CL4KGE: A Curriculum Learning Method for Knowledge Graph Embedding

0

Sign in to get full access
Overview
- This paper proposes a curriculum learning method called CL4KGE for improving the performance of knowledge graph embedding models.
- Curriculum learning is a training technique that presents examples to the model in a meaningful order, starting with easier examples and gradually increasing the difficulty.
- The authors apply this approach to knowledge graph embedding, where the goal is to learn low-dimensional vector representations of entities and relationships in a knowledge graph.
Plain English Explanation
The paper introduces a new training method called CL4KGE for knowledge graph embedding models. Knowledge graph embedding is a way to represent the entities and relationships in a knowledge graph as low-dimensional vectors. These vector representations can then be used for various downstream tasks like question answering or link prediction.
The key idea behind CL4KGE is to train the model using a curriculum learning approach. This means the model is first trained on "easier" examples, and then the difficulty is gradually increased over time. The authors hypothesize that this will help the model learn more effectively compared to training on all examples at once.
For example, the model might first be trained on simple relationships like "person-birthplace" before moving on to more complex relationships like "person-employer". The hope is that starting simple and building up complexity will lead to better performance on the final task.
Technical Explanation
The paper presents a curriculum learning approach for training knowledge graph embedding models, called CL4KGE. The key components are:
-
Curriculum Construction: The authors define a curriculum based on the "complexity" of relationships in the knowledge graph. Simpler relationships like "person-birthplace" are considered easier than more complex ones like "person-employer".
-
Curriculum-based Training: The model is first trained on the easiest examples in the curriculum, and then the difficulty is gradually increased over successive training epochs. This allows the model to learn progressively more complex patterns.
-
Curriculum Evaluation: The authors evaluate the model's performance at different stages of the curriculum to ensure it is learning effectively. They also experiment with different curricula to find the most effective ordering of examples.
The paper evaluates CL4KGE on several standard knowledge graph embedding benchmarks and finds that it outperforms standard training approaches. The authors attribute this improvement to the model's ability to learn more effectively by starting simple and building up complexity.
Critical Analysis
The paper makes a compelling case for using curriculum learning to improve knowledge graph embedding models. The experiments demonstrate clear performance gains over standard training, which suggests curriculum learning is a promising technique in this domain.
However, the paper does not extensively explore the limitations of the approach. For example, it's unclear how sensitive the method is to the specific definition of "complexity" used to construct the curriculum. Additionally, the experiments are limited to standard benchmark datasets, and it's uncertain how well the approach would generalize to more diverse or challenging knowledge graphs.
Further research could investigate the robustness of CL4KGE to different curriculum designs, as well as its performance on real-world knowledge graphs with diverse, noisy, and dynamic data. Exploring ways to automatically construct effective curricula could also be a fruitful direction.
Conclusion
This paper introduces a novel curriculum learning method called CL4KGE for improving knowledge graph embedding models. The key insight is to train the model on easier examples first and gradually increase the difficulty, allowing it to learn more effectively compared to standard training approaches.
The experimental results demonstrate the effectiveness of this technique, suggesting curriculum learning is a promising direction for advancing the state-of-the-art in knowledge graph representation learning. While the paper does not extensively explore the limitations of the approach, it lays the groundwork for further research into curriculum-based training methods for knowledge graphs and other structured data domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CL4KGE: A Curriculum Learning Method for Knowledge Graph Embedding
Yang Liu, Chuan Zhou, Peng Zhang, Yanan Cao, Yongchao Liu, Zhao Li, Hongyang Chen
Knowledge graph embedding (KGE) constitutes a foundational task, directed towards learning representations for entities and relations within knowledge graphs (KGs), with the objective of crafting representations comprehensive enough to approximate the logical and symbolic interconnections among entities. In this paper, we define a metric Z-counts to measure the difficulty of training each triple ($$) in KGs with theoretical analysis. Based on this metric, we propose textbf{CL4KGE}, an efficient textbf{C}urriculum textbf{L}earning based training strategy for textbf{KGE}. This method includes a difficulty measurer and a training scheduler that aids in the training of KGE models. Our approach possesses the flexibility to act as a plugin within a wide range of KGE models, with the added advantage of adaptability to the majority of KGs in existence. The proposed method has been evaluated on popular KGE models, and the results demonstrate that it enhances the state-of-the-art methods. The use of Z-counts as a metric has enabled the identification of challenging triples in KGs, which helps in devising effective training strategies.
Read more9/10/2024
0
On The Expressive Power of Knowledge Graph Embedding Methods
Jiexing Gao, Dmitry Rodin, Vasily Motolygin, Denis Zaytsev
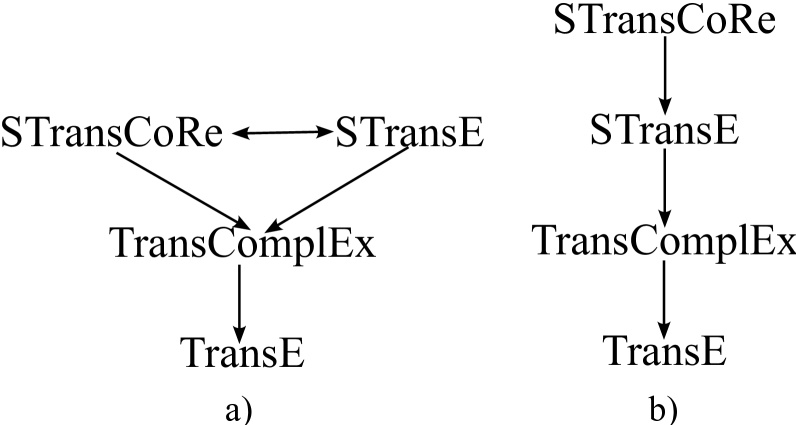
Knowledge Graph Embedding (KGE) is a popular approach, which aims to represent entities and relations of a knowledge graph in latent spaces. Their representations are known as embeddings. To measure the plausibility of triplets, score functions are defined over embedding spaces. Despite wide dissemination of KGE in various tasks, KGE methods have limitations in reasoning abilities. In this paper we propose a mathematical framework to compare reasoning abilities of KGE methods. We show that STransE has a higher capability than TransComplEx, and then present new STransCoRe method, which improves the STransE by combining it with the TransCoRe insights, which can reduce the STransE space complexity.
Read more7/29/2024

0
Croppable Knowledge Graph Embedding
Yushan Zhu, Wen Zhang, Zhiqiang Liu, Mingyang Chen, Lei Liang, Huajun Chen
Knowledge Graph Embedding (KGE) is a common method for Knowledge Graphs (KGs) to serve various artificial intelligence tasks. The suitable dimensions of the embeddings depend on the storage and computing conditions of the specific application scenarios. Once a new dimension is required, a new KGE model needs to be trained from scratch, which greatly increases the training cost and limits the efficiency and flexibility of KGE in serving various scenarios. In this work, we propose a novel KGE training framework MED, through which we could train once to get a croppable KGE model applicable to multiple scenarios with different dimensional requirements, sub-models of the required dimensions can be cropped out of it and used directly without any additional training. In MED, we propose a mutual learning mechanism to improve the low-dimensional sub-models performance and make the high-dimensional sub-models retain the capacity that low-dimensional sub-models have, an evolutionary improvement mechanism to promote the high-dimensional sub-models to master the knowledge that the low-dimensional sub-models can not learn, and a dynamic loss weight to balance the multiple losses adaptively. Experiments on 3 KGE models over 4 standard KG completion datasets, 3 real application scenarios over a real-world large-scale KG, and the experiments of extending MED to the language model BERT show the effectiveness, high efficiency, and flexible extensibility of MED.
Read more7/4/2024

0
KG-FIT: Knowledge Graph Fine-Tuning Upon Open-World Knowledge
Pengcheng Jiang, Lang Cao, Cao Xiao, Parminder Bhatia, Jimeng Sun, Jiawei Han
Knowledge Graph Embedding (KGE) techniques are crucial in learning compact representations of entities and relations within a knowledge graph, facilitating efficient reasoning and knowledge discovery. While existing methods typically focus either on training KGE models solely based on graph structure or fine-tuning pre-trained language models with classification data in KG, KG-FIT leverages LLM-guided refinement to construct a semantically coherent hierarchical structure of entity clusters. By incorporating this hierarchical knowledge along with textual information during the fine-tuning process, KG-FIT effectively captures both global semantics from the LLM and local semantics from the KG. Extensive experiments on the benchmark datasets FB15K-237, YAGO3-10, and PrimeKG demonstrate the superiority of KG-FIT over state-of-the-art pre-trained language model-based methods, achieving improvements of 14.4%, 13.5%, and 11.9% in the Hits@10 metric for the link prediction task, respectively. Furthermore, KG-FIT yields substantial performance gains of 12.6%, 6.7%, and 17.7% compared to the structure-based base models upon which it is built. These results highlight the effectiveness of KG-FIT in incorporating open-world knowledge from LLMs to significantly enhance the expressiveness and informativeness of KG embeddings.
Read more6/5/2024