A Margin-based Multiclass Generalization Bound via Geometric Complexity
2405.18590
0
0

Abstract
There has been considerable effort to better understand the generalization capabilities of deep neural networks both as a means to unlock a theoretical understanding of their success as well as providing directions for further improvements. In this paper, we investigate margin-based multiclass generalization bounds for neural networks which rely on a recent complexity measure, the geometric complexity, developed for neural networks. We derive a new upper bound on the generalization error which scales with the margin-normalized geometric complexity of the network and which holds for a broad family of data distributions and model classes. Our generalization bound is empirically investigated for a ResNet-18 model trained with SGD on the CIFAR-10 and CIFAR-100 datasets with both original and random labels.
Create account to get full access
Overview
- Proposes a new margin-based generalization bound for multiclass classification problems in deep learning
- Introduces a concept called "geometric complexity" to measure the complexity of the classifier
- Demonstrates that the proposed bound can be tighter than existing bounds, especially for deep neural networks
Plain English Explanation
This research paper presents a new way to measure how well a deep learning model can generalize, or perform on new data it hasn't seen before, for multiclass classification problems. The key idea is to introduce a new concept called "geometric complexity" that captures the complexity of the classifier, in addition to the traditional notion of margin.
The margin is a measure of how confidently the model can distinguish between different classes. A larger margin generally indicates better generalization. However, the researchers argue that the geometric complexity of the classifier, which reflects the intricate shape of the decision boundaries, is also an important factor in determining generalization. By incorporating both margin and geometric complexity, the new generalization bound they derive can be tighter, especially for deep neural networks, which can have very complex decision boundaries.
The paper provides a mathematical analysis to show that this new bound can indeed be tighter than existing bounds. This suggests that the geometric complexity of the classifier is an important consideration when analyzing the generalization capabilities of deep learning models, beyond just looking at the margin.
Technical Explanation
The paper proposes a new margin-based generalization bound for multiclass classification problems, building on previous work on margin-based generalization bounds and generalization analysis of deep ReLU networks.
The key innovation is the introduction of a new complexity measure called "geometric complexity," which captures the intricate shape of the decision boundaries learned by the classifier. This is in addition to the traditional notion of margin, which measures how confidently the model can distinguish between different classes.
Formally, the paper derives a generalization bound that depends on both the margin and the geometric complexity. The geometric complexity is defined using tools from differential geometry, specifically the concept of Riemannian curvature. The authors show that this new bound can be tighter than existing bounds, especially for deep neural networks, which can have very complex decision boundaries.
The paper also provides an experimental evaluation, comparing the proposed bound to existing bounds on both synthetic and real-world datasets. The results demonstrate that the new bound can indeed be tighter, particularly for deep neural networks trained with the logistic loss, which is a common loss function used in practice.
Critical Analysis
The paper makes a compelling case for the importance of considering geometric complexity when analyzing the generalization capabilities of deep learning models. The proposed bound provides a more comprehensive measure of complexity that goes beyond just the margin, which is a valuable contribution to the learning theory literature.
However, the paper does not address some potential limitations of the approach. For example, the geometric complexity measure relies on the availability of the classifier's decision boundaries, which may not be easily accessible in practice, especially for very deep or complex models. Additionally, the theoretical analysis assumes certain smoothness and regularity conditions on the decision boundaries, which may not always hold in real-world scenarios.
Furthermore, while the experimental results are promising, the paper could have provided a more thorough exploration of the practical implications and potential use cases of the proposed bound. It would be interesting to see how the bound performs in different application domains, or how it could be used to guide the design and training of deep learning models.
Conclusion
This research paper introduces a new margin-based generalization bound for multiclass classification problems in deep learning, which takes into account the geometric complexity of the classifier's decision boundaries. The authors demonstrate that this new bound can be tighter than existing bounds, particularly for deep neural networks with complex decision boundaries.
The key contribution of this work is the recognition that the geometric complexity of the classifier is an important factor in determining its generalization capabilities, beyond just the margin. This suggests that future research in deep learning theory should consider not just the margin, but also the underlying geometry of the decision boundaries learned by the model.
Overall, this paper provides a valuable theoretical framework for understanding the generalization properties of deep learning models and opens up new avenues for further research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
On margin-based generalization prediction in deep neural networks
Coenraad Mouton
0
0
Understanding generalization in deep neural networks is an active area of research. A promising avenue of exploration has been that of margin measurements: the shortest distance to the decision boundary for a given sample or that sample's representation internal to the network. Margin-based complexity measures have been shown to be correlated with the generalization ability of deep neural networks in some circumstances but not others. The reasons behind the success or failure of these metrics are currently unclear. In this study, we examine margin-based generalization prediction methods in different settings. We motivate why these metrics sometimes fail to accurately predict generalization and how they can be improved. First, we analyze the relationship between margins measured in the input space and sample noise. We find that different types of sample noise can have a very different effect on the overall margin of a network that has modeled noisy data. Following this, we empirically evaluate how robust margins measured at different representational spaces are at predicting generalization. We find that these metrics have several limitations and that a large margin does not exhibit a strong correlation with empirical risk in many cases. Finally, we introduce a new margin-based measure that incorporates an approximation of the underlying data manifold. It is empirically demonstrated that this measure is generally more predictive of generalization than all other margin-based measures. Furthermore, we find that this measurement also outperforms other contemporary complexity measures on a well-known generalization prediction benchmark. In addition, we analyze the utility and limitations of this approach and find that this metric is well aligned with intuitions expressed in prior work.
5/29/2024
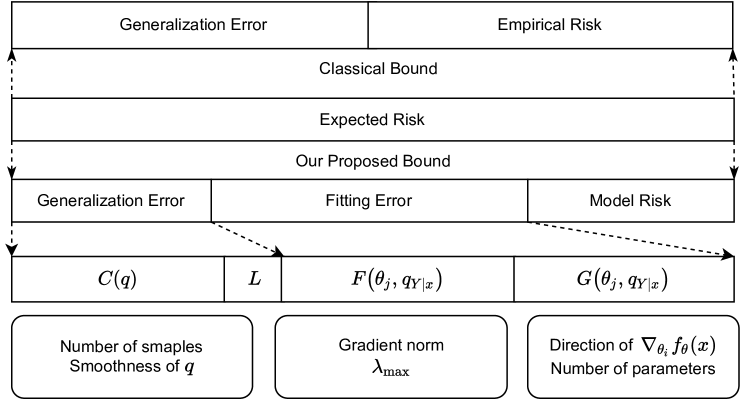
Error Bounds of Supervised Classification from Information-Theoretic Perspective
Binchuan Qi, Wei Gong, Li Li
0
0
There remains a list of unanswered research questions on deep learning (DL), including the remarkable generalization power of overparametrized neural networks, the efficient optimization performance despite the non-convexity, and the mechanisms behind flat minima in generalization. In this paper, we adopt an information-theoretic perspective to explore the theoretical foundations of supervised classification using deep neural networks (DNNs). Our analysis introduces the concepts of fitting error and model risk, which, together with generalization error, constitute an upper bound on the expected risk. We demonstrate that the generalization errors are bounded by the complexity, influenced by both the smoothness of distribution and the sample size. Consequently, task complexity serves as a reliable indicator of the dataset's quality, guiding the setting of regularization hyperparameters. Furthermore, the derived upper bound fitting error links the back-propagated gradient, Neural Tangent Kernel (NTK), and the model's parameter count with the fitting error. Utilizing the triangle inequality, we establish an upper bound on the expected risk. This bound offers valuable insights into the effects of overparameterization, non-convex optimization, and the flat minima in DNNs.Finally, empirical verification confirms a significant positive correlation between the derived theoretical bounds and the practical expected risk, confirming the practical relevance of the theoretical findings.
6/28/2024
🏷️
Classification with Deep Neural Networks and Logistic Loss
Zihan Zhang, Lei Shi, Ding-Xuan Zhou
0
0
Deep neural networks (DNNs) trained with the logistic loss (i.e., the cross entropy loss) have made impressive advancements in various binary classification tasks. However, generalization analysis for binary classification with DNNs and logistic loss remains scarce. The unboundedness of the target function for the logistic loss is the main obstacle to deriving satisfactory generalization bounds. In this paper, we aim to fill this gap by establishing a novel and elegant oracle-type inequality, which enables us to deal with the boundedness restriction of the target function, and using it to derive sharp convergence rates for fully connected ReLU DNN classifiers trained with logistic loss. In particular, we obtain optimal convergence rates (up to log factors) only requiring the Holder smoothness of the conditional class probability $eta$ of data. Moreover, we consider a compositional assumption that requires $eta$ to be the composition of several vector-valued functions of which each component function is either a maximum value function or a Holder smooth function only depending on a small number of its input variables. Under this assumption, we derive optimal convergence rates (up to log factors) which are independent of the input dimension of data. This result explains why DNN classifiers can perform well in practical high-dimensional classification problems. Besides the novel oracle-type inequality, the sharp convergence rates given in our paper also owe to a tight error bound for approximating the natural logarithm function near zero (where it is unbounded) by ReLU DNNs. In addition, we justify our claims for the optimality of rates by proving corresponding minimax lower bounds. All these results are new in the literature and will deepen our theoretical understanding of classification with DNNs.
4/23/2024

Large Margin Discriminative Loss for Classification
Hai-Vy Nguyen, Fabrice Gamboa, Sixin Zhang, Reda Chhaibi, Serge Gratton, Thierry Giaccone
0
0
In this paper, we introduce a novel discriminative loss function with large margin in the context of Deep Learning. This loss boosts the discriminative power of neural nets, represented by intra-class compactness and inter-class separability. On the one hand, the class compactness is ensured by close distance of samples of the same class to each other. On the other hand, the inter-class separability is boosted by a margin loss that ensures the minimum distance of each class to its closest boundary. All the terms in our loss have an explicit meaning, giving a direct view of the feature space obtained. We analyze mathematically the relation between compactness and margin term, giving a guideline about the impact of the hyper-parameters on the learned features. Moreover, we also analyze properties of the gradient of the loss with respect to the parameters of the neural net. Based on this, we design a strategy called partial momentum updating that enjoys simultaneously stability and consistency in training. Furthermore, we also investigate generalization errors to have better theoretical insights. Our loss function systematically boosts the test accuracy of models compared to the standard softmax loss in our experiments.
5/30/2024