Classification with Deep Neural Networks and Logistic Loss
2307.16792
0
0
🏷️
Abstract
Deep neural networks (DNNs) trained with the logistic loss (i.e., the cross entropy loss) have made impressive advancements in various binary classification tasks. However, generalization analysis for binary classification with DNNs and logistic loss remains scarce. The unboundedness of the target function for the logistic loss is the main obstacle to deriving satisfactory generalization bounds. In this paper, we aim to fill this gap by establishing a novel and elegant oracle-type inequality, which enables us to deal with the boundedness restriction of the target function, and using it to derive sharp convergence rates for fully connected ReLU DNN classifiers trained with logistic loss. In particular, we obtain optimal convergence rates (up to log factors) only requiring the Holder smoothness of the conditional class probability $eta$ of data. Moreover, we consider a compositional assumption that requires $eta$ to be the composition of several vector-valued functions of which each component function is either a maximum value function or a Holder smooth function only depending on a small number of its input variables. Under this assumption, we derive optimal convergence rates (up to log factors) which are independent of the input dimension of data. This result explains why DNN classifiers can perform well in practical high-dimensional classification problems. Besides the novel oracle-type inequality, the sharp convergence rates given in our paper also owe to a tight error bound for approximating the natural logarithm function near zero (where it is unbounded) by ReLU DNNs. In addition, we justify our claims for the optimality of rates by proving corresponding minimax lower bounds. All these results are new in the literature and will deepen our theoretical understanding of classification with DNNs.
Create account to get full access
Overview
- This paper explores the problem of binary classification using deep neural networks (DNNs) trained with the logistic loss (cross-entropy loss).
- The authors aim to establish a novel "oracle-type inequality" to address the unboundedness of the logistic loss function, which has been a major obstacle in deriving satisfactory generalization bounds for DNN classifiers.
- The paper presents sharp convergence rates for fully connected ReLU DNN classifiers trained with logistic loss, under different assumptions about the smoothness of the conditional class probability function.
- The authors also prove corresponding minimax lower bounds to justify the optimality of their derived convergence rates.
Plain English Explanation
Deep neural networks (DNNs) have made impressive advancements in various binary classification tasks when trained with the logistic loss (also known as cross-entropy loss). [Logistic loss is a common loss function used to train DNN classifiers.] However, understanding how well these DNN classifiers can generalize to new data has been challenging, as the logistic loss function is unbounded, making it difficult to derive satisfactory generalization bounds.
In this paper, the researchers tackle this problem by developing a novel "oracle-type inequality." This inequality allows them to deal with the unboundedness of the logistic loss and derive sharp convergence rates for DNN classifiers trained with this loss function. [The convergence rate is a measure of how quickly the model's performance improves as the amount of training data increases.]
The researchers consider two main assumptions about the smoothness of the underlying conditional class probability function. Under the first assumption, they show that their DNN classifiers can achieve optimal convergence rates (up to logarithmic factors) based solely on the Hölder smoothness of the conditional class probability. [Hölder smoothness is a measure of how "smooth" a function is.]
Under a more specific compositional assumption, the researchers show that their DNN classifiers can achieve even faster convergence rates that are independent of the input dimension of the data. This helps explain why DNN classifiers can perform well in practical high-dimensional classification problems.
In addition to the novel oracle-type inequality, the sharp convergence rates presented in this paper also rely on a tight error bound for approximating the natural logarithm function (a key component of the logistic loss) near zero, where it is unbounded.
The researchers also prove corresponding minimax lower bounds, which justify the optimality of the convergence rates they derive. [Minimax lower bounds provide a theoretical limit on the best possible performance that any algorithm can achieve for a given problem.]
Overall, this paper makes important theoretical advances in understanding the generalization capabilities of DNN classifiers trained with the logistic loss, which is widely used in practice.
Technical Explanation
The key technical contributions of this paper are:
-
Novel Oracle-Type Inequality: The authors derive a novel oracle-type inequality that allows them to deal with the unboundedness of the logistic loss function, which has been a major obstacle in establishing satisfactory generalization bounds for DNN classifiers.
-
Sharper Convergence Rates: Using the oracle-type inequality, the authors derive sharp convergence rates for fully connected ReLU DNN classifiers trained with logistic loss. These rates are optimal (up to logarithmic factors) and only require the Hölder smoothness of the conditional class probability function [link to https://aimodels.fyi/papers/arxiv/rates-convergence-learning-convolutional-neural-networks].
-
Compositional Assumption: Under a compositional assumption, where the conditional class probability function is the composition of several vector-valued functions, the authors derive even faster convergence rates that are independent of the input dimension of the data. This helps explain the empirical success of DNN classifiers in high-dimensional settings [link to https://aimodels.fyi/papers/arxiv/information-theoretic-generalization-bounds-deep-neural-networks].
-
Tight Error Bound for Log Approximation: The authors establish a tight error bound for approximating the natural logarithm function (a key component of the logistic loss) near zero, where it is unbounded, using ReLU DNNs. This technical contribution is crucial for obtaining the sharp convergence rates.
-
Minimax Lower Bounds: The authors prove corresponding minimax lower bounds to justify the optimality of the convergence rates they derive [link to https://aimodels.fyi/papers/arxiv/diffusion-based-generative-models-their-error-bounds, https://aimodels.fyi/papers/arxiv/deep-learning-as-ricci-flow, https://aimodels.fyi/papers/arxiv/convergence-result-continuous-model-deep-learning-via].
Critical Analysis
The paper presents a rigorous theoretical analysis of the generalization properties of DNN classifiers trained with the logistic loss. The authors' novel oracle-type inequality and the resulting sharp convergence rates are important contributions that advance our understanding of DNN classifiers.
One potential limitation of the work is that the analysis is restricted to fully connected ReLU DNNs. It would be interesting to see if the authors' techniques can be extended to other DNN architectures, such as convolutional neural networks, which are widely used in practice.
Additionally, the compositional assumption made in the paper, while providing fast convergence rates that are independent of input dimension, may not always hold in real-world classification problems. Investigating the practical implications and relaxing this assumption could be a valuable direction for future research.
Overall, this paper provides valuable insights and establishes a strong theoretical foundation for understanding the generalization capabilities of DNN classifiers trained with the logistic loss. The results presented here will likely spur further research in this important area of machine learning.
Conclusion
This paper makes significant theoretical advancements in the understanding of binary classification using deep neural networks (DNNs) trained with the logistic loss. The authors' novel oracle-type inequality and the sharp convergence rates they derive, under different assumptions about the smoothness of the underlying conditional class probability function, offer a deeper insight into the generalization properties of these widely-used DNN classifiers.
The results presented in this paper not only advance the theoretical understanding of DNN classifiers but also have the potential to inform the design and optimization of such models in practical high-dimensional classification problems. The authors' work lays a solid foundation for further research in this area, which is crucial for the continued success and responsible deployment of deep learning techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Error Bounds of Supervised Classification from Information-Theoretic Perspective
Binchuan Qi, Wei Gong, Li Li
0
0
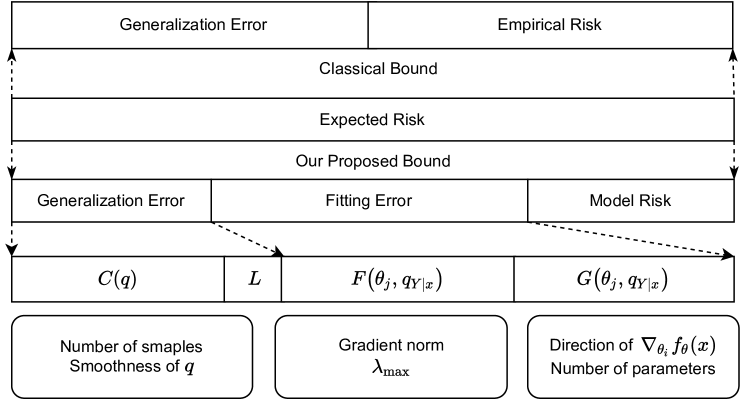
There remains a list of unanswered research questions on deep learning (DL), including the remarkable generalization power of overparametrized neural networks, the efficient optimization performance despite the non-convexity, and the mechanisms behind flat minima in generalization. In this paper, we adopt an information-theoretic perspective to explore the theoretical foundations of supervised classification using deep neural networks (DNNs). Our analysis introduces the concepts of fitting error and model risk, which, together with generalization error, constitute an upper bound on the expected risk. We demonstrate that the generalization errors are bounded by the complexity, influenced by both the smoothness of distribution and the sample size. Consequently, task complexity serves as a reliable indicator of the dataset's quality, guiding the setting of regularization hyperparameters. Furthermore, the derived upper bound fitting error links the back-propagated gradient, Neural Tangent Kernel (NTK), and the model's parameter count with the fitting error. Utilizing the triangle inequality, we establish an upper bound on the expected risk. This bound offers valuable insights into the effects of overparameterization, non-convex optimization, and the flat minima in DNNs.Finally, empirical verification confirms a significant positive correlation between the derived theoretical bounds and the practical expected risk, confirming the practical relevance of the theoretical findings.
6/28/2024
🧠
On the rates of convergence for learning with convolutional neural networks
Yunfei Yang, Han Feng, Ding-Xuan Zhou
0
0
We study approximation and learning capacities of convolutional neural networks (CNNs) with one-side zero-padding and multiple channels. Our first result proves a new approximation bound for CNNs with certain constraint on the weights. Our second result gives new analysis on the covering number of feed-forward neural networks with CNNs as special cases. The analysis carefully takes into account the size of the weights and hence gives better bounds than the existing literature in some situations. Using these two results, we are able to derive rates of convergence for estimators based on CNNs in many learning problems. In particular, we establish minimax optimal convergence rates of the least squares based on CNNs for learning smooth functions in the nonparametric regression setting. For binary classification, we derive convergence rates for CNN classifiers with hinge loss and logistic loss. It is also shown that the obtained rates for classification are minimax optimal in some common settings.
4/10/2024

A Margin-based Multiclass Generalization Bound via Geometric Complexity
Michael Munn, Benoit Dherin, Javier Gonzalvo
0
0
There has been considerable effort to better understand the generalization capabilities of deep neural networks both as a means to unlock a theoretical understanding of their success as well as providing directions for further improvements. In this paper, we investigate margin-based multiclass generalization bounds for neural networks which rely on a recent complexity measure, the geometric complexity, developed for neural networks. We derive a new upper bound on the generalization error which scales with the margin-normalized geometric complexity of the network and which holds for a broad family of data distributions and model classes. Our generalization bound is empirically investigated for a ResNet-18 model trained with SGD on the CIFAR-10 and CIFAR-100 datasets with both original and random labels.
5/30/2024
Neural Collapse for Cross-entropy Class-Imbalanced Learning with Unconstrained ReLU Feature Model
Hien Dang, Tho Tran, Tan Nguyen, Nhat Ho
0
0
The current paradigm of training deep neural networks for classification tasks includes minimizing the empirical risk that pushes the training loss value towards zero, even after the training error has been vanished. In this terminal phase of training, it has been observed that the last-layer features collapse to their class-means and these class-means converge to the vertices of a simplex Equiangular Tight Frame (ETF). This phenomenon is termed as Neural Collapse (NC). To theoretically understand this phenomenon, recent works employ a simplified unconstrained feature model to prove that NC emerges at the global solutions of the training problem. However, when the training dataset is class-imbalanced, some NC properties will no longer be true. For example, the class-means geometry will skew away from the simplex ETF when the loss converges. In this paper, we generalize NC to imbalanced regime for cross-entropy loss under the unconstrained ReLU feature model. We prove that, while the within-class features collapse property still holds in this setting, the class-means will converge to a structure consisting of orthogonal vectors with different lengths. Furthermore, we find that the classifier weights are aligned to the scaled and centered class-means with scaling factors depend on the number of training samples of each class, which generalizes NC in the class-balanced setting. We empirically prove our results through experiments on practical architectures and dataset.
6/7/2024