CLAIM Your Data: Enhancing Imputation Accuracy with Contextual Large Language Models

0
🎯
Sign in to get full access
Overview
- This paper presents a technical appendix with additional details about the dataset and missing-value descriptors used in the research.
- The appendix provides a summary of the dataset and explains how missing values were handled in the analysis.
Plain English Explanation
The research paper this appendix is attached to likely explored some complex topic using data analysis. To provide more context for readers, the authors have included this supplementary information.
The Dataset Summary section gives an overview of the data used in the study. This helps readers understand the type and scale of the information the researchers worked with.
The Missing-value Descriptors section explains how the researchers handled any gaps or missing data points in the dataset. This is an important consideration, as missing data can impact the reliability of the analysis.
By including this additional technical detail, the authors are giving readers a more complete picture of their research methods and the data foundation upon which their findings are based.
Technical Explanation
Dataset Summary
This section provides a high-level summary of the dataset used in the research. It likely describes the number of samples, features, and any other key statistics about the data.
Missing-value Descriptors
This section explains how the researchers dealt with missing values in the dataset. It may discuss techniques like imputation, where missing data is estimated based on patterns in the available information. Or it could outline how samples with missing values were excluded from the analysis.
Critical Analysis
The appendix provides helpful context about the data, but does not contain any substantive research findings or analysis. As such, there is little to critically evaluate here. The main focus would be on assessing the rigor and appropriateness of the data processing methods described.
One area for further exploration could be understanding the potential impact of the missing data handling approach on the reliability of the study's conclusions. The researchers may want to explore the sensitivity of their results to different missing data techniques.
Conclusion
This appendix serves to transparently document the dataset and data cleaning procedures used in the core research. By providing these technical details, the authors are enabling readers to better evaluate the foundations of their work. This level of methodological disclosure is an important part of robust, reproducible science.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
0
CLAIM Your Data: Enhancing Imputation Accuracy with Contextual Large Language Models
Ahatsham Hayat, Mohammad Rashedul Hasan
This paper introduces the Contextual Language model for Accurate Imputation Method (CLAIM), a novel strategy that capitalizes on the expansive knowledge and reasoning capabilities of pre-trained large language models (LLMs) to address missing data challenges in tabular datasets. Unlike traditional imputation methods, which predominantly rely on numerical estimations, CLAIM utilizes contextually relevant natural language descriptors to fill missing values. This approach transforms datasets into natural language contextualized formats that are inherently more aligned with LLMs' capabilities, thereby facilitating the dual use of LLMs: first, to generate missing value descriptors, and then, to fine-tune the LLM on the enriched dataset for improved performance in downstream tasks. Our evaluations across diverse datasets and missingness patterns reveal CLAIM's superior performance over existing imputation techniques. Furthermore, our investigation into the effectiveness of context-specific versus generic descriptors for missing data highlights the importance of contextual accuracy in enhancing LLM performance for data imputation. The results underscore CLAIM's potential to markedly improve the reliability and quality of data analysis and machine learning models, offering a more nuanced and effective solution for handling missing data.
Read more5/29/2024
0
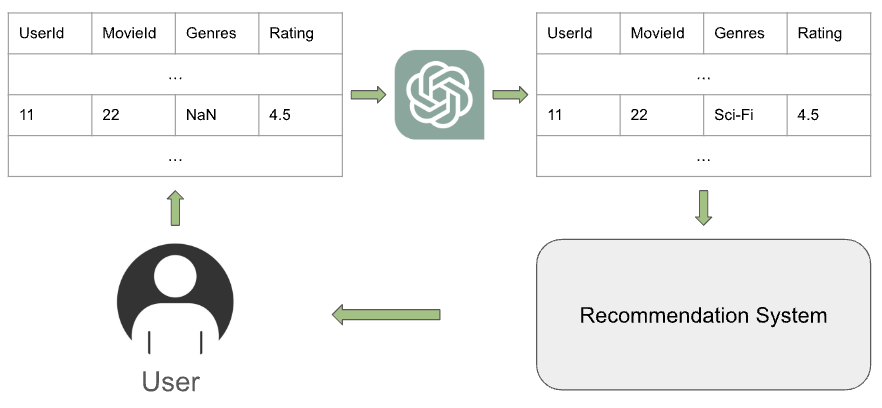
Semantic Understanding and Data Imputation using Large Language Model to Accelerate Recommendation System
Zhicheng Ding, Jiahao Tian, Zhenkai Wang, Jinman Zhao, Siyang Li
This paper aims to address the challenge of sparse and missing data in recommendation systems, a significant hurdle in the age of big data. Traditional imputation methods struggle to capture complex relationships within the data. We propose a novel approach that fine-tune Large Language Model (LLM) and use it impute missing data for recommendation systems. LLM which is trained on vast amounts of text, is able to understand complex relationship among data and intelligently fill in missing information. This enriched data is then used by the recommendation system to generate more accurate and personalized suggestions, ultimately enhancing the user experience. We evaluate our LLM-based imputation method across various tasks within the recommendation system domain, including single classification, multi-classification, and regression compared to traditional data imputation methods. By demonstrating the superiority of LLM imputation over traditional methods, we establish its potential for improving recommendation system performance.
Read more7/16/2024

0
Claim Verification in the Age of Large Language Models: A Survey
Alphaeus Dmonte, Roland Oruche, Marcos Zampieri, Prasad Calyam, Isabelle Augenstein
The large and ever-increasing amount of data available on the Internet coupled with the laborious task of manual claim and fact verification has sparked the interest in the development of automated claim verification systems. Several deep learning and transformer-based models have been proposed for this task over the years. With the introduction of Large Language Models (LLMs) and their superior performance in several NLP tasks, we have seen a surge of LLM-based approaches to claim verification along with the use of novel methods such as Retrieval Augmented Generation (RAG). In this survey, we present a comprehensive account of recent claim verification frameworks using LLMs. We describe the different components of the claim verification pipeline used in these frameworks in detail including common approaches to retrieval, prompting, and fine-tuning. Finally, we describe publicly available English datasets created for this task.
Read more8/27/2024
💬
0
Unleashing the Potential of Large Language Models for Predictive Tabular Tasks in Data Science
Yazheng Yang, Yuqi Wang, Sankalok Sen, Lei Li, Qi Liu
In the domain of data science, the predictive tasks of classification, regression, and imputation of missing values are commonly encountered challenges associated with tabular data. This research endeavors to apply Large Language Models (LLMs) towards addressing these predictive tasks. Despite their proficiency in comprehending natural language, LLMs fall short in dealing with structured tabular data. This limitation stems from their lacking exposure to the intricacies of tabular data during their foundational training. Our research aims to mitigate this gap by compiling a comprehensive corpus of tables annotated with instructions and executing large-scale training of Llama-2 on this enriched dataset. Furthermore, we investigate the practical application of applying the trained model to zero-shot prediction, few-shot prediction, and in-context learning scenarios. Through extensive experiments, our methodology has shown significant improvements over existing benchmarks. These advancements highlight the efficacy of tailoring LLM training to solve table-related problems in data science, thereby establishing a new benchmark in the utilization of LLMs for enhancing tabular intelligence.
Read more4/9/2024