Croppable Knowledge Graph Embedding

0

Sign in to get full access
Overview
- This paper proposes a new knowledge graph embedding method called "Croppable Knowledge Graph Embedding" (CKG).
- CKG aims to learn embeddings that can be effectively cropped or reduced in size while maintaining performance on downstream tasks.
- The key idea is to incorporate a cropping module into the embedding training process, which encourages the model to learn embeddings that are robust to cropping.
- Experiments on several knowledge graph benchmark datasets show that CKG outperforms state-of-the-art knowledge graph embedding methods, especially when the embeddings are cropped.
Plain English Explanation
Knowledge graphs are digital representations of information, where entities (like people, places, or things) are connected by relationships. Embedding models learn numerical representations of the entities and relationships in a knowledge graph, which can be useful for a variety of applications.
However, in some cases, you may want to use a smaller version of the knowledge graph embeddings, for example to save storage space or reduce the computational cost. The problem is that simply cropping or reducing the size of standard knowledge graph embeddings can hurt their performance on downstream tasks.
The researchers behind this paper developed a new embedding method called "Croppable Knowledge Graph Embedding" (CKG) that addresses this issue. The key idea is to train the embedding model in a way that encourages it to learn representations that remain effective even when cropped or reduced in size.
During training, CKG incorporates a "cropping module" that randomly crops the embeddings. This forces the model to learn embeddings that are robust to cropping, so that even if you use a smaller version of the embeddings, they will still perform well on tasks like predicting relationships between entities.
The paper shows that CKG outperforms other state-of-the-art knowledge graph embedding methods, especially when the embeddings are cropped or reduced in size. This makes CKG particularly useful for applications where storage space or computational resources are limited, but you still need high-performing knowledge graph embeddings.
Technical Explanation
The key innovation in this paper is the introduction of a "cropping module" into the knowledge graph embedding training process. Typically, knowledge graph embedding models like TransE, RotatE, and ConvE are trained to learn entity and relation embeddings that capture the structure of the knowledge graph.
CKG builds on this by incorporating a cropping module that randomly crops the entity and relation embeddings during training. This encourages the model to learn embeddings that are robust to cropping, so that even if you use a smaller version of the embeddings, they will still perform well on downstream tasks.
Specifically, the cropping module randomly selects a subset of the dimensions in the entity and relation embeddings and sets the remaining dimensions to zero. This forces the model to learn embeddings that can maintain their performance even when a portion of the dimensions are removed.
The researchers evaluate CKG on several knowledge graph benchmark datasets, including FB15K-237, WN18RR, and NELL-995. They show that CKG outperforms state-of-the-art methods like TransE, RotatE, and ConvE, especially when the embeddings are cropped or reduced in size.
Critical Analysis
The researchers acknowledge that the CKG method may be sensitive to the choice of cropping ratio and other hyperparameters, which could affect its performance. Additionally, the paper does not explore the impact of CKG on other downstream tasks beyond link prediction, such as entity classification or knowledge graph completion.
Furthermore, the paper does not provide a theoretical analysis of why the cropping module improves the robustness of the learned embeddings. It would be helpful to understand the underlying mechanisms that enable CKG to outperform other methods when the embeddings are cropped.
Despite these limitations, the CKG method represents an interesting and potentially useful contribution to the field of knowledge graph embedding. By incorporating a cropping mechanism into the training process, the researchers have shown that it is possible to learn embeddings that are more resilient to size reduction, which could be valuable in applications with limited computational resources or storage constraints.
Conclusion
This paper introduces a novel knowledge graph embedding method called "Croppable Knowledge Graph Embedding" (CKG) that learns embeddings that can be effectively cropped or reduced in size while maintaining performance on downstream tasks. The key innovation is the incorporation of a cropping module during the training process, which encourages the model to learn embeddings that are robust to cropping.
Experimental results on several benchmark datasets demonstrate that CKG outperforms state-of-the-art knowledge graph embedding methods, especially when the embeddings are cropped or reduced in size. This makes CKG particularly useful for applications where storage space or computational resources are limited, but high-performing knowledge graph embeddings are still required.
While the paper has some limitations, such as the sensitivity to hyperparameters and the lack of a theoretical analysis, the CKG method represents an important step forward in the field of knowledge graph embedding. By addressing the challenge of embedding size reduction, the researchers have opened up new possibilities for the practical application of knowledge graph technologies in resource-constrained environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Croppable Knowledge Graph Embedding
Yushan Zhu, Wen Zhang, Zhiqiang Liu, Mingyang Chen, Lei Liang, Huajun Chen
Knowledge Graph Embedding (KGE) is a common method for Knowledge Graphs (KGs) to serve various artificial intelligence tasks. The suitable dimensions of the embeddings depend on the storage and computing conditions of the specific application scenarios. Once a new dimension is required, a new KGE model needs to be trained from scratch, which greatly increases the training cost and limits the efficiency and flexibility of KGE in serving various scenarios. In this work, we propose a novel KGE training framework MED, through which we could train once to get a croppable KGE model applicable to multiple scenarios with different dimensional requirements, sub-models of the required dimensions can be cropped out of it and used directly without any additional training. In MED, we propose a mutual learning mechanism to improve the low-dimensional sub-models performance and make the high-dimensional sub-models retain the capacity that low-dimensional sub-models have, an evolutionary improvement mechanism to promote the high-dimensional sub-models to master the knowledge that the low-dimensional sub-models can not learn, and a dynamic loss weight to balance the multiple losses adaptively. Experiments on 3 KGE models over 4 standard KG completion datasets, 3 real application scenarios over a real-world large-scale KG, and the experiments of extending MED to the language model BERT show the effectiveness, high efficiency, and flexible extensibility of MED.
Read more7/4/2024
👁️
0
Confidence-aware Self-Semantic Distillation on Knowledge Graph Embedding
Yichen Liu, Jiawei Chen, Defang Chen, Zhehui Zhou, Yan Feng, Can Wang
Knowledge Graph Embedding (KGE), which projects entities and relations into continuous vector spaces, have garnered significant attention. Although high-dimensional KGE methods offer better performance, they come at the expense of significant computation and memory overheads. Decreasing embedding dimensions significantly deteriorates model performance. While several recent efforts utilize knowledge distillation or non-Euclidean representation learning to augment the effectiveness of low-dimensional KGE, they either necessitate a pre-trained high-dimensional teacher model or involve complex non-Euclidean operations, thereby incurring considerable additional computational costs. To address this, this work proposes Confidence-aware Self-Knowledge Distillation (CSD) that learns from model itself to enhance KGE in a low-dimensional space. Specifically, CSD extracts knowledge from embeddings in previous iterations, which would be utilized to supervise the learning of the model in the next iterations. Moreover, a specific semantic module is developed to filter reliable knowledge by estimating the confidence of previously learned embeddings. This straightforward strategy bypasses the need for time-consuming pre-training of teacher models and can be integrated into various KGE methods to improve their performance. Our comprehensive experiments on six KGE backbones and four datasets underscore the effectiveness of the proposed CSD.
Read more5/28/2024
🏷️
0
Low-Dimensional Federated Knowledge Graph Embedding via Knowledge Distillation
Xiaoxiong Zhang, Zhiwei Zeng, Xin Zhou, Zhiqi Shen
Federated Knowledge Graph Embedding (FKGE) aims to facilitate collaborative learning of entity and relation embeddings from distributed Knowledge Graphs (KGs) across multiple clients, while preserving data privacy. Training FKGE models with higher dimensions is typically favored due to their potential for achieving superior performance. However, high-dimensional embeddings present significant challenges in terms of storage resource and inference speed. Unlike traditional KG embedding methods, FKGE involves multiple client-server communication rounds, where communication efficiency is critical. Existing embedding compression methods for traditional KGs may not be directly applicable to FKGE as they often require multiple model trainings which potentially incur substantial communication costs. In this paper, we propose a light-weight component based on Knowledge Distillation (KD) which is titled FedKD and tailored specifically for FKGE methods. During client-side local training, FedKD facilitates the low-dimensional student model to mimic the score distribution of triples from the high-dimensional teacher model using KL divergence loss. Unlike traditional KD way, FedKD adaptively learns a temperature to scale the score of positive triples and separately adjusts the scores of corresponding negative triples using a predefined temperature, thereby mitigating teacher over-confidence issue. Furthermore, we dynamically adjust the weight of KD loss to optimize the training process. Extensive experiments on three datasets support the effectiveness of FedKD.
Read more8/13/2024
0
On The Expressive Power of Knowledge Graph Embedding Methods
Jiexing Gao, Dmitry Rodin, Vasily Motolygin, Denis Zaytsev
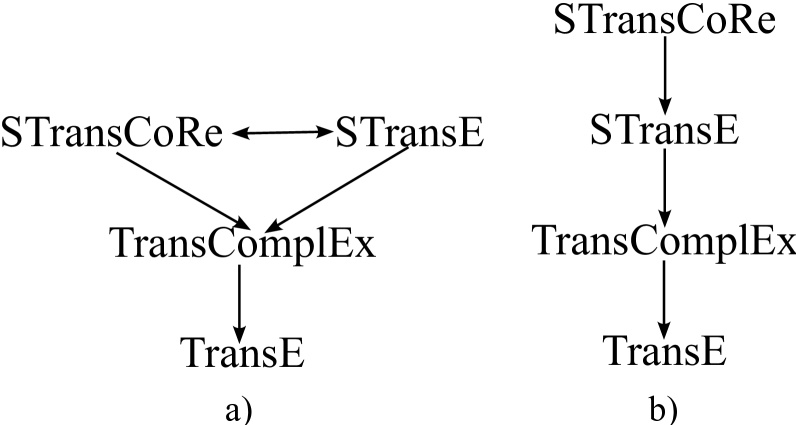
Knowledge Graph Embedding (KGE) is a popular approach, which aims to represent entities and relations of a knowledge graph in latent spaces. Their representations are known as embeddings. To measure the plausibility of triplets, score functions are defined over embedding spaces. Despite wide dissemination of KGE in various tasks, KGE methods have limitations in reasoning abilities. In this paper we propose a mathematical framework to compare reasoning abilities of KGE methods. We show that STransE has a higher capability than TransComplEx, and then present new STransCoRe method, which improves the STransE by combining it with the TransCoRe insights, which can reduce the STransE space complexity.
Read more7/29/2024