Modeling citation worthiness by using attention-based bidirectional long short-term memory networks and interpretable models

0

Sign in to get full access
Overview
- This paper presents a model for predicting the "citation worthiness" of sentences in scientific papers, which refers to their likelihood of being cited by other researchers.
- The authors use an attention-based Bidirectional Long Short-Term Memory (BiLSTM) network to capture the context and semantic information of sentences, and also explore more interpretable models like logistic regression and decision trees.
- The goal is to develop a system that can automatically identify the most impactful sentences in a paper, which can help researchers navigate the growing volume of scientific literature more efficiently.
Plain English Explanation
With the ever-increasing volume of scientific research being published, it can be challenging for researchers to sift through all the available information and identify the most important and influential studies. <a href="https://aimodels.fyi/papers/arxiv/reasons-benchmark-retrieval-automated-citations-scientific-sentences">This paper proposes a solution to this problem</a> by developing a machine learning model that can predict which sentences in a scientific paper are most likely to be cited by other researchers.
The key idea is to use a type of neural network called a Bidirectional Long Short-Term Memory (BiLSTM) network, which is able to understand the context and meaning of sentences by analyzing them from both the beginning and the end. <a href="https://aimodels.fyi/papers/arxiv/neural-sequence-to-sequence-modeling-attention-by">This "attention" mechanism</a> allows the model to identify the most relevant parts of each sentence that contribute to its citation worthiness.
In addition to the BiLSTM model, the researchers also explore more interpretable models like logistic regression and decision trees. These simpler models can provide insights into the specific factors that make a sentence more or less likely to be cited, such as the presence of certain keywords or the position of the sentence within the paper.
By developing effective methods for automatically identifying the most impactful sentences in a scientific paper, this research <a href="https://aimodels.fyi/papers/arxiv/context-enhanced-language-models-generating-multi-paper">aims to help researchers navigate the vast and ever-growing body of scientific literature more efficiently</a>. This could ultimately lead to faster progress and greater collaboration within the scientific community.
Technical Explanation
The paper presents two main approaches for modeling citation worthiness of sentences in scientific papers:
-
Attention-based Bidirectional Long Short-Term Memory (BiLSTM) Network: The authors use a BiLSTM architecture to capture the contextual and semantic information of sentences. <a href="https://aimodels.fyi/papers/arxiv/neural-sequence-to-sequence-modeling-attention-by">The attention mechanism</a> allows the model to focus on the most relevant parts of each sentence when predicting its citation worthiness.
-
Interpretable Models: In addition to the BiLSTM, the researchers explore more interpretable models such as logistic regression and decision trees. These simpler models can provide insights into the specific features that contribute to a sentence's citation potential, like the presence of certain keywords or the position of the sentence within the paper.
The authors evaluate their models on two publicly available datasets: <a href="https://aimodels.fyi/papers/arxiv/reasons-benchmark-retrieval-automated-citations-scientific-sentences">Semantic Scholar's Citation Context Corpus</a> and <a href="https://aimodels.fyi/papers/arxiv/source-aware-training-enables-knowledge-attribution-language">the Citeworth dataset</a>. They compare the performance of the BiLSTM and interpretable models, and also analyze the attention weights learned by the BiLSTM to understand which parts of the sentences are most predictive of citation worthiness.
Critical Analysis
The research presented in this paper is a valuable contribution to the field of scientific literature mining and analysis. By developing effective methods for automatically identifying the most impactful sentences in a paper, the authors address an important challenge that can help researchers navigate the growing volume of scientific publications more efficiently.
However, the paper also acknowledges several limitations and areas for future work. For example, the models are trained and evaluated on a relatively small set of papers, and their performance may not generalize well to a broader range of scientific domains. <a href="https://aimodels.fyi/papers/arxiv/learning-to-plan-generate-text-citations">Additionally, the authors note that the citation worthiness of a sentence can be influenced by factors beyond the text itself, such as the reputation of the authors or the prestige of the publishing venue</a>. Incorporating these additional signals could potentially improve the model's accuracy.
Furthermore, while the interpretable models provide valuable insights into the specific features that contribute to citation worthiness, the authors acknowledge that these simpler models may not achieve the same level of predictive performance as the more complex BiLSTM approach. Striking the right balance between model interpretability and predictive power is an ongoing challenge in the field of machine learning.
Overall, this research represents a promising step towards more efficient and effective navigation of the scientific literature, and the authors have laid the groundwork for further exploration and refinement of these techniques.
Conclusion
This paper presents a novel approach to modeling the citation worthiness of sentences in scientific papers, using a combination of attention-based BiLSTM networks and more interpretable models like logistic regression and decision trees. The goal is to develop a system that can automatically identify the most impactful sentences in a paper, which can help researchers navigate the growing volume of scientific literature more efficiently.
The authors demonstrate that their models are able to achieve strong performance on two publicly available datasets, and they also provide insights into the factors that contribute to a sentence's citation potential. While the research has some limitations and areas for future work, it represents a valuable contribution to the field of scientific literature mining and analysis, and could ultimately lead to faster progress and greater collaboration within the scientific community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Modeling citation worthiness by using attention-based bidirectional long short-term memory networks and interpretable models
Tong Zeng, Daniel E. Acuna
Scientist learn early on how to cite scientific sources to support their claims. Sometimes, however, scientists have challenges determining where a citation should be situated -- or, even worse, fail to cite a source altogether. Automatically detecting sentences that need a citation (i.e., citation worthiness) could solve both of these issues, leading to more robust and well-constructed scientific arguments. Previous researchers have applied machine learning to this task but have used small datasets and models that do not take advantage of recent algorithmic developments such as attention mechanisms in deep learning. We hypothesize that we can develop significantly accurate deep learning architectures that learn from large supervised datasets constructed from open access publications. In this work, we propose a Bidirectional Long Short-Term Memory (BiLSTM) network with attention mechanism and contextual information to detect sentences that need citations. We also produce a new, large dataset (PMOA-CITE) based on PubMed Open Access Subset, which is orders of magnitude larger than previous datasets. Our experiments show that our architecture achieves state of the art performance on the standard ACL-ARC dataset ($F_{1}=0.507$) and exhibits high performance ($F_{1}=0.856$) on the new PMOA-CITE. Moreover, we show that it can transfer learning across these datasets. We further use interpretable models to illuminate how specific language is used to promote and inhibit citations. We discover that sections and surrounding sentences are crucial for our improved predictions. We further examined purported mispredictions of the model, and uncovered systematic human mistakes in citation behavior and source data. This opens the door for our model to check documents during pre-submission and pre-archival procedures. We make this new dataset, the code, and a web-based tool available to the community.
Read more5/21/2024
0
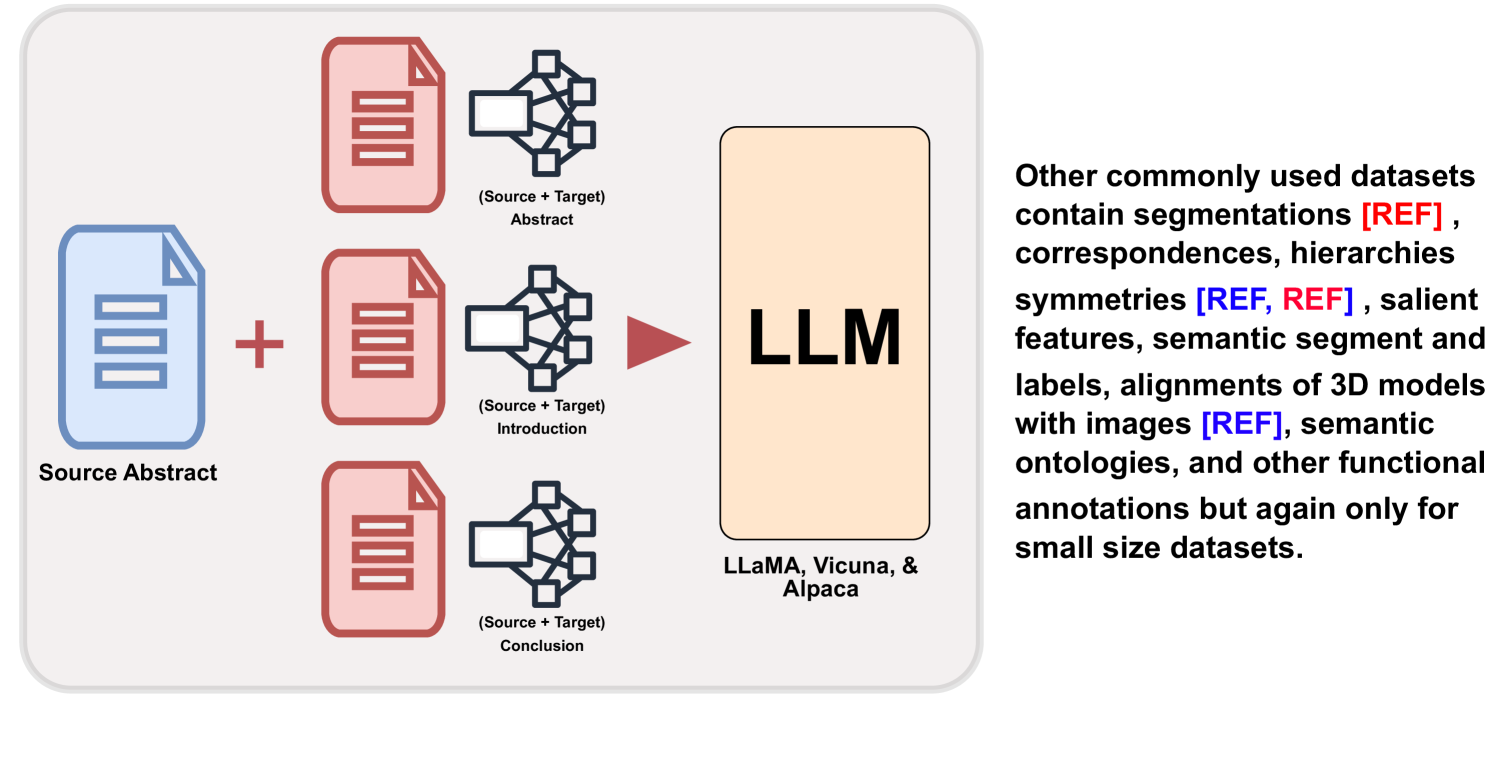
Context-Enhanced Language Models for Generating Multi-Paper Citations
Avinash Anand, Kritarth Prasad, Ujjwal Goel, Mohit Gupta, Naman Lal, Astha Verma, Rajiv Ratn Shah
Citation text plays a pivotal role in elucidating the connection between scientific documents, demanding an in-depth comprehension of the cited paper. Constructing citations is often time-consuming, requiring researchers to delve into extensive literature and grapple with articulating relevant content. To address this challenge, the field of citation text generation (CTG) has emerged. However, while earlier methods have primarily centered on creating single-sentence citations, practical scenarios frequently necessitate citing multiple papers within a single paragraph. To bridge this gap, we propose a method that leverages Large Language Models (LLMs) to generate multi-citation sentences. Our approach involves a single source paper and a collection of target papers, culminating in a coherent paragraph containing multi-sentence citation text. Furthermore, we introduce a curated dataset named MCG-S2ORC, composed of English-language academic research papers in Computer Science, showcasing multiple citation instances. In our experiments, we evaluate three LLMs LLaMA, Alpaca, and Vicuna to ascertain the most effective model for this endeavor. Additionally, we exhibit enhanced performance by integrating knowledge graphs from target papers into the prompts for generating citation text. This research underscores the potential of harnessing LLMs for citation generation, opening a compelling avenue for exploring the intricate connections between scientific documents.
Read more4/23/2024

0
CiteME: Can Language Models Accurately Cite Scientific Claims?
Ori Press, Andreas Hochlehnert, Ameya Prabhu, Vishaal Udandarao, Ofir Press, Matthias Bethge
Thousands of new scientific papers are published each month. Such information overload complicates researcher efforts to stay current with the state-of-the-art as well as to verify and correctly attribute claims. We pose the following research question: Given a text excerpt referencing a paper, could an LM act as a research assistant to correctly identify the referenced paper? We advance efforts to answer this question by building a benchmark that evaluates the abilities of LMs in citation attribution. Our benchmark, CiteME, consists of text excerpts from recent machine learning papers, each referencing a single other paper. CiteME use reveals a large gap between frontier LMs and human performance, with LMs achieving only 4.2-18.5% accuracy and humans 69.7%. We close this gap by introducing CiteAgent, an autonomous system built on the GPT-4o LM that can also search and read papers, which achieves an accuracy of 35.3% on CiteME. Overall, CiteME serves as a challenging testbed for open-ended claim attribution, driving the research community towards a future where any claim made by an LM can be automatically verified and discarded if found to be incorrect.
Read more7/19/2024

0
Learning to Generate Answers with Citations via Factual Consistency Models
Rami Aly, Zhiqiang Tang, Samson Tan, George Karypis
Large Language Models (LLMs) frequently hallucinate, impeding their reliability in mission-critical situations. One approach to address this issue is to provide citations to relevant sources alongside generated content, enhancing the verifiability of generations. However, citing passages accurately in answers remains a substantial challenge. This paper proposes a weakly-supervised fine-tuning method leveraging factual consistency models (FCMs). Our approach alternates between generating texts with citations and supervised fine-tuning with FCM-filtered citation data. Focused learning is integrated into the objective, directing the fine-tuning process to emphasise the factual unit tokens, as measured by an FCM. Results on the ALCE few-shot citation benchmark with various instruction-tuned LLMs demonstrate superior performance compared to in-context learning, vanilla supervised fine-tuning, and state-of-the-art methods, with an average improvement of $34.1$, $15.5$, and $10.5$ citation F$_1$ points, respectively. Moreover, in a domain transfer setting we show that the obtained citation generation ability robustly transfers to unseen datasets. Notably, our citation improvements contribute to the lowest factual error rate across baselines.
Read more7/16/2024