CiteME: Can Language Models Accurately Cite Scientific Claims?

0

Sign in to get full access
Overview
- This paper introduces the CiteME benchmark, which evaluates the ability of language models to accurately cite scientific claims.
- The authors find that while large language models can perform well on traditional text generation tasks, they struggle to correctly attribute claims to the appropriate sources.
- The paper highlights the importance of developing models that can effectively reason about scientific concepts and the relationships between them.
Plain English Explanation
The researchers behind this paper wanted to see how well large language models can handle a specific task: accurately citing scientific claims. In other words, if a model is given a scientific statement, can it correctly identify the research paper or papers that support that claim?
This is an important ability, as language models are increasingly being used to assist with tasks like generating academic texts or automatically adding citations to documents. If the models can't properly connect claims to their sources, it could lead to the propagation of misinformation or poorly supported arguments.
To test this, the researchers created the CiteME benchmark, a dataset designed to evaluate a model's citation accuracy. They found that while large language models perform well on general text generation, they struggle when it comes to this more specialized task of correctly attributing scientific claims.
This suggests that simply scaling up language models may not be enough to ensure they can effectively reason about complex scientific concepts and the relationships between them. Additional research and techniques may be needed to help these models better understand and verify the truthfulness of scientific information.
Technical Explanation
The paper introduces the CiteME benchmark, a dataset and evaluation framework for assessing a language model's ability to accurately cite scientific claims. The benchmark consists of over 10,000 claims extracted from research papers, each paired with the set of papers that support that claim.
To evaluate model performance, the authors fine-tune several large language models, including GPT-3 and T5, on the CiteME dataset. The models are tasked with predicting the relevant citation(s) for a given claim. The authors measure accuracy, mean reciprocal rank, and other metrics to compare the models' citation performance.
The results show that while the language models perform well on general text generation tasks, they struggle to correctly attribute scientific claims to the appropriate source materials. The authors find that models tend to overpredict the number of relevant citations and often fail to include the ground-truth citations.
The paper discusses several potential reasons for this poor citation performance, including the models' lack of grounding in scientific knowledge and their inability to effectively reason about the logical relationships between claims and supporting evidence. The authors suggest that developing new techniques for enhancing language models' scientific understanding may be necessary to improve their citation abilities.
Critical Analysis
The CiteME benchmark represents an important step in evaluating the limitations of current language models when it comes to handling scientific information. The authors have carefully designed the dataset and evaluation metrics to provide a meaningful test of citation accuracy.
One potential limitation of the study is the use of only a handful of language models, all of which were pre-trained on general internet data. It's possible that models with more specialized scientific training or architectural innovations could perform better on the CiteME task. The authors acknowledge this and call for further research in this direction.
Additionally, the paper does not delve deeply into the specific failure modes of the language models. Understanding the types of errors the models make (e.g., overpredicting citations, missing key references) could provide valuable insights to guide future model development.
Overall, this paper highlights an important gap in the capabilities of current language models and motivates the need for additional research to enhance their scientific reasoning abilities. Bridging this gap could have significant implications for the reliable use of language models in academic and scientific settings.
Conclusion
This paper presents the CiteME benchmark, a new tool for evaluating the ability of language models to accurately cite scientific claims. The results show that while large language models excel at general text generation, they struggle to correctly attribute claims to their supporting sources.
The findings suggest that simply scaling up language models may not be enough to ensure they can effectively reason about complex scientific concepts and relationships. Developing new techniques for grounding language models in scientific knowledge and enhancing their logical reasoning capabilities could be crucial for enabling these models to serve as reliable assistants in academic and research settings.
As language models continue to advance, the CiteME benchmark provides a valuable framework for assessing their progress in this important area. Further research building on this work could lead to significant improvements in the trustworthiness and utility of language models for scientific and scholarly applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CiteME: Can Language Models Accurately Cite Scientific Claims?
Ori Press, Andreas Hochlehnert, Ameya Prabhu, Vishaal Udandarao, Ofir Press, Matthias Bethge
Thousands of new scientific papers are published each month. Such information overload complicates researcher efforts to stay current with the state-of-the-art as well as to verify and correctly attribute claims. We pose the following research question: Given a text excerpt referencing a paper, could an LM act as a research assistant to correctly identify the referenced paper? We advance efforts to answer this question by building a benchmark that evaluates the abilities of LMs in citation attribution. Our benchmark, CiteME, consists of text excerpts from recent machine learning papers, each referencing a single other paper. CiteME use reveals a large gap between frontier LMs and human performance, with LMs achieving only 4.2-18.5% accuracy and humans 69.7%. We close this gap by introducing CiteAgent, an autonomous system built on the GPT-4o LM that can also search and read papers, which achieves an accuracy of 35.3% on CiteME. Overall, CiteME serves as a challenging testbed for open-ended claim attribution, driving the research community towards a future where any claim made by an LM can be automatically verified and discarded if found to be incorrect.
Read more7/19/2024
0
Context-Enhanced Language Models for Generating Multi-Paper Citations
Avinash Anand, Kritarth Prasad, Ujjwal Goel, Mohit Gupta, Naman Lal, Astha Verma, Rajiv Ratn Shah
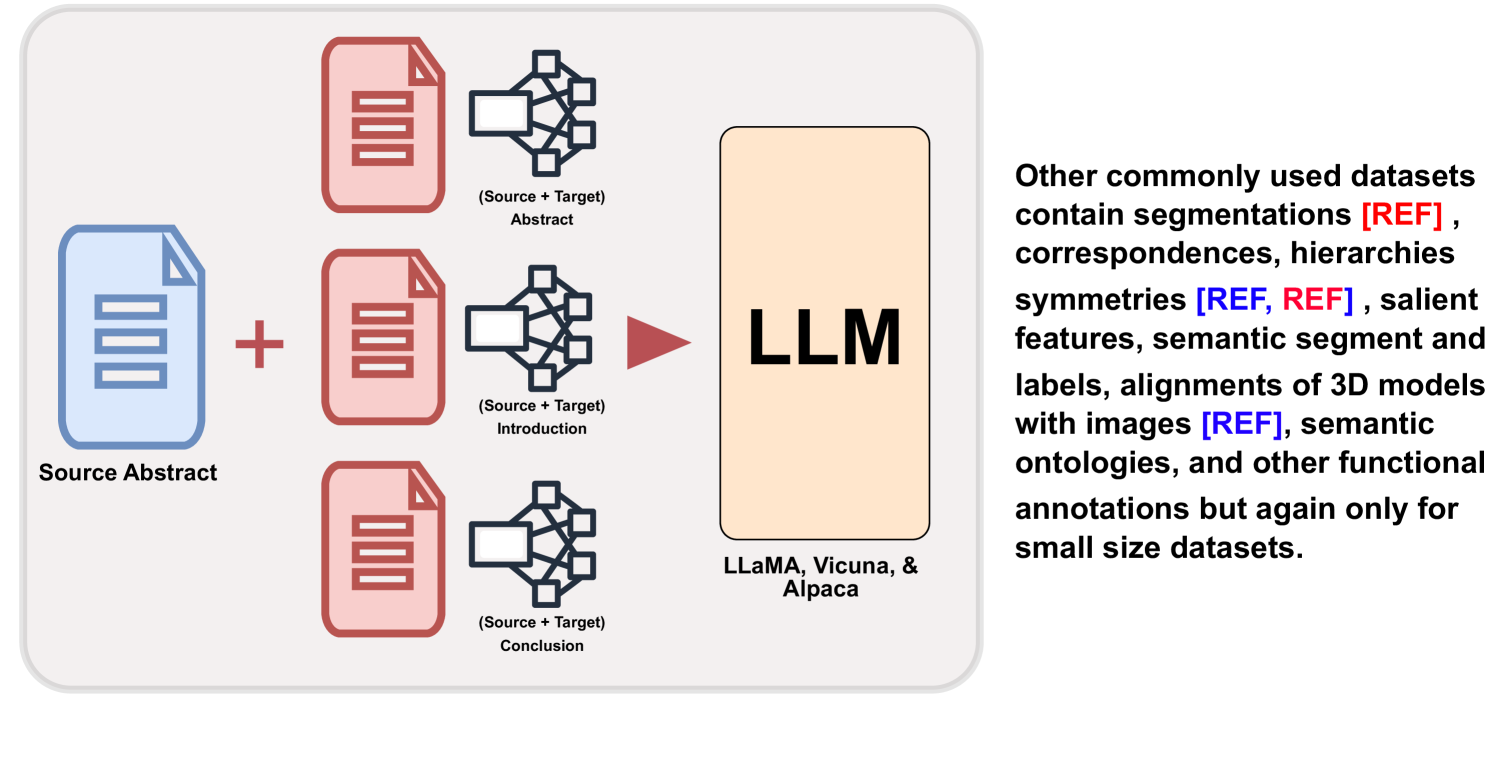
Citation text plays a pivotal role in elucidating the connection between scientific documents, demanding an in-depth comprehension of the cited paper. Constructing citations is often time-consuming, requiring researchers to delve into extensive literature and grapple with articulating relevant content. To address this challenge, the field of citation text generation (CTG) has emerged. However, while earlier methods have primarily centered on creating single-sentence citations, practical scenarios frequently necessitate citing multiple papers within a single paragraph. To bridge this gap, we propose a method that leverages Large Language Models (LLMs) to generate multi-citation sentences. Our approach involves a single source paper and a collection of target papers, culminating in a coherent paragraph containing multi-sentence citation text. Furthermore, we introduce a curated dataset named MCG-S2ORC, composed of English-language academic research papers in Computer Science, showcasing multiple citation instances. In our experiments, we evaluate three LLMs LLaMA, Alpaca, and Vicuna to ascertain the most effective model for this endeavor. Additionally, we exhibit enhanced performance by integrating knowledge graphs from target papers into the prompts for generating citation text. This research underscores the potential of harnessing LLMs for citation generation, opening a compelling avenue for exploring the intricate connections between scientific documents.
Read more4/23/2024

0
Large Language Models Reflect Human Citation Patterns with a Heightened Citation Bias
Andres Algaba, Carmen Mazijn, Vincent Holst, Floriano Tori, Sylvia Wenmackers, Vincent Ginis
Citation practices are crucial in shaping the structure of scientific knowledge, yet they are often influenced by contemporary norms and biases. The emergence of Large Language Models (LLMs) introduces a new dynamic to these practices. Interestingly, the characteristics and potential biases of references recommended by LLMs that entirely rely on their parametric knowledge, and not on search or retrieval-augmented generation, remain unexplored. Here, we analyze these characteristics in an experiment using a dataset from AAAI, NeurIPS, ICML, and ICLR, published after GPT-4's knowledge cut-off date. In our experiment, LLMs are tasked with suggesting scholarly references for the anonymized in-text citations within these papers. Our findings reveal a remarkable similarity between human and LLM citation patterns, but with a more pronounced high citation bias, which persists even after controlling for publication year, title length, number of authors, and venue. The results hold for both GPT-4, and the more capable models GPT-4o and Claude 3.5 where the papers are part of the training data. Additionally, we observe a large consistency between the characteristics of LLM's existing and non-existent generated references, indicating the model's internalization of citation patterns. By analyzing citation graphs, we show that the references recommended are embedded in the relevant citation context, suggesting an even deeper conceptual internalization of the citation networks. While LLMs can aid in citation generation, they may also amplify existing biases, such as the Matthew effect, and introduce new ones, potentially skewing scientific knowledge dissemination.
Read more8/27/2024

0
Modeling citation worthiness by using attention-based bidirectional long short-term memory networks and interpretable models
Tong Zeng, Daniel E. Acuna
Scientist learn early on how to cite scientific sources to support their claims. Sometimes, however, scientists have challenges determining where a citation should be situated -- or, even worse, fail to cite a source altogether. Automatically detecting sentences that need a citation (i.e., citation worthiness) could solve both of these issues, leading to more robust and well-constructed scientific arguments. Previous researchers have applied machine learning to this task but have used small datasets and models that do not take advantage of recent algorithmic developments such as attention mechanisms in deep learning. We hypothesize that we can develop significantly accurate deep learning architectures that learn from large supervised datasets constructed from open access publications. In this work, we propose a Bidirectional Long Short-Term Memory (BiLSTM) network with attention mechanism and contextual information to detect sentences that need citations. We also produce a new, large dataset (PMOA-CITE) based on PubMed Open Access Subset, which is orders of magnitude larger than previous datasets. Our experiments show that our architecture achieves state of the art performance on the standard ACL-ARC dataset ($F_{1}=0.507$) and exhibits high performance ($F_{1}=0.856$) on the new PMOA-CITE. Moreover, we show that it can transfer learning across these datasets. We further use interpretable models to illuminate how specific language is used to promote and inhibit citations. We discover that sections and surrounding sentences are crucial for our improved predictions. We further examined purported mispredictions of the model, and uncovered systematic human mistakes in citation behavior and source data. This opens the door for our model to check documents during pre-submission and pre-archival procedures. We make this new dataset, the code, and a web-based tool available to the community.
Read more5/21/2024