mechanisms, incorporating Multimodal Compact Bilinear pooling (MCB), address language priors and attention modeling, albeit with a complexity-performance trade-off. This study underscores the challenges and opportunities in VQA and suggests avenues for future research, including alternative GAN formulations and attentional mechanisms.
4/23/2024
🖼️
Multi-Modal Prompt Learning on Blind Image Quality Assessment
Wensheng Pan, Timin Gao, Yan Zhang, Runze Hu, Xiawu Zheng, Enwei Zhang, Yuting Gao, Yutao Liu, Yunhang Shen, Ke Li, Shengchuan Zhang, Liujuan Cao, Rongrong Ji
0
0
Image Quality Assessment (IQA) models benefit significantly from semantic information, which allows them to treat different types of objects distinctly. Currently, leveraging semantic information to enhance IQA is a crucial research direction. Traditional methods, hindered by a lack of sufficiently annotated data, have employed the CLIP image-text pretraining model as their backbone to gain semantic awareness. However, the generalist nature of these pre-trained Vision-Language (VL) models often renders them suboptimal for IQA-specific tasks. Recent approaches have attempted to address this mismatch using prompt technology, but these solutions have shortcomings. Existing prompt-based VL models overly focus on incremental semantic information from text, neglecting the rich insights available from visual data analysis. This imbalance limits their performance improvements in IQA tasks. This paper introduces an innovative multi-modal prompt-based methodology for IQA. Our approach employs carefully crafted prompts that synergistically mine incremental semantic information from both visual and linguistic data. Specifically, in the visual branch, we introduce a multi-layer prompt structure to enhance the VL model's adaptability. In the text branch, we deploy a dual-prompt scheme that steers the model to recognize and differentiate between scene category and distortion type, thereby refining the model's capacity to assess image quality. Our experimental findings underscore the effectiveness of our method over existing Blind Image Quality Assessment (BIQA) approaches. Notably, it demonstrates competitive performance across various datasets. Our method achieves Spearman Rank Correlation Coefficient (SRCC) values of 0.961(surpassing 0.946 in CSIQ) and 0.941 (exceeding 0.930 in KADID), illustrating its robustness and accuracy in diverse contexts.
4/24/2024
Towards Top-Down Reasoning: An Explainable Multi-Agent Approach for Visual Question Answering
Zeqing Wang, Wentao Wan, Qiqing Lao, Runmeng Chen, Minjie Lang, Keze Wang, Liang Lin
0
0
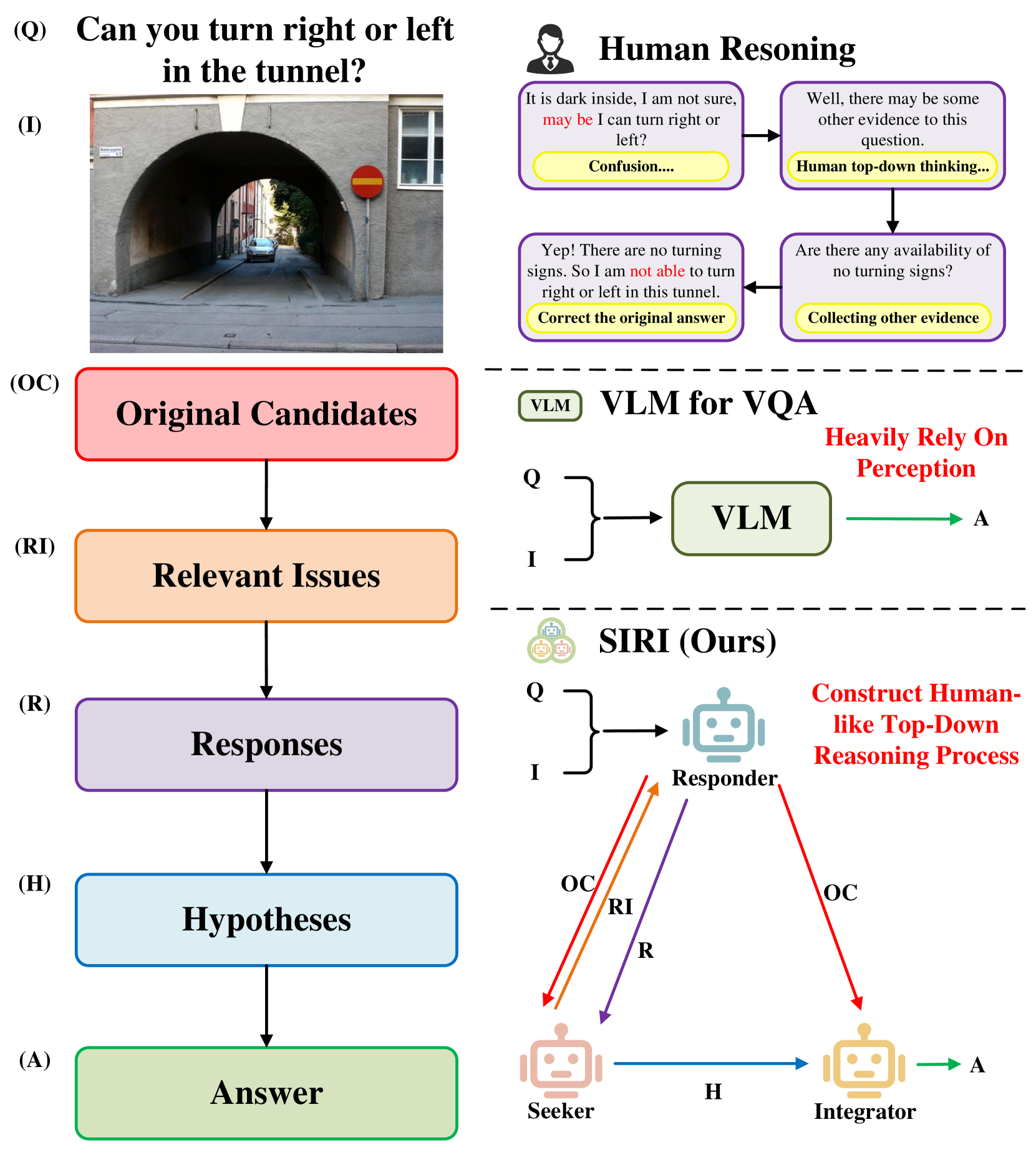
Recently, several methods have been proposed to augment large Vision Language Models (VLMs) for Visual Question Answering (VQA) simplicity by incorporating external knowledge from knowledge bases or visual clues derived from question decomposition. Although having achieved promising results, these methods still suffer from the challenge that VLMs cannot inherently understand the incorporated knowledge and might fail to generate the optimal answers. Contrarily, human cognition engages visual questions through a top-down reasoning process, systematically exploring relevant issues to derive a comprehensive answer. This not only facilitates an accurate answer but also provides a transparent rationale for the decision-making pathway. Motivated by this cognitive mechanism, we introduce a novel, explainable multi-agent collaboration framework designed to imitate human-like top-down reasoning by leveraging the expansive knowledge of Large Language Models (LLMs). Our framework comprises three agents, i.e., Responder, Seeker, and Integrator, each contributing uniquely to the top-down reasoning process. The VLM-based Responder generates the answer candidates for the question and gives responses to other issues. The Seeker, primarily based on LLM, identifies relevant issues related to the question to inform the Responder and constructs a Multi-View Knowledge Base (MVKB) for the given visual scene by leveraging the understanding capabilities of LLM. The Integrator agent combines information from the Seeker and the Responder to produce the final VQA answer. Through this collaboration mechanism, our framework explicitly constructs an MVKB for a specific visual scene and reasons answers in a top-down reasoning process. Extensive and comprehensive evaluations on diverse VQA datasets and VLMs demonstrate the superior applicability and interpretability of our framework over the existing compared methods.
5/15/2024
Find The Gap: Knowledge Base Reasoning For Visual Question Answering
Elham J. Barezi, Parisa Kordjamshidi
0
0
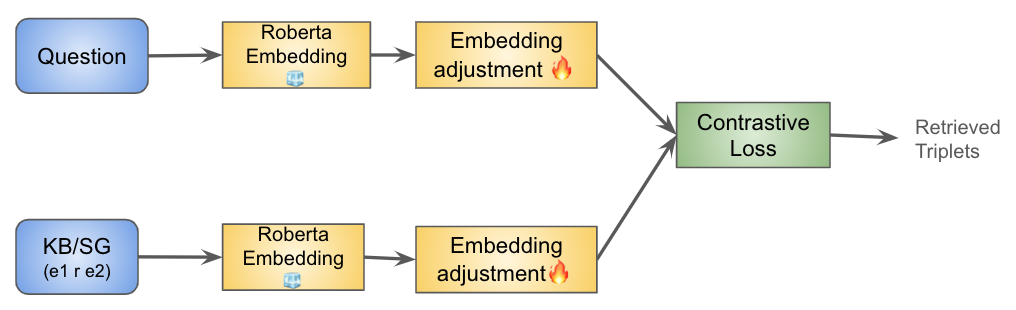
We analyze knowledge-based visual question answering, for which given a question, the models need to ground it into the visual modality and retrieve the relevant knowledge from a given large knowledge base (KB) to be able to answer. Our analysis has two folds, one based on designing neural architectures and training them from scratch, and another based on large pre-trained language models (LLMs). Our research questions are: 1) Can we effectively augment models by explicit supervised retrieval of the relevant KB information to solve the KB-VQA problem? 2) How do task-specific and LLM-based models perform in the integration of visual and external knowledge, and multi-hop reasoning over both sources of information? 3) Is the implicit knowledge of LLMs sufficient for KB-VQA and to what extent it can replace the explicit KB? Our results demonstrate the positive impact of empowering task-specific and LLM models with supervised external and visual knowledge retrieval models. Our findings show that though LLMs are stronger in 1-hop reasoning, they suffer in 2-hop reasoning in comparison with our fine-tuned NN model even if the relevant information from both modalities is available to the model. Moreover, we observed that LLM models outperform the NN model for KB-related questions which confirms the effectiveness of implicit knowledge in LLMs however, they do not alleviate the need for external KB.
4/17/2024